
Improved Datasets
Lightly uses its data selection technology to compare against random and other subsampling methods on well-known academic datasets. We make the filenames of the samples in the curated datasets available here, for free, so that everyone can use the improved datasets for their own applications.
Note: We only run the training data through our data selection solution. The test set stays the same.
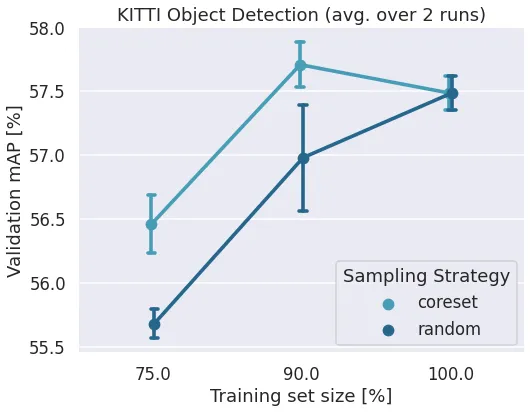
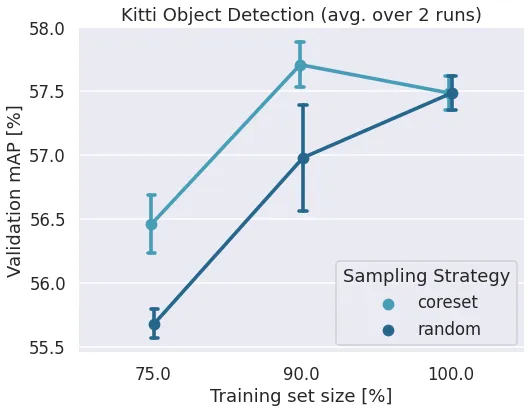
KITTI 2d Object Detection
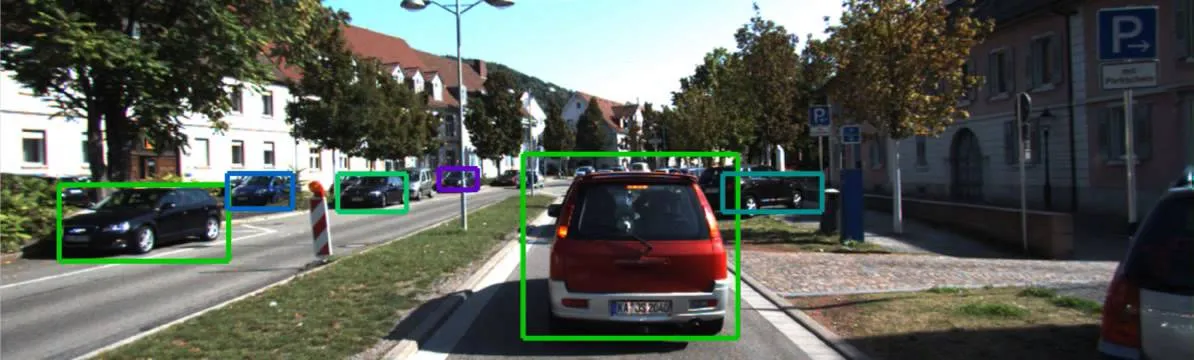
Using Lightly we can save 10% of the data labeling costs while improving the model accuracy!
Overview
Task: Object Detection (7 classes)
Total dataset: 7481 images
Training set: 5984 images
Curated training set (90%): 5386 images
Validation set: 1497 images
Evaluation Method
- Detectron2 (https://github.com/facebookresearch/detectron2)
- Faster RCNN using a ResNet-50, trained for 46k steps
- Varied parameter training subset size: 75%, 90%, 100%
- Varied parameter sampler: random, coreset
Scientific Dataset Studies
Learn more about how the Lightly subsampling method compares against random subsampling on well-known acadmic datasets.
Note: We only run the training data through our data selection solution. The test set stays the same. We do not recommend to do this in practice since train / test should have a similar distribution to properly evaluate a ML model. Additionally, these datasets went through a manual cleaning procedure to balance the dataset. We see on customer data much stronger impacts. Typically, we see the same test accuracy with 50% of the training data selected by Lightly as when using the full training dataset.
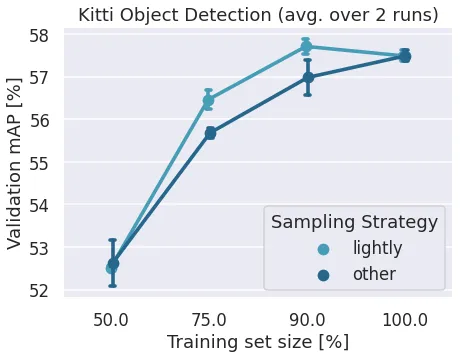
CamVid
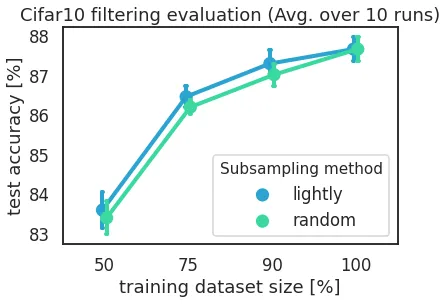
CIFAR-10
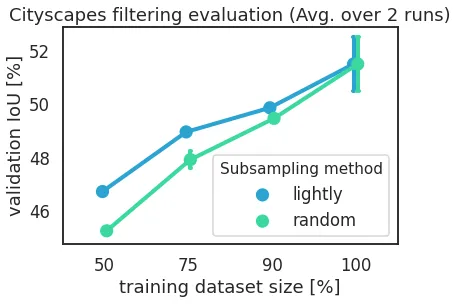
Cityscapes
Scientific Dataset Studies
Learn more about how the Lightly subsampling method compares against random subsampling on well-known academic datasets.
Note: We only run the training data through our data selection solution. The test set stays the same. We do not recommend to do this in practice since train / test should have a similar distribution to properly evaluate a ML model. Additionally, these datasets went through a manual cleaning procedure to balance the dataset. We see on customer data much stronger impacts. Typically, we see the same test accuracy with 50% of the training data selected by Lightly as when using the full training dataset.

Kitti
Kitti is a well-known dataset for autonomous driving for object detection.

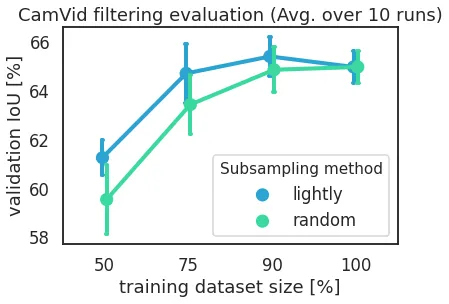
CamVid
CamVid is one of the first image segmentation datasets from 2007 and with little over 700 images for autonomous driving

CIFAR-10
CIFAR-10 is a well-known image classification dataset consisting of 10 classes.

Cityscapes
Cityscapes has been released in 2016 and is commonly used for benchmarking segmentation models in autonomous driving. It consists of 5'000 images.

1) Connect to unlabeled data
Connect Lightly with your data in GCP, Azure, and AWS S3 buckets. Data always stays on your infrastructure, which keeps your data secured and privacy guaranteed
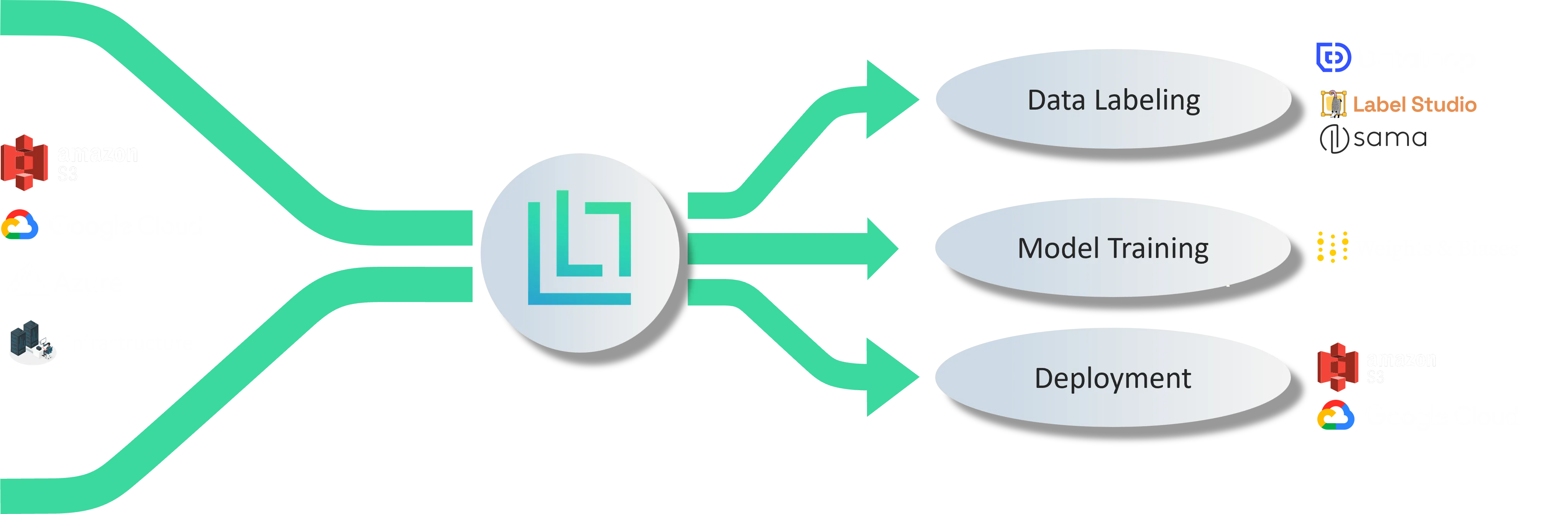
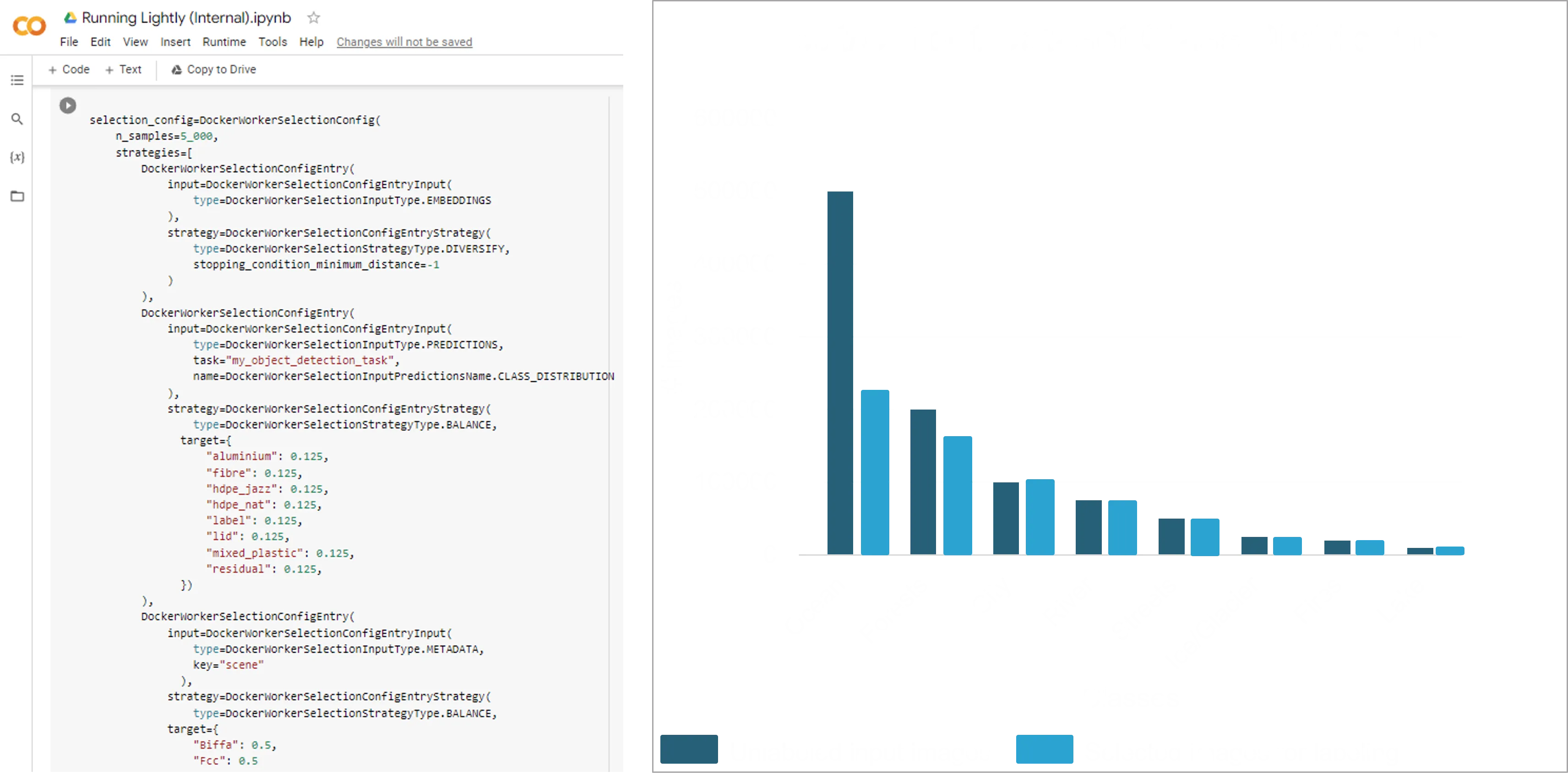
2) Define curation criteria
Use a combination of model predictions, embeddings, and metadata to reach your desired data distribution
3) Run the Lightly worker
Process your datasets on your infrastructure using our docker container. Lightly's highly optimized data curation engine can process millions of images by streaming them from the bucket without cluttering your disks
4) Use curated data for labeling and model training
Get your curated dataset labeled, train your machine learning model, and check the accuracy improvement.





