
DINOv3 Explained: Technical Deep Dive
Table of contents
Share blog post



DINOv3 is Meta’s latest self-supervised Vision Transformer, trained on 1.7B images with a 7B-parameter teacher model. Using distillation and innovations like Gram anchoring, it delivers powerful, general-purpose image features for tasks from classification to segmentation.
Share blog post
Below we answer common questions about DINOv3:
- What is DINOv3 and how does it work?
DINOv3 (Distillation with No Labels v3) is a state-of-the-art self-supervised Vision Transformer (ViT) that learns visual representations without any human annotations. Developed by Meta in 2025, it uses a teacher-student distillation approach: a very large ViT (7 billion parameters) is first self-trained on a huge image set, then smaller student models learn to mimic the teacher’s outputs. This yields a foundation vision model that produces rich image features usable across image classification, segmentation, depth estimation, and more – often without fine-tuning.
- How is DINOv3 different from DINOv2?
DINOv3 significantly scales up everything from the previous DINOv2. It was trained on an unprecedented ~1.7 billion images (vs. 142 million in DINOv2), using a 7B-parameter ViT teacher (vs. ~1B in DINOv2). It introduces new techniques like Gram anchoring (a loss that stabilizes patch-wise features during long training) and a high-resolution training stage .
- How can you use or fine-tune DINOv3?
Meta has open-sourced DINOv3’s code and model weights (21M up to 7B parameters) under a permissive license. You can load pre-trained DINOv3 backbones via PyTorch or Hugging Face and use their frozen features for your task (e.g. k-NN or linear probe for classification).
If needed, you can fine-tune on specific data. Tools like LightlyTrain make it easy to pretrain or fine-tune with DINOv3: for example, you can distill DINOv3 into a new model on your own dataset, or add a segmentation head on top of the DINOv3 backbone.
Meta released DINOv3, their latest vision foundation model and the Lightly team already implemented it in LightlyTrain.
Only trained on unlabeled images, DINOv3 closes the gap to supervised models across the most popular vision tasks such as classification, object detection, segmentation, and depth estimation.
This technical deep dive will cover:
- DINOv2 vs. DINOv3: What are the differences
- DINOv3 Architecture & Training
- DINOv3 Applications & Challenges
- DINOv3 in Practice: Pretrained Models, Fine-Tuning, and LightlyTrain Tutorial

DINOv2 vs. DINOv3: What Has Changed
DINOv2 has had a major impact on computer vision since its release in 2023 is now one of the most popular vision foundation models. DINOv3 is its successor and addresses key challenges from DINOv2: How to scale model and dataset size, and how to stop degradation of feature quality for dense tasks such as segmentation and object detection.
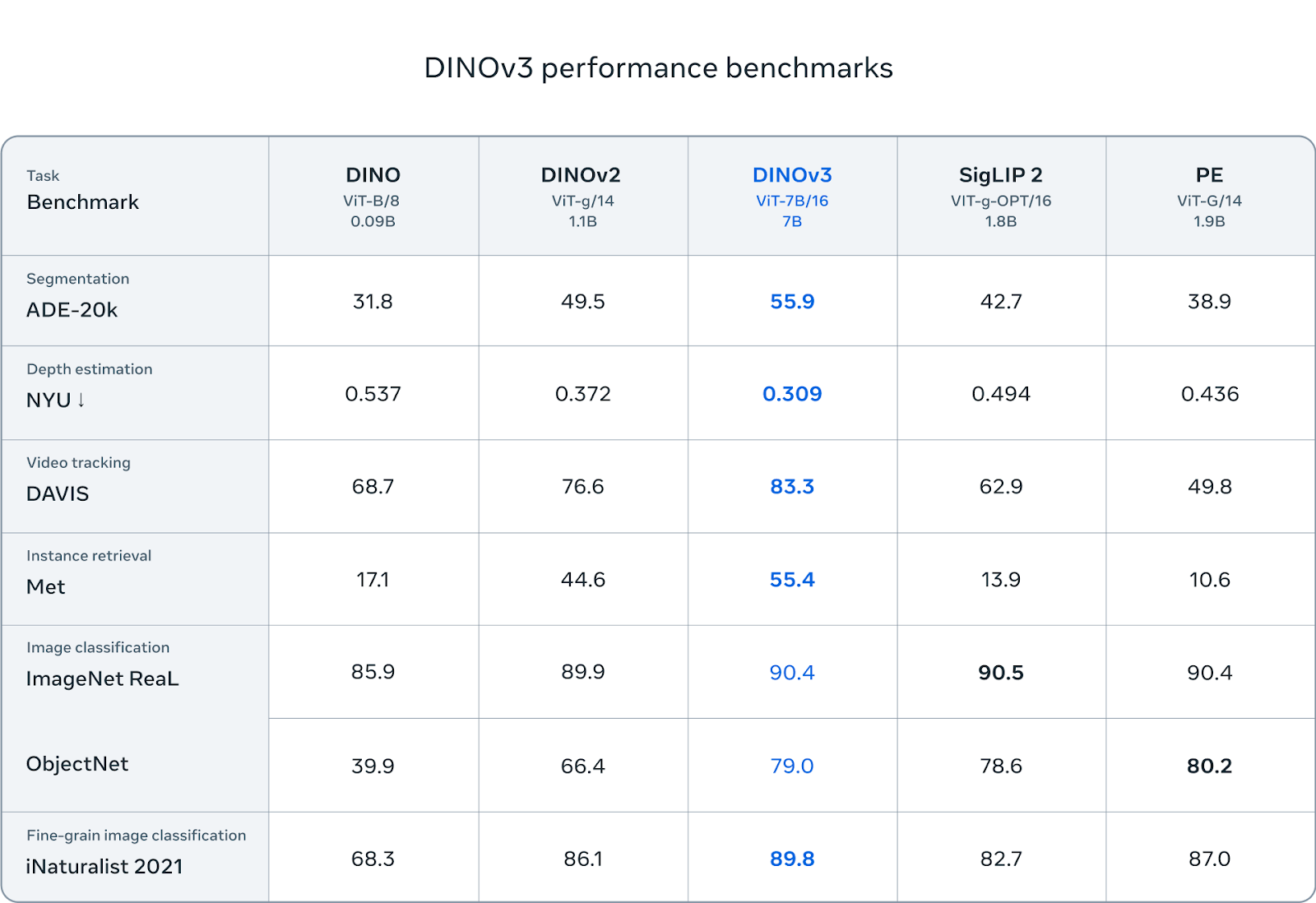
The table below summarizes the key differences between DINOv2 and DINOv3:
DINOv3 achieves SOTA performance across many tasks. In semantic segmentation it outperforms DINOv2 by +6 mIoU point on ADE20K, proving the excellent performance on dense tasks. It also generalizes well to tasks like video tracking (+6.7 J&F-Mean) and instance retrieval (+10.9 GAP).
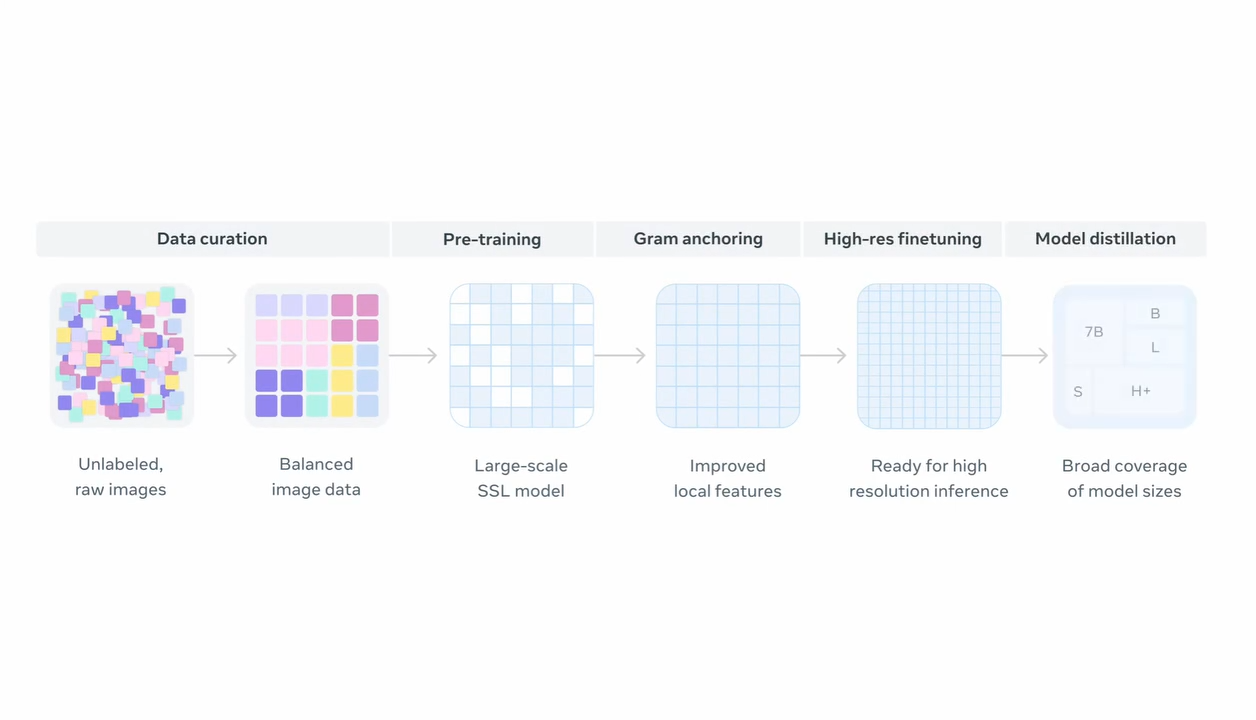
DINOv3 Architecture & Training
DINOv3 is not only a model but also a model development method that follows multiple stages. Starting with data curation, the initial 17B images are filtered down to 1.7B images. Then the model is pretrained using self-supervised learning, followed by Gram anchoring and high-resolution fine-tuning to improve performance for dense tasks. Finally, the model is distilled to smaller model sizes for easier deployment.
Large Dataset and Model
The first novelty of DINOv3 is the 12x larger training dataset and 7x larger ViT-7B model compared to DINOv2. Training on such a large scale is not trivial and a lot of effort went into developing a simple training recipe. DINOv2 is infamous for its complicated training recipe which features many hyperparameters that change during the training process (see this blog post for details). DINOv3 solved this problem by removing all hyperparameter schedules and training with a fixed learning rate, weight decay, and momentum. This makes it easier to estimate model performance when scaling the dataset and model size.
Gram Anchoring
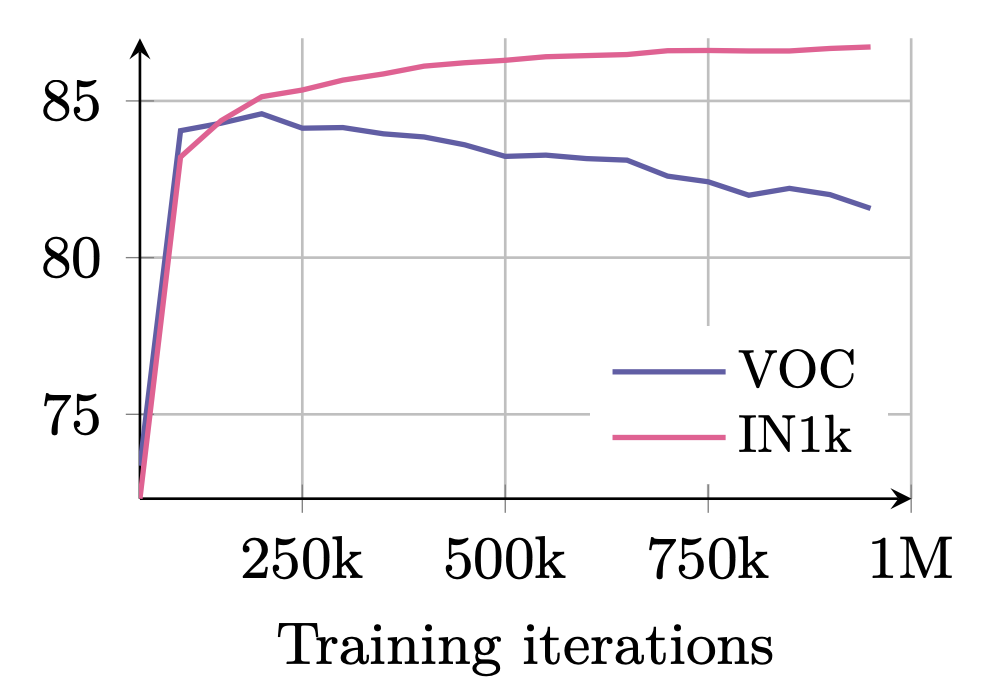
The second novelty of DINOv3 is the Gram anchoring process. Already in DINOv2 it was observed that there is a tradeoff between the quality of global features that describe the high-level semantics in an image (does the image show a cat or a dog?) and local features which contain information about smaller regions in an image (which pixel belongs to which object in the image?). The figure below shows this tradeoff during the training process where the quality of the global features increases compared to the local features:
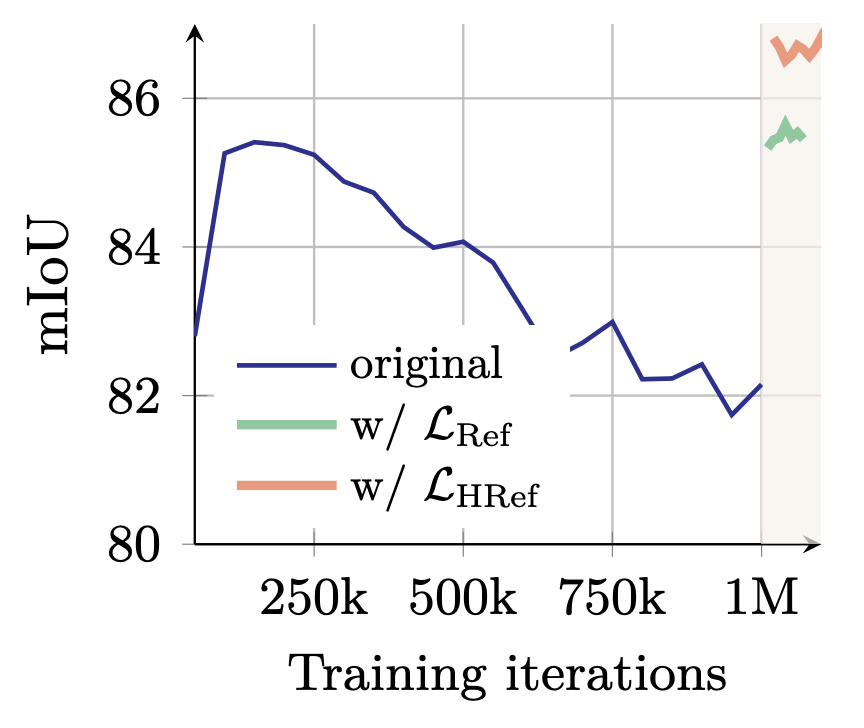
DINOv3 introduces Gram anchoring to address this problem. Gram anchoring works by taking the model checkpoint from an early training stage where the local feature quality is still high. This model is called the Gram teacher. The Gram teacher enforces that the similarity between local features in the same image remains unchanged during the training process. This stabilizes local features while preserving the strong global features. For efficiency, Gram anchoring is only applied at the end of training which is enough to fix the degraded local features as shown in the figure below.
High Resolution Images
The third improvement in DINOv3 focuses on high-resolution images and how they can boost the local feature quality. DINOv3 employs multiple tricks to learn as much as possible from high-resolution images. By passing high-resolution images to the Gram teacher and subsequently downsampling the output, a stronger learning signal is generated than if a lower-resolution image was used directly.
Furthermore, the model is adapted to higher-resolution images by training on images with up to 768px resolution. The learned positional embeddings from DINOv2 are also replaced with RoPE positional embeddings and RoPE jittering for better stability across image scales and resolutions. Together, these changes result in stable feature maps at image resolutions above 4k.

DINOv3 Applications & Challenges
One model, trained on billions of images with no labels, can now be applied to almost any vision problem – this is the promise that DINOv3 largely fulfills.
Researchers found that frozen DINOv3 features, combined with only minimal training (or none at all), deliver state-of-the-art or near-SOTA performance on a wide array of benchmarks.
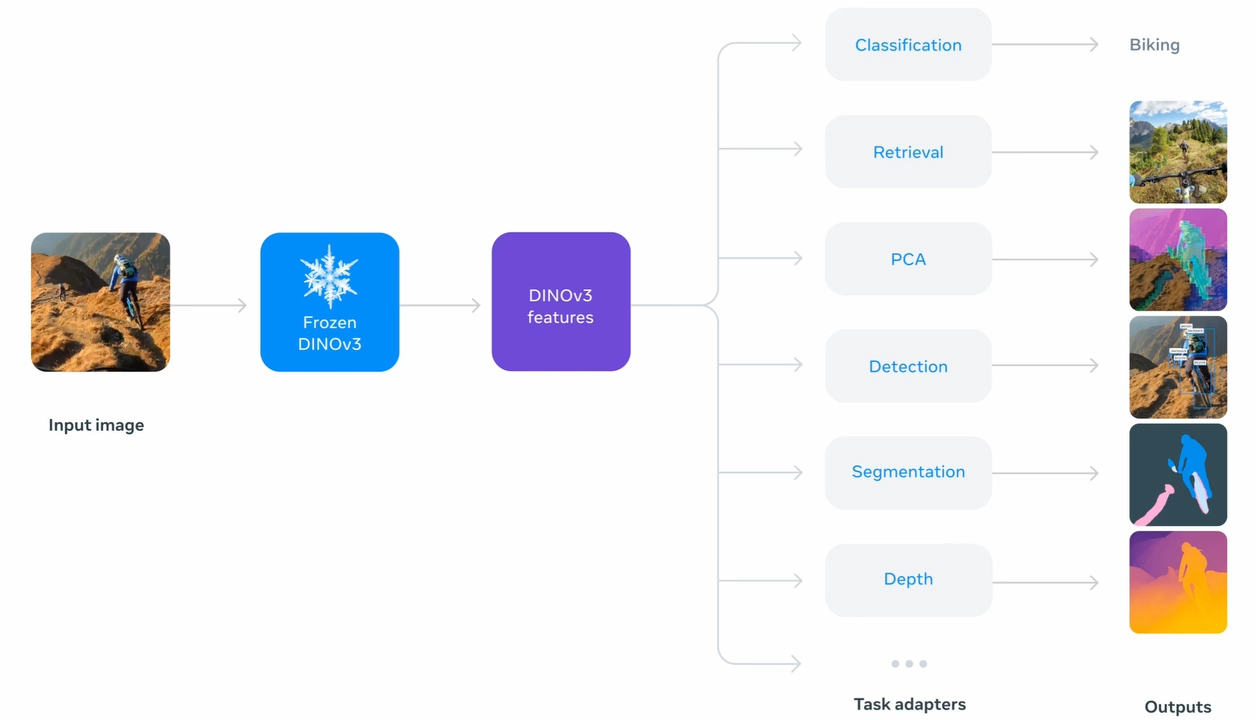
It outperforms not only its predecessor DINOv2, but also other SOTA models including some that use labels or weak labels. For example, on image classification it matches or outperforms CLIP-based methods (CLIP is a weakly text-supervised model) and on object detection it improves upon EVA-02 and PEspatial.
It is also better than popular fine-tuned depth estimation models including DPT, Marigold, and DAv2. In general DINOv3 raises the bar for SOTA models across the whole domain.
Real-Time Use Cases
DINOv3 also features a set of smaller ConvNext models that are optimized for memory and speed constrained environments. These models are distilled from the ViT-7B by transferring the knowledge from the large model to the smaller ones. Variants from 29M to 198M parameters are available. These models consistently outperform supervised counterparts trained on ImageNet22K across classification, segmentation, and depth estimation.
Using DINOv3 in Practice: Pretrained Models, Fine-Tuning, and LightlyTrain Tutorial
The Lightly team has been busy adding DINOv3 support to LightlyTrain and is happy to announce DINOv3 distillation and fine-tuning support! LightlyTrain brings the power of DINOv3 packaged into a simple to use solution which requires only a few lines of code to get started.
LightlyTrain GitHub: https://github.com/lightly-ai/lightly-train
LightlyTrain Documentation: https://docs.lightly.ai/train/stable/index.html
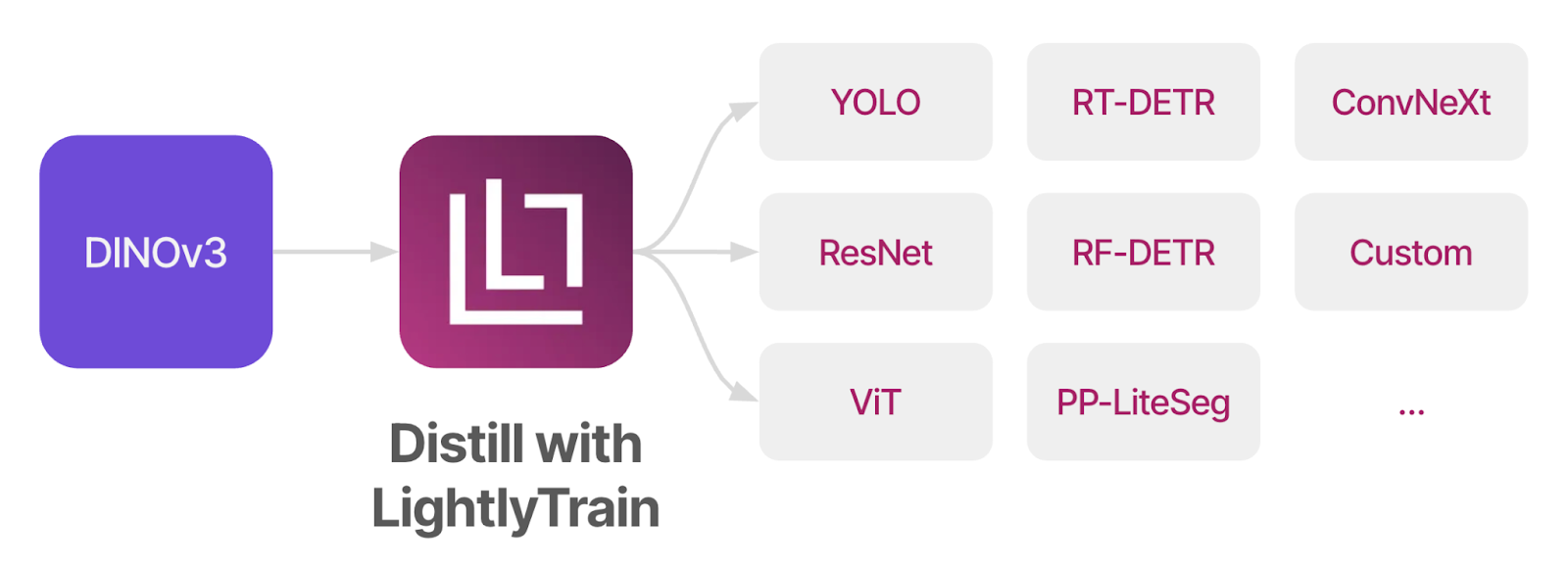
Distill DINOv3 Into Any Model Architecture
LightlyTrain lets you distill DINOv3 into any model architecture, including YOLO, ResNet, RT-DETR, RF-DETR, and 3custom models. This gives you the most flexibility while enjoying all the benefits from DINOv3.
The code snippet below shows you how to get started, head over to the LightlyTrain documentation for more information.
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="out/my_experiment",
data="my_data_dir",
model="ultralytics/yolo11",
method="distillation",
method_args={
"teacher": "dinov3/vits16",
# Replace with your own url
"teacher_url": "https://dinov3.llamameta.net/dinov3_vits16/dinov3_vits16_pretrain_lvd1689m-08c60483.pth<SOME-KEY>",
}
)SOTA Fine-Tuning with DINOv3 + EoMT
EoMT is the new SOTA segmentation model and was featured as a highlight paper at CVPR 2025. Originally built on top of DINOv2, Lightly adapted the model to DINOv3 and achieved a new SOTA on ADE20K with a ViT-L backbone.

Check out the code below on how to get started with semantic segmentation in LightlyTrain. More information is the documentation.
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov3/vits16-eomt",
model_args={
# Replace with your own url
"backbone_url": "https://dinov3.llamameta.net/dinov3_vits16/dinov3_vits16_pretrain_lvd1689m-08c60483.pth<SOME-KEY>",
},
data={
"train": {
"images": "my_data_dir/train/images", # Path to training images
"masks": "my_data_dir/train/masks", # Path to training masks
},
"val": {
"images": "my_data_dir/val/images", # Path to validation images
"masks": "my_data_dir/val/masks", # Path to validation masks
},
"classes": { # Classes in the dataset
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be ignored during
# training.
"ignore_classes": [0],
},
)DINOv3 and the Future of Vision Foundation Models
DINOv3 is a significant step forward in vision foundation models. Not only because of its sheer data and model scale but most importantly because it shows that pretraining on unlabeled data has fully closed the gap to supervised pretraining. Akin to the progress in LMMs, the future of computer vision is in large unlabeled pretraining datasets combined with smaller, high-quality labeled datasets for fine-tuning. DINOv3 makes it easier than ever to draw on the benefits of pretraining and gives you a big head start for your next computer vision project!
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


