
A Beginner’s Guide to Panoptic Segmentation
Table of contents
Share blog post



Panoptic segmentation unifies semantic and instance tasks by assigning each pixel a class label and an instance ID, producing a full scene map. Models fuse semantic and instance branches, resolve overlaps, and power autonomy, medical imaging, AR, and surveillance.
Share blog post
Here is everything you need to know about panoptic segmentation:
What is panoptic segmentation?
Panoptic segmentation merges semantic and instance segmentation. It assigns each pixel both a semantic class and an instance ID, providing a complete view of a scene. The term "Panoptic" means "seeing everything," covering both objects ("things") and background areas ("stuff").
How is panoptic segmentation different from semantic or instance segmentation?
Semantic segmentation classifies pixels by category but doesn’t distinguish individual instances. Instance segmentation identifies distinct objects but typically ignores background regions.
Panoptic segmentation merges both methods. Each pixel gets a semantic label (road, car, person) and a unique identifier for each object. It creates one segmentation mask for objects and another for background regions.
Why is panoptic segmentation important?
Panoptic segmentation provides pixel-level detail, which is valuable for real-world computer vision. It helps to identify individual objects and their context in a single output.
This improves scene interpretation in applications such as autonomous vehicles (object detection and drivable space) and medical imaging (distinguishing overlapping cells for diagnosis).
How does panoptic segmentation work?
Panoptic segmentation models use two sub-networks, one for semantic segmentation, such as a Fully Convolutional Network (FCN), and another for instance segmentation, like Mask R-CNN.
A shared backbone processes multi-scale features, then a fusion module combines both outputs. Overlaps are resolved during post-processing to ensure each pixel gets one class+instance label.
The result is a segmentation map with unique object IDs and uniform background labels.
What are the use cases of panoptic segmentation?
Panoptic segmentation is used in autonomous driving to segment roads, vehicles, and pedestrians. It is used in medical imaging for organ or cell segmentation, in augmented reality for camera portrait mode, and in surveillance for crowd tracking, among other uses.
We started teaching machines to name an entire image (classification). Then we taught them to find objects in the image (object detection) and to understand every single pixel (image segmentation).
But image segmentation itself has different flavors, and one of them is panoptic segmentation.
In this guide, we'll walk you through everything you need to know about the panoptic image segmentation technique.
We will cover:
- What is panoptic segmentation
- How panoptic segmentation works (architecture & techniques)
- Datasets for panoptic segmentation
- Evaluation metrics: Measuring segmentation quality with PQ
- Applications of panoptic segmentation in the real world
- Curating high-quality data for panoptic segmentation with Lightly AI
Building accurate segmentation models starts with high-quality, well-curated data. Lightly AI provides tools and services that make this process faster and more efficient:
- LightlyStudio helps automatically curate diverse, balanced, and edge-case–rich image datasets from large unlabeled pools using active learning. This improves data efficiency and reduces labeling costs.
- LightlyTrain enables self-supervised pretraining for vision models on your unlabeled data, improving feature extraction and segmentation performance with minimal labeling effort.
Lightly GenAI Data Services extend these capabilities to multimodal and language models. The expert-led team supports dataset curation, prompt evaluation, bias detection, and data quality audits to help organizations build reliable, domain-specific GenAI systems that perform well in real-world conditions.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What is panoptic segmentation
Panoptic segmentation is a computer vision technique that unifies semantic and instance segmentation into a single task. It assigns every pixel in an image both a class label (what type of object or background it belongs to) and an instance ID (which specific object it is).
This dual labeling allows a model to understand a scene holistically, identifying individual objects like “car 1” and “car 2” while also labeling amorphous regions such as road, sky, or grass.
In practice, panoptic segmentation provides a complete scene understanding that’s crucial for real-world AI systems.
It’s widely used in autonomous driving, medical imaging, robotics, and augmented reality, where precise pixel-level differentiation between objects and context improves decision-making and spatial reasoning. By combining the strengths of both segmentation types, panoptic segmentation delivers a unified map that captures how all elements of a scene relate to one another.
💡Pro tip: For lightweight experimentation on segmentation models, our Apple M1 and M2 Performance for Training SSL Models article shows how SSL workloads run efficiently on consumer hardware.
Semantic vs. Instance vs. Panoptic Segmentation
Before we discuss the working of panoptic segmentation, let's first compare it with other related segmentation techniques.
Semantic segmentation techniques classify each pixel in a digital image into a specific category. They assign a unique class label to each pixel and group them into semantic categories such as person, car, or tree.

On the other hand, instance segmentation techniques go a step further by identifying the object's category and delineating its boundaries. They help find distinct object instances of the same class.

Panoptic segmentation uses the strengths of semantic and instance segmentation to assign both a semantic label and an instance ID to every pixel in the image.
Things are typically classified as individual object instances, while stuff is often a single continuous segment.
Previously, a computer vision system might have needed two separate models.
One handled “stuff” through semantic segmentation. On the other hand, the other managed “things” using instance segmentation.
Panoptic segmentation, however, enables a single model to offer a complete understanding of a visual scene.
Here’s a breakdown of how these three segmentation techniques compare:
How Panoptic Segmentation Works (Architecture & Techniques)
Many early methods first perform semantic and instance segmentation separately, and then combine the results into a single unified output.
Traditionally, a fully convolutional network (FCN) captures patterns from the objects (stuff) in the image. It uses skip connections to reconstruct accurate segmentation boundaries and make local predictions that define the object's global structure.
Mask R-CNN captures patterns of the countable objects (things) in the image. It yields instance segmentations for these objects.
The outputs of both the FCN and Mask R-CNN networks are combined to produce a panoptic segmentation result.

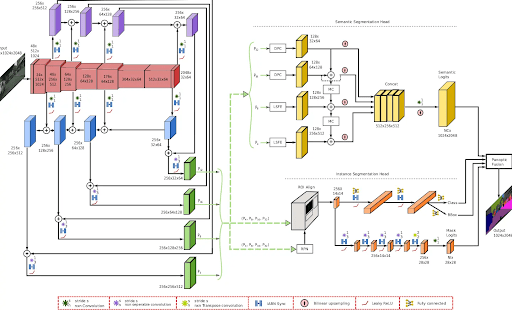
However, most modern panoptic segmentation architectures like EfficientPS combine two parallel networks (instance and semantic heads) that share a common backbone.
- Shared Backbone: The input image is fed into a deep CNN (or transformer) backbone that extracts feature maps. The backbone uses feature pyramid networks to get rich details from multiple scales.
- Semantic Segmentation Head: One branch of the network produces a semantic label for every pixel (covering stuff and things classes).
- Instance Segmentation Head: Another branch of the network focuses on detecting and delineating individual instances of objects.
- Panoptic Fusion Module: The outputs of the two heads are combined into a single panoptic fusion module to produce the final output. It often uses a non-maximum suppression step to ensure each pixel gets one, and only one, (class, instance) label.
The model uses a combined loss function from both heads to train this network.
The semantic head, which performs stuff classification, typically uses a pixel-wise loss like Cross-Entropy or Focal Loss. This loss compares the model's predicted 'stuff' map to the ground truth annotations and penalizes any incorrect semantic label for each pixel.
At the same time, the instance head has its own multi-part loss that penalizes the model for three separate errors. These include incorrectly classifying an object, drawing an inaccurate bounding box, and generating an erroneous segmentation mask.
The total loss for the panoptic segmentation architecture is the sum of all these individual losses. The model learns to perform both semantic and instance segmentation accurately in parallel by minimizing the total loss.
💡Pro tip: To reduce annotation effort in panoptic tasks, see how our Selecting the Most Typical Samples of Your Dataset article identifies high-value samples first.
Datasets for Panoptic Segmentation
Creating panoptic segmentation datasets is expensive and time-consuming because it requires annotators to label every pixel in an image with both a class and an instance ID. Also, high-quality ground truth annotations are critical for any machine learning model.
Some publicly accessible datasets provide high-quality ground-truth annotations for training a panoptic segmentation system.
A recommended dataset includes the COCO dataset. It is a widely used computer vision benchmark that has been expanded to include panoptic segmentation.
It provides over 118K training images across 133 categories (80 things, 53 stuff). An average of 7.7 different instances per image provides diverse training scenarios.

Next, we have Mapillary Vistas data, which contains street-level imagery collected worldwide for autonomous driving and street scene understanding. Vistas includes 25,000 high-resolution images with pixel-accurate panoptic labels.

Similarly, the Cityscapes panoptic dataset focused on understanding urban street scenes. It includes 5K finely annotated images and 20K coarsely annotated images, collected from 50 different European cities.

Additionally, the ADE20K Panoptic dataset (from a self-driving car in Germany) was released by MIT. It contains over 20K training images and 2K validation images, covering 150 semantic categories.
Compared to other datasets, ADE20K features diverse scene types (from indoor kitchens and bedrooms to outdoor mountains and beaches) that cover nearly all human environments.

Finally, the KITTI-360 dataset builds upon KITTI to support panoptic segmentation for autonomous driving research. It offers more than 300,000 laser scans along with detailed panoptic annotations.

Evaluation Metrics: Measuring Segmentation Quality with PQ
Evaluating panoptic segmentation requires an evaluation metric that assesses both semantic region classification and individual object instance detection.
Traditional semantic segmentation commonly uses Intersection over Union (IoU) and instance segmentation Average Precision (AP) metrics. However, these metrics are insufficient.
This is because IoU measures overlap but can't distinguish instances. AP evaluates detected instances but ignores "stuff".
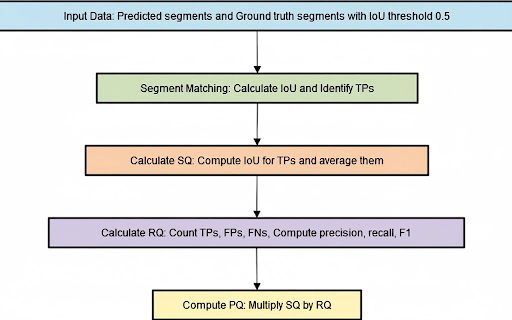
The Panoptic Quality (PQ) metric was built to fix these problems. The initial step in the PQ metric computation is segment matching. In this step, each predicted segment is matched to a ground-truth segment of the same class.
If their IoU is > 0.5, then a matchup is considered a “true positive”.

After segment matching, the PQ metric is calculated by evaluating Segmentation Quality (SQ) and Recognition Quality (RQ).
SQ measures the average Intersection over Union (IoU) of matched segments. It shows how well the predictions overlap with the ground truth.

Recognition quality assesses the F1 score of matched segments, balancing precision and recall.

Here, TP stands for true positives, FP for false positives, and FN for false negatives. The panoptic quality metric is then calculated as the product of these two components:
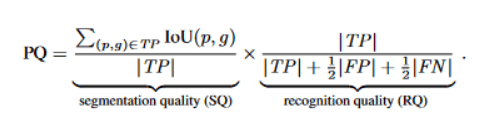
The formula encapsulates the components of the PQ metric. We can visualize the PQ computation process in the diagram below.
Applications of Panoptic Segmentation in the Real World
Panoptic segmentation has become a foundational technology for a wide range of real-world applications.
Its ability to identify objects and understand context allows pixel-level understanding (scene reasoning) that is impossible with other methods alone.
Autonomous Vehicles (Self-Driving Cars)
For a self-driving car to navigate safely, it must perceive and understand its surroundings. Panoptic segmentation is a crucial perception tool. It enables the car’s AI system to differentiate between vehicles, pedestrians, and road signs simultaneously and in real time.

Medical Imaging
In radiology and pathology, images (such as CT scans or microscope slides) are densely packed with information. Panoptic segmentation can help precisely segment organs, tissues, and anatomical structures.
For example, a panoptic model can analyze a pathology slide to segment and label each cell, giving each a unique identifier. It can also segment broader tissue regions, which helps doctors make accurate diagnoses.
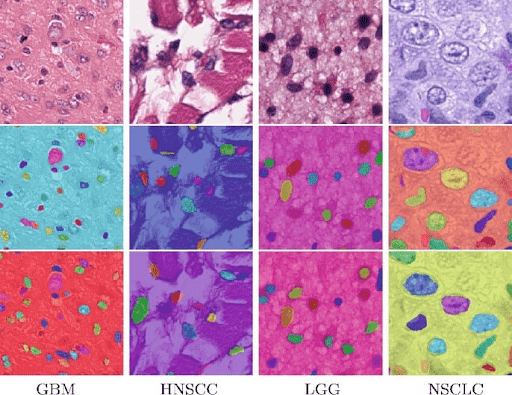
💡Pro tip: If you are working in the medical AI field, check out LightlyTrain Benchmarks for Histology: SSL Pretraining and Segmentation.
Augmented Reality (AR) and Photography
Creating realistic augmented reality (AR) experiences requires a deep understanding of the scene's geometry and composition.
Panoptic segmentation helps an AR system distinguish foreground objects from the background. This allows virtual elements to be placed in the scene in a way that looks natural and believable.
A common application is the portrait mode feature in smartphones. It uses segmentation to precisely separate a person from their background and apply an artistic blur effect.
Smart Cities and Surveillance
Panoptic segmentation helps interpret complex scenes captured by traffic and security cameras in urban environments.
For traffic management, a system can count and track individual vehicles and pedestrians ("things") while also analyzing the usage of roads, sidewalks, and intersections ("stuff").
This data can help optimize traffic flow to ensure pedestrian safety and monitor public spaces for security.

Remote Sensing and Satellite Imagery
Panoptic segmentation is used in the analysis of aerial and satellite images for environmental monitoring and urban planning. It can segment individual buildings and vehicles while also mapping broader land-use regions like forests, water bodies, and farmland.

Recent Advances and Research in Panoptic Segmentation
Since its introduction in 2018, panoptic segmentation has been an active research area. It has seen many improvements in algorithms and new ideas across several fronts.
The first strong baseline model for panoptic segmentation was the Panoptic Feature Pyramid Network (proposed by Kirillov). This "top-down" approach used an object detector like Mask R-CNN to find "things" and merged them with a semantic map for "stuff."
Its main limitation was complexity. It combined two models, and its performance relied on the quality of the initial object proposals.
To overcome this, Panoptic-DeepLab introduced a bottom-up, proposal-free method that uses center and offset predictions for efficient instance grouping.
The breakthrough came with Transformer-based models such as DETR, MaskFormer, and Panoptic SegFormer. These models use the attention mechanism to process the entire scene with global context.
They treat panoptic segmentation as a mask classification task, enabling more effective end-to-end training without complex post-processing.
Recent advances focus on efficiency and scalability, with models like EfficientPS prioritizing real-time performance on edge devices. Integrating foundation models like Meta’s Segment Anything Model (SAM) enables zero-shot segmentation, reducing reliance on annotated data.
💡Pro tip: If you are looking for the perfect data annotation tool or service, make sure to check out our list of 12 Best Data Annotation Tools for Computer Vision (Free & Paid) and 5 Best Data Annotation Companies in 2025.
Research has also expanded into 3D panoptic segmentation using LiDAR and video panoptic segmentation, which adds temporal consistency for tracking instances across frames. This opens new possibilities in understanding dynamic scenes.
Curating High-Quality Data for Panoptic Segmentation with Lightly AI
Training a panoptic segmentation model requires a large, diverse, annotated dataset. However, creating such datasets is costly and time-intensive, and not all data contributes equally to model performance.
Many datasets contain redundant or low-quality images that fail to enhance segmentation quality, wasting labeling and computational resources.
Lightly AI addresses this challenge and helps ML teams build better models by finding the right data to label and leveraging all unlabeled samples.
LightlyOne: The Data Curation Platform
LightlyOne helps you understand and select your data before you label it. Instead of labeling 100% of your data, with LightlyOne, you can find the 1% that matters most.
It works by turning your images into embeddings and can plot all your pictures on a 2D map to let you see your dataset's structure. You can instantly find clusters (e.g., "nighttime" vs. "daytime" images) or identify gaps (e.g., not enough "rainy" scenes).
Then you can easily find and remove exact duplicates or near-duplicates. This stops you from paying to label the same image multiple times.
LightlyOne can also automatically identify and filter out low-quality samples and select a diverse set of images that represent the full range of your data.

LightlyTrain: Self-Supervised Model Training
LightlyTrain solves the other part of the problem by addressing what to do with the 99% of data you did not label.
LightlyTrain uses self-supervised learning to pretrain your model on your entire unlabeled dataset. It teaches your model to learn visual features and understand your specific domain. You can now also fine-tune your model using LightlyTrain.
It supports many modern architectures, such as ResNets and Vision Transformers, that serve as the "backbone" for a panoptic segmentation architecture.
Conclusion
Panoptic segmentation helps computers better understand scenes by combining two types of analysis into a single, detailed view. It simplifies processes, reducing the need for multiple models to deliver the pixel-level understanding.
Panoptic segmentation is helpful in areas like robotics, self-driving cars, and medicine. As models improve, especially for 3D and video, panoptic segmentation will play a crucial role in helping machines better understand our world.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


