
A Practical Guide to Data Redundancy in Computer Vision
Table of contents
Share blog post



What is redundant data and why is it important? This article tackles both the advantages and disadvantages of redundancy in the context of computer vision.
Share blog post
Here is what you need to know about the data redundancy in computer vision:
What is data redundancy?
Data redundancy happens when the same information is stored more than once. For example, a customer’s details might appear in several databases, or a dataset might contain many copies of the same image.
Some redundancy is intentional, like backups that protect against data loss. Other times it’s accidental, caused by poor data management or overlapping data sources.
Why is data redundancy important?
Redundancy has benefits and risks. On the positive side, it improves resilience. If one copy of the data is lost or corrupted, another version can keep systems running. This is especially important for disaster recovery and business continuity.
Excessive redundancy wastes storage, increases complexity, and raises the risk of inconsistency. With multiple versions in play, it becomes unclear which record reflects the correct data.
How do you reduce or avoid unwanted redundancy?
Organizations use several methods to keep redundancy under control:
- Database design: Normalization ensures each fact is stored only once.
- Master data systems: A single source of truth for key records.
- Regular cleanup: Deduplication tools automatically remove duplicates.
- Data selection in ML: Active learning and intelligent sampling filter out uninformative images.
These steps make datasets smaller, cleaner, and more useful.
How does data redundancy affect computer vision projects?
In computer vision, redundancy usually means duplicate or near-duplicate images. Redundant images add little value to training but increase cost and bias. If a model sees too many near-identical images, it may overfit to those cases.
Introduction
Large computer vision datasets often include redundant data samples that increase storage overhead and slow down training. These duplicates also distort class distributions and can bias model performance.
However, data redundancy is often necessary to ensure backups are available in case of system failures. This blog explains how to optimize redundancy effectively, using benchmarks to demonstrate its impact on performance and class balance.
In this blog, we will cover:
- What is data redundancy
- Advantages & drawbacks of data redundancy
- Common causes of unintentional data redundancy
- Data redundancy vs. data backup vs. data replication
- How to reduce and manage data redundancy
- How to filter redundant data: Lightly Tutorial
Managing redundancy requires automated tools that can identify, filter, and curate data at scale.
Lightly AI uses embedding-based similarity search to identify and filter redundant data, retaining only the most informative and representative samples.
- LightlyOne offers workflows for data selection, deduplication, and governance, which ensures that redundancy is managed at scale in production pipelines.
- LightlyTrain enables seamless training with curated data so models like DINOv3 learn efficiently from representative, non-redundant samples.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What Is Data Redundancy?
Data redundancy occurs when the same information is stored in multiple locations across an organization’s systems. This could be customer data repeated in several databases, original data spread across storage nodes, or files replicated in distributed file systems.
Sometimes, redundancy is intentional, such as in redundant array of independent disks (RAID) configurations. It can also appear in erasure coding, which ensures more data protection in the event of hardware failures or data loss.
In some cases, unintentional duplication may occur due to poor data management. This can include the duplication of historical data in business software or the improper use of storage space.
Such unmanaged redundancy can also manifest in storage systems, database systems, or unmonitored backup systems, all of which increase risk and inefficiency.
💡Pro tip: When controlling duplicates in large datasets, our Navigating the Future of Edge AI article highlights how intelligent edge-side filtering reduces unnecessary data flow.
Data Redundancy in Computer Vision
In computer vision, data redundancy often refers to duplicate or near-duplicate images in a dataset. For example, a dataset might contain different locations of the same image or multiple frames from a video that look almost identical.
Although large datasets may appear valuable, redundant data rarely improves data accuracy and often causes performance degradation during training. This is why modern machine learning workflows rely on data curation, intelligent sampling, and database normalization techniques.
Near-duplicate images and normalized data allow teams to focus on the primary data that matters most. The result is higher data quality, faster training, and more insightful reports.
Why It Matters
Managing redundancy requires striking a balance between data availability and storage maintenance costs. A robust redundancy management framework helps organizations:
- Protect against data loss through planned data restoration and disaster recovery plans that can restore systems quickly.
- Improve data consistency with master data frameworks that keep common business data aligned.
- Ensure the organization’s data remains accurate by standardizing entries and eliminating discrepancies between database management systems.
- Enhance operations through customer relationship management to reduce errors in customer interactions and improve customer service.
💡Pro Tip: If you are trying to overcome gaps or imbalances while reducing redundant samples, our Synthetic Data guide shows how to generate targeted examples that strengthen model performance.
Advantages of Data Redundancy (When Redundancy is Useful)
Data redundancy, while sometimes viewed as inefficient, can provide significant benefits. The table below outlines its key advantages, explains how it benefits users, and offers real-world use cases.
Drawbacks of Data Redundancy (Why Redundancy Can Be a Problem)
Redundancy isn’t always beneficial. Beyond added storage overhead, it can introduce a range of technical and operational issues.
The table below highlights the key drawbacks of data redundancy and the solutions to handle them:
Recognizing these drawbacks and applying the right solutions can turn redundancy from a hidden liability into a manageable part of the data strategy.
Common Causes of Unintentional Data Redundancy
Unintentional redundancy often arises from gaps in design or poor data management practices. From misconfigured databases to siloed business software, these issues create duplicate records that inflate storage and undermine data consistency.
Understanding these root causes helps organizations prevent errors before they spread across multiple systems.
- Poor database design (lack of normalization): When databases are not normalized, the same information is stored in various locations. Metadata (labels or IDS of the images) in computer vision applications can be replicated in different datasets, which causes discrepancies in the data.
- Multiple systems and data silos: Multiple teams and software often have separate databases, which results in redundant storage of overlapping customer and business data. In computer vision workflows, annotation tools, model training systems, and storage nodes may each keep separate copies of the same raw data.
- Manual data entry and collection points: Manual data entry often causes duplicates, and uncoordinated annotator labeling can produce redundant or mismatched images in computer vision. Enforce data standards, provide annotation guidelines, and use automated deduplication tools to catch issues early.
- Independent backups and legacy versions: Old datasets, secondary backups, and unused raw data often pile up in distributed file systems or data centers. Outdated copies decrease data quality and raise storage costs without appropriate cleanup.
- Application bugs and integration issues: Broken code or poorly configured pipelines may cause data duplication. For example, an ingestion pipeline can replicate the same image on multiple storage nodes, which increases storage use and slows performance. Integrations can be prevented by regular testing, monitoring, and validation to avoid such redundant copies.
Data Redundancy vs. Data Backup vs. Data Replication
Redundancy, backup, and replication are often confused, but they operate at different layers of storage architecture.
Understanding their distinctions is crucial for designing systems that strike a balance between fault tolerance, disaster recovery, and high availability.
Redundancy operates at the block/storage layer, backups at the data lifecycle layer, and replication at the system/network layer.
Modern architectures combine all three, using redundancy for local resilience, backups for compliance and disaster recovery, and replication for high availability across distributed environments.
Data Normalization for Efficient and Reliable Vision Datasets
Data normalization reduces redundancy by structuring databases so each fact is stored only once, linked through keys and relationships. This prevents duplicate records across tables, lowers storage overhead, and ensures consistency.
In computer vision datasets, redundant attributes such as driver IDs, GPS coordinates, or sensor metadata often lead to increased annotation records and database size.
Through relational normalization, these attributes are factored into separate tables and referenced via primary–foreign key relationships.
This enforces data integrity, reduces storage overhead, and ensures consistent schema alignment for efficient training, replication, and recovery workflows.
How to Reduce and Manage Data Redundancy
Reducing redundancy strengthens data integrity, consistency, and system performance. Achieving this requires a structured approach that combines sound database design, robust data governance, and automated tools for eliminating duplicates.
The following practices help build a sustainable framework:
- Establish a single source of truth: Host all vital primary data (customer data, product catalogs, employee records) in a single data management system. This minimizes interoperability between business programs and enhances data quality.
- Normalize databases: Use data normalization to ensure that the same fact is only kept once and the relationship is established using foreign keys. This reduces database size, removes duplicate data fields, and improves data quality.
- Use integration and synchronization tools: When combining data from multiple locations or distributed file systems, ETL pipelines and middleware can detect duplicates and enforce schema alignment. They also synchronize updates across systems, preventing version drift.
- Implement data deduplication at the storage level: Modern storage nodes and distributed systems support block-level deduplication and erasure coding. These eliminate redundant blocks, cut storage costs, and maintain continuous data protection without replicating unnecessary copies.
- Define lifecycle and backup policies: Redundant arrays, old snapshots, and secondary location backups can pile up if unmanaged. Define retention policies for raw data, master data, and secondary copies to prevent unnecessary growth and performance degradation.
- Apply data governance and quality controls: Adopt governance programs that enforce data accuracy, consistency, and compliance. Automated data quality checks can flag corruption or discrepancies across storage nodes before they propagate.
Standardize Data Entry and Collection: Reduce unintentional duplication by enforcing strict entry standards, consistent formats, and validation checks. For annotation workflows or manual input, ensure contributors check for existing records before storing new data.
Pro-Tip: If you’re working with annotated datasets, redundancy can creep in quickly and inflate costs. Choosing the right annotation partner makes a big difference - check out our list of the best data annotation companies to see how leading providers handle data quality and duplication.
How to Filter Redundant Data: Tutorial
Redundant data is common in computer vision.
Many datasets have near-duplicate samples, similar video frames, multiple photos of the same object, or repeated scenes.
The AIRS benchmark by Lightly revealed significant redundancy in video frame datasets. Models achieved nearly 90% of peak mAP while training on just 20% of the data by using embedding-based similarity search that filtered out duplicate samples.
Lightly tested four filtering methods to tackle redundancy. RSS served as a simple random sub-sampling baseline. WTL_unc focused on the most challenging images. It selected those where the model’s predictions were least certain.
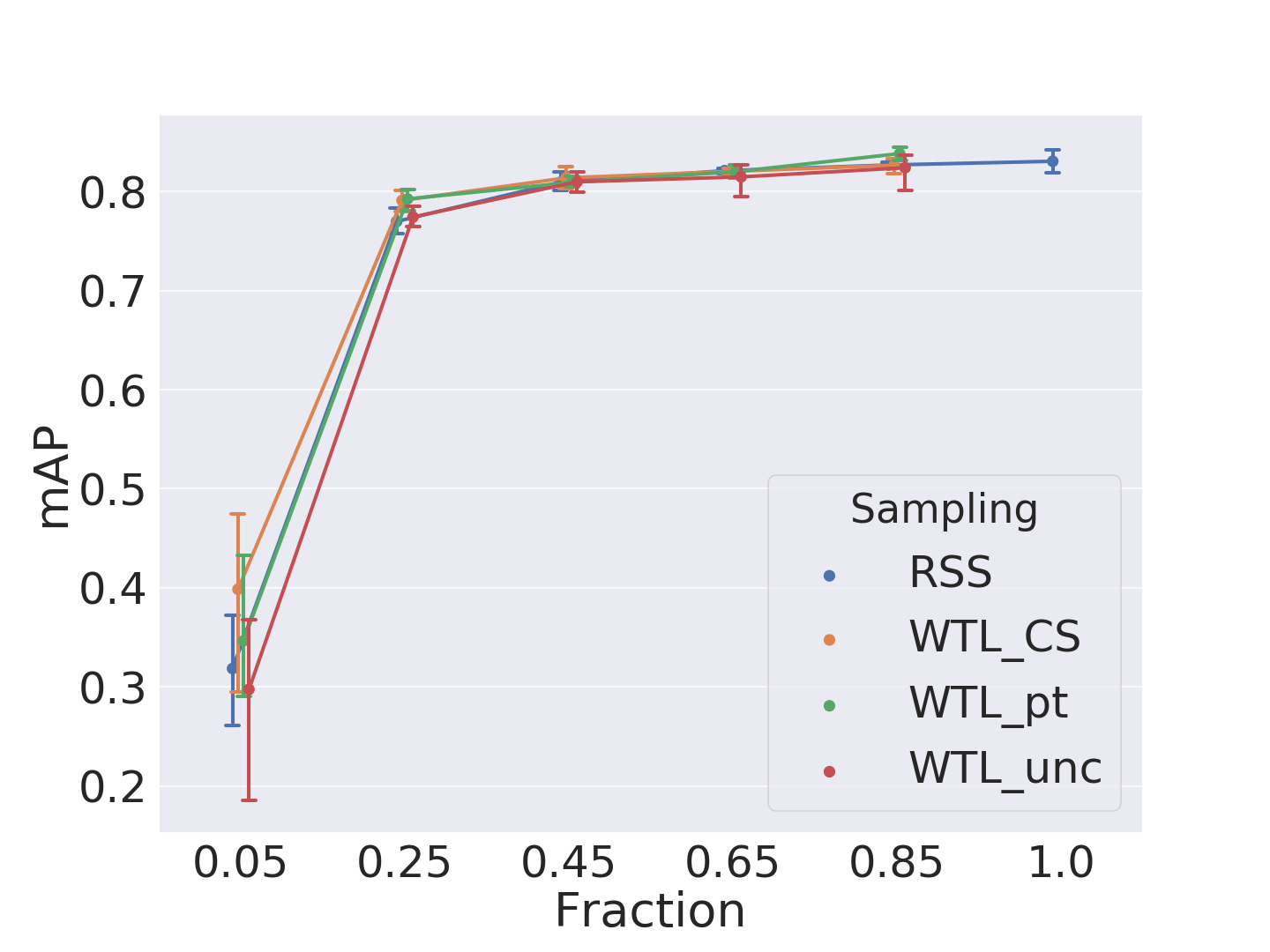
The mAP quickly saturates at 0.80 with just 25% of the data, improving only marginally to 0.84, which shows strong redundancy in the dataset.
For small fractions, WTL_CS clearly outperforms random sampling. In higher fractions, WTL_pt reaches full-dataset performance, while WTL_unc lags behind or only matches the baseline.
💡Pro Tip: If you want to see how evaluation metrics respond to low quality or redundant labels, our Mean Average Precision guide demonstrates how inconsistent annotations directly lower AP and mAP scores.
Reducing Redundancy with Embedding-Based Selection
Lightly also allows to manage redundancy with embedding-space filtering approaches, such as typicality and diversity. Typicality selects samples from high-density regions to avoid oversampling near-duplicates. This helps reduce redundancy by avoiding repeated or very similar samples.
It also uses diversity selection. This ensures selected samples are spread across the embedding space to capture varied instances and limit over-representation of similar regions.
Combined, these strategies produce smaller, more compact subsets that exclude many redundant samples but preserve the dataset’s essential patterns and performance.
Case Study: CIFAR-10
CIFAR-10 is a widely used benchmark dataset containing 50,000 training and 10,000 testing images across 10 balanced classes.
Example Images from CIFAR-10
To test redundancy filtering, subsets of only 500, 1000, 1500, and 2000 training samples were selected using two methods:

Dataset Representation
UMAP embeddings from LightlyOne visualize how well each subset represents the dataset. Diversity-only subsets scatter around outliers, while Typicality and Diversity subsets mirror the structure of CIFAR-10 more faithfully.
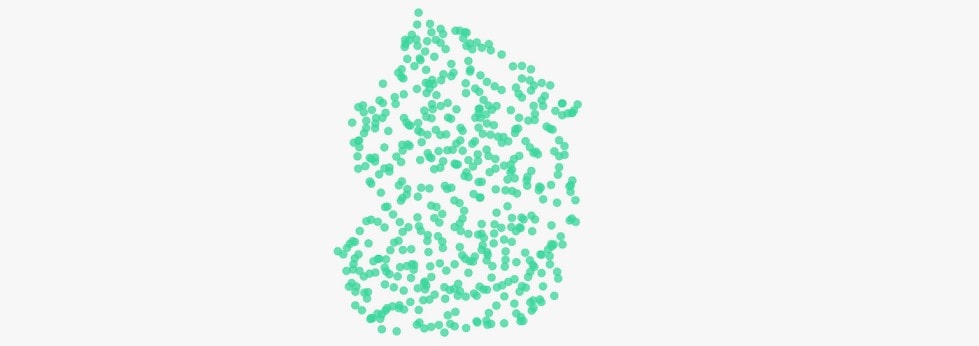
The selected points are scattered across the embedding space, with wide coverage. While this avoids exact duplicates, it often includes outliers and samples that don’t represent the core distribution well.
Redundancy isn’t fully eliminated because many selected points may still carry little new information relative to each other.
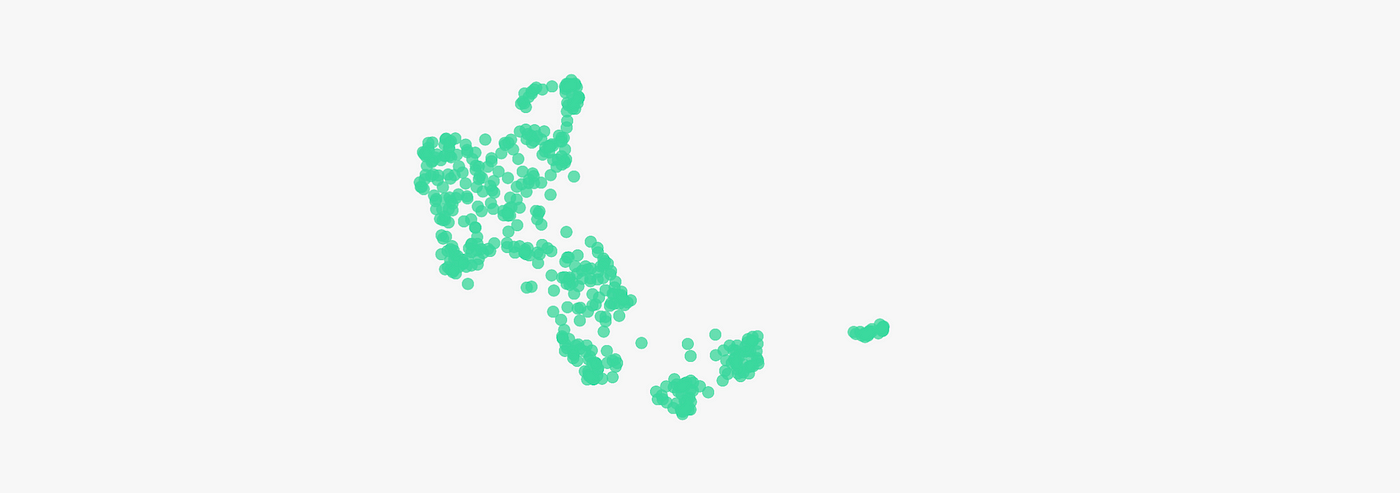
The selected points concentrate on dense regions while still spreading across the dataset. This means near-duplicates within clusters are filtered out (thanks to typicality), while diversity ensures coverage of less common areas.
The result is a compact, balanced subset with less redundancy and stronger representation of the true data structure.
The CIFAR-10 results demonstrate that smaller, smarter subsets can outperform larger, less curated ones.
💡Pro Tip: If you want to reduce redundant samples in industrial datasets such as X-ray imagery, our PIDRay case study shows how LightlyTrain identifies the most informative images for efficient training.
How to Apply Typicality and Diversity
To apply this approach in practice:
- Generate embeddings: Use a pretrained model (e.g., ResNet or Vision Transformer) to embed each image.
- Score typicality: Compute density for each embedding (e.g., average distance to nearest neighbors).
- Ensure diversity: Select a spread of samples across the embedding space using clustering or greedy selection.
- Combine both: Balance typicality and diversity when sampling to reduce redundancy while keeping coverage.
- Evaluate: Train models on subsets and measure performance compared to random or diversity-only selection.
For production workflows, LightlyOne provides ready-to-use implementations of typicality and diversity filtering.
How Lightly AI Helps in Reducing Data Redundancy
Handling redundant data requires scalable, automated tools capable of processing large and complex datasets. Lightly AI provides exactly this, with solutions tailored to both data curation and model training workflows.
Automated Curation for Redundancy Control
Automated curation is essential when dealing with large, evolving datasets. LightlyOne applies similarity search, typicality, and uncertainty-based sampling to automatically remove near-duplicates. This saves teams from manually auditing raw data.
It helps:
- Continuously identify redundant images in evolving datasets.
- Maintain high data quality by balancing diversity with representativeness.
- Integrate directly into existing data management systems and distributed file systems without disrupting pipelines.
This ensures storage costs are reduced while keeping only the most informative data for training.
Redundancy-Aware Training Pipelines
Beyond preprocessing, redundancy must be managed during training itself. LightlyTrain takes redundancy reduction a step further by integrating into the training pipelines.
Supported by self-supervised backbones like DINOv2 and DINOv3, these pipelines adapt continuously. This reduces database size and prevents performance issues caused by duplicates.
The result is faster training, stronger data integrity, and more accurate downstream models.
They help by:
- Filtering redundant or low-value samples during training.
- Improving efficiency by reducing database size and avoiding slowdowns from duplicates.
- Ensuring only useful data contributes to model updates.
This approach reduces storage costs, accelerates training, enhances data integrity, and yields more accurate models.
Conclusion
Data redundancy can provide protection, but if not managed, it quickly becomes a liability. Reducing duplicates strengthens data integrity, lowers storage overhead, and minimizes inconsistency.
Curating high-value data accelerates training and improves analysis. Ultimately, managing redundancy is crucial for developing efficient, reliable, and scalable data systems.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


