Customer Success Stories
How Lythium Improved Defect Detection Accuracy by 36% Using Lightly
Lightly helped Lythium cut curation time by 50% and boost detection accuracy by 36% by selecting the most relevant frames from industrial video.

Lightly helped Lythium cut curation time by 50% and boost detection accuracy by 36% by selecting the most relevant frames from industrial video.


Lightly helped Lythium cut curation time by 50% and boost detection accuracy by 36% by selecting the most relevant frames from industrial video.

Lythium is a Chilean company that focuses on building deep learning applications for video analytics. One of their flagship products is automated quality inspection through computer vision in assembly lines and providing analytics. For this particular use case, instead of having humans check the quality of salmon filets, Lythium’s software analyzes the video feed in the factory in real-time and classifies the salmon filets into different quality categories.

To improve its existing system, Lythium relies on a manual data curation and selection process before sending the data for labeling. After labeling, they retrain the models to see how they improved and iterate until the target accuracy is reached. Even though these manual processes are prone to human errors, it was a sufficient solution so far.
.jpeg)
However, things have changed, as Lythium now collects more than 15’000 new images per day and they were facing the following issues:
To tackle these problems and to improve the data quality Lythium started using Lightly’s data curation platform. As an experiment, Lythium tested Lightly’s data selection against random selection.
“Lightly gave us transparency to a part of the ML development that is a black box, data. Furthermore, Lightly enabled us to do Active Learning at scale and helped us improve recall and F1-score of our object detector by 32% and 10% compared to our previous data selection method. We finally saw the light in our data using Lightly.”
Project Leader
Using Lightly’s self-supervised learning (SSL)feature, Lythium selected the thousand most diverse images from a dataset of 20k images. After the first iteration, the active learning on an object level, based on the predictions, helped them select another batch of thousand images that were fine-tuned with the SSL feature. On top of that, Lythium applied the advanced selection feature to rebalance the dataset based on several factors.
Lightly’s selection outperformed random selection significantly. In general, a 36% higher accuracy was achieved, while recall improved by 32%. Looking at the F1 score, below Lightly outperformed random significantly in almost every class enhancing it by 10%.
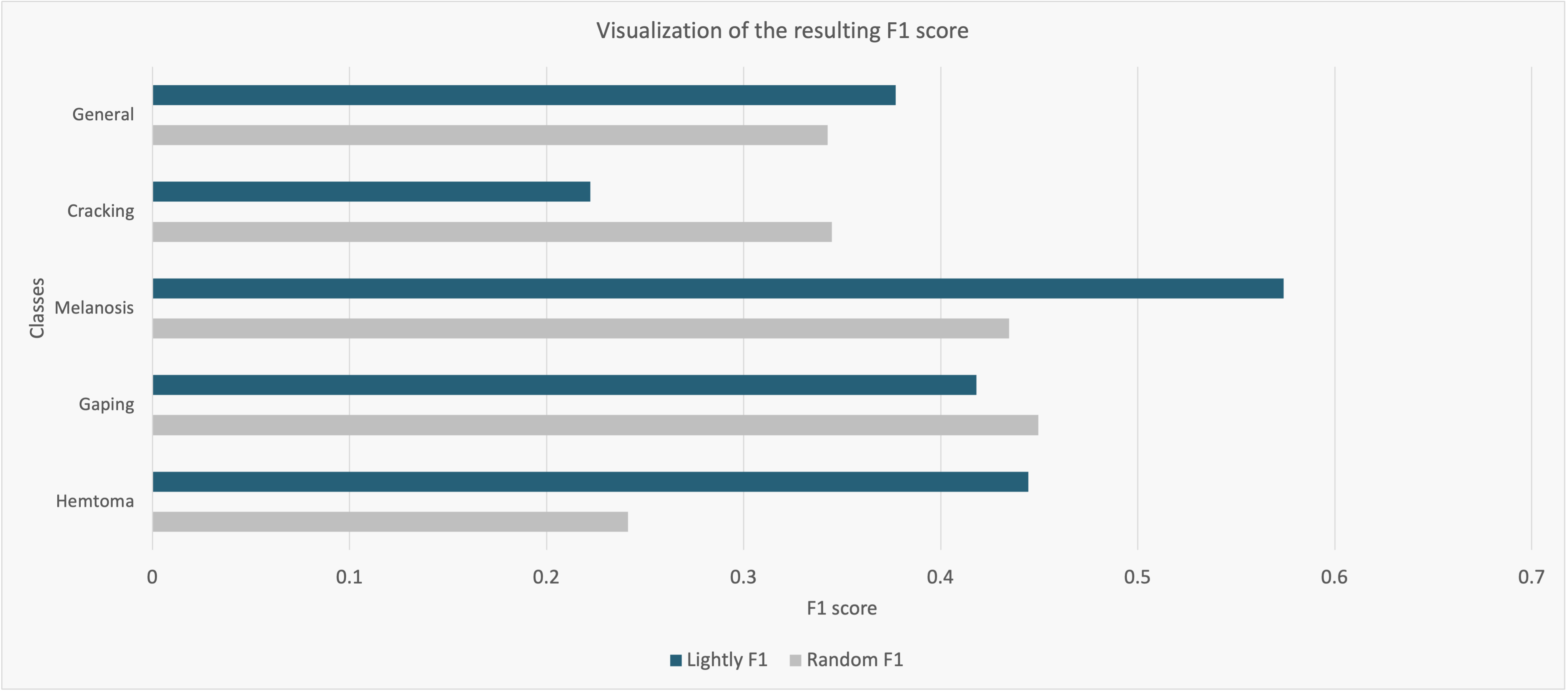
These improvements allowed Lythium to pass on the following benefits to their customers:
Thanks to Lightly, Lythium could reduce the time spent on data curation by 50%. Lightly’s active learning pipeline helped them improve the model accuracy significantly after only a few iterations (!). Furthermore, it provided them with an insightful overview highlighting areas of missing data samples. Most importantly, the Lightly platform allows them to automate and scale their processes efficiently while gaining transparency over the impact of data selection on model performance.
No fluff—just results from teams using Lightly to move faster with better data and models.


"Through this collaboration, SDSC and Lightly have combined their expertise to revolutionize the process of frame selection in surgical videos, making it more efficient and accurate than ever before to find the best subset of frames for labeling and model training."

Self-Supervised Pretraining
Leverage self-supervised learning to pretrain models

AI Training Data for LLMs & CV
Expert training data services for LLMs, AI Agents and vision





Picking DINOv3 or YOLO11 is easy. Getting it to run in production isn’t.
Learn how to do it properly. 👇










.svg)
.svg)