
Computer Vision Suite For
Lightly helps ML teams build better vision systems — from data curation to model pretraining, fine-tuning, and AI edge deployment. Build production-ready AI faster.

.svg)

.webp)
.svg)

.webp)





Trusted by enterprises, researchers and startups.





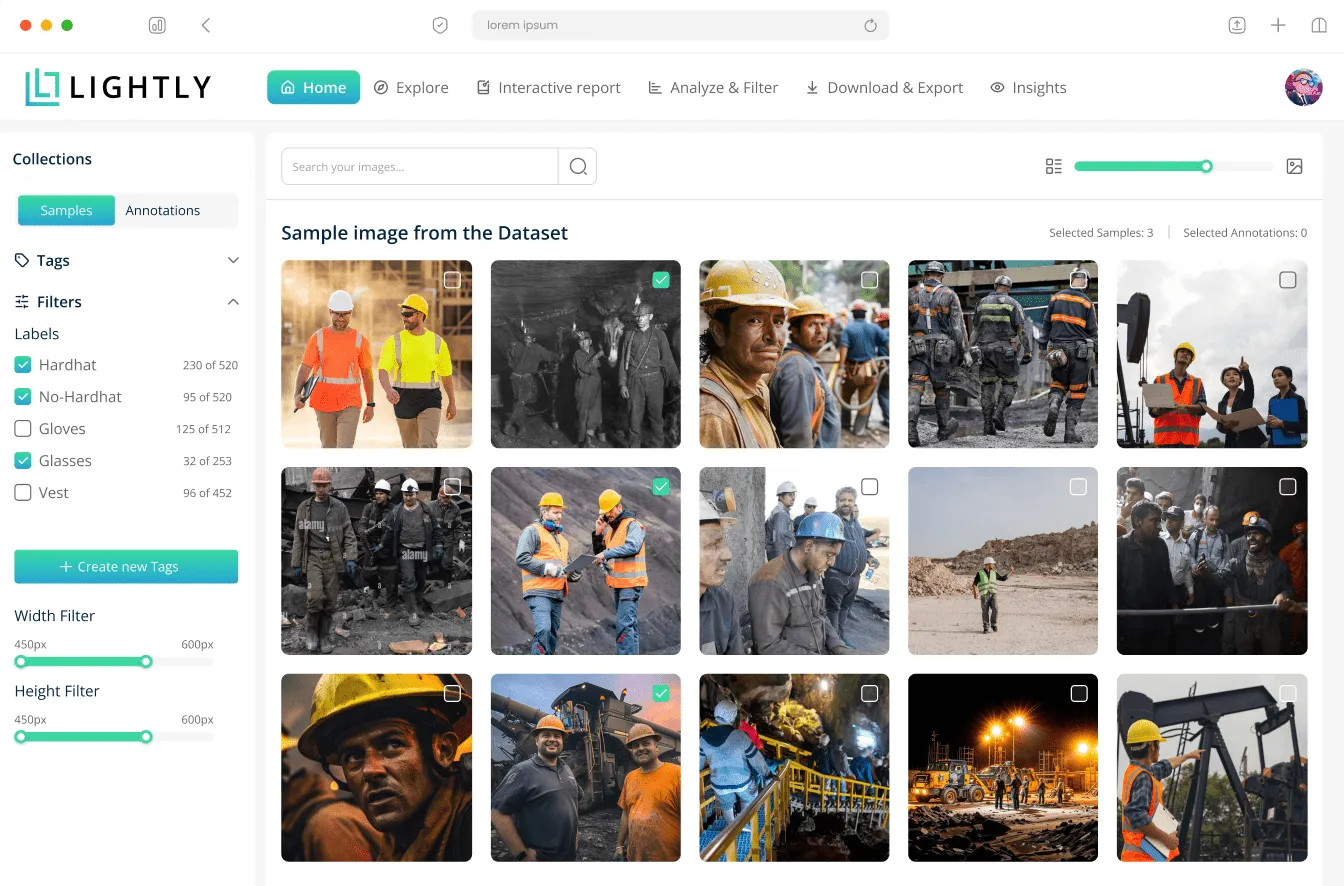
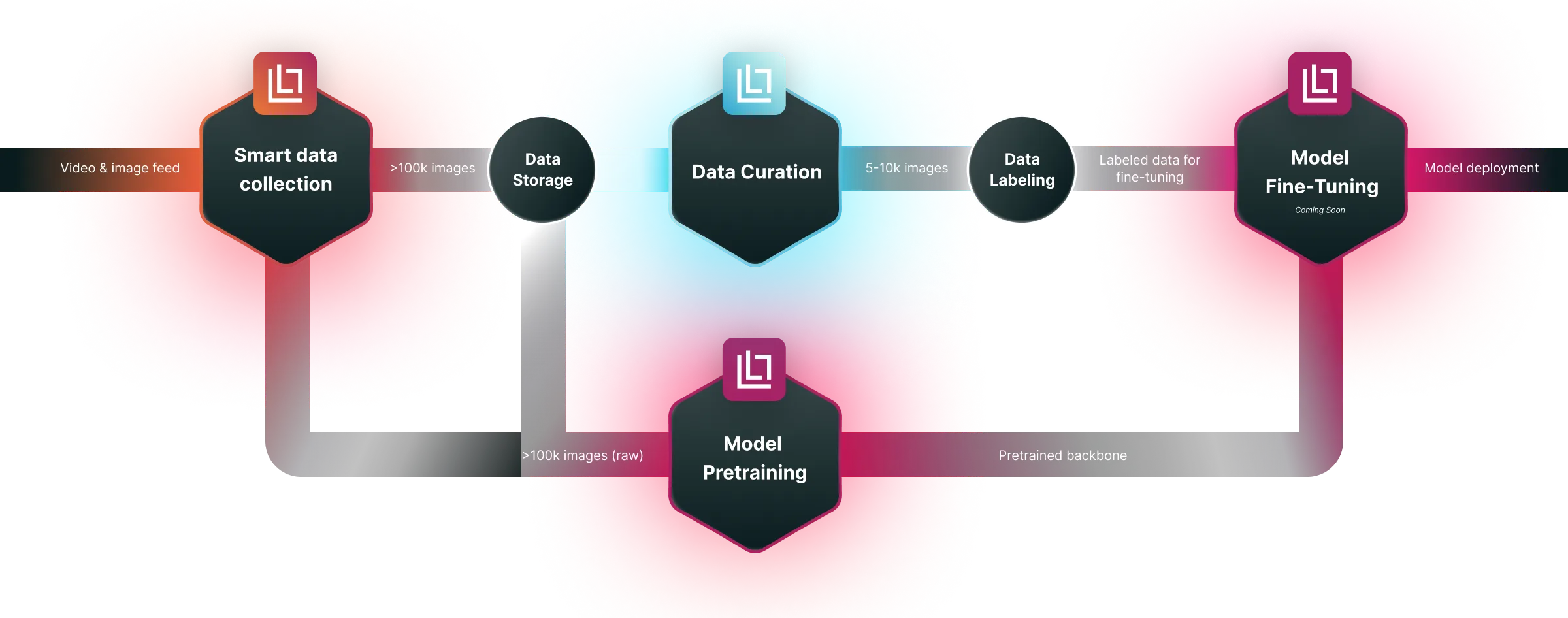
Fast & Easy Integration Into Your ML Pipeline
Lightly suite of tools integrates into your existing machine learning pipeline, facilitating data curation, model training, and deployment processes.

Explore Lightly Products

LightlyTrain
Self-Supervised Pretraining
Leverage self-supervised learning to pretrain models
LightlyServices
AI Training Data for LLMs & CV
Expert training data services for LLMs, AI Agents and vision
Built for solving data and model challenges across industries.
Lightly supports teams working with complex visual data—from raw collection to training-ready datasets and edge deployment.

Retail
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Agriculture
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Automobile
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Defense
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Government
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Manufacturing
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Heathcare
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.

Security
A canvas and end-to-end video editor that merges advanced AI with a user-friendly design.
Retail
Optimize visual data for smarter product detection, shelf analytics, and inventory monitoring.
Agriculture
Improve crop health insights and automate yield analysis with better training data for vision models.
Automotive
Fuel safer perception systems for autonomous driving with curated, real-world visual datasets.
Defense
Enhance mission-critical AI models with precise, reliable visual data selection and filtering.
Government
Support infrastructure, public safety, and AI projects with compliant, high-quality image datasets.
Manufacturing
Boost defect detection and quality control by training computer vision models on curated datasets.
Heathcare
Advance medical AI by selecting high-quality imaging data that improves model pretraining for diagnostics and monitoring.
Security
Strengthen surveillance and anomaly detection systems with targeted, efficient visual data curation and model pretraining.

Computer Vision Open Source Tools You’ll Actually Use
We built Lightly’s open-source tools to help engineers move faster — and smarter — with vision data.

Commited to data security
Lightly maintains high security standards, ensuring data integrity and confidentiality for entreprise-grade machine learning operations.

ISO 27001
Lightly is ISO 27001 certified, ensuring the confidentiality, integrity, and availability of your data through robust information security management.
GDPR
Lightly is fully compliant with the General Data Protection Regulation (GDPR), protecting user privacy and upholding strict data handling standards.
Ready to Transform Your Computer Vision Projects?
Join the growing community of ML engineers using Lighlty.ai to build efficient, accurate computer vision systems form data curation to deployment




