
What Is Data Labeling? A Practical Guide for ML Engineers
Table of contents
Share blog post



Discover what data labeling is and why it's essential for training accurate machine learning models. This guide covers common labeling tasks, tools used by teams, and challenges like quality control and scaling annotation workflows.
Share blog post
Below you can find a quick summary of key points about data labeling.
What is data labeling?
Data labeling, or annotation, tags raw data (images, text, audio, video) with machine-readable information. Each data point receives a label that describes its content or context. In object detection, for example, bounding boxes are added to images around objects such as cars or people to help the model recognize them in the real world. Such labels provide supervised signals to optimize weights, evaluate model accuracy, and compute loss.
Why is data labeling important?
For supervised learning, you must have high-quality labeled data. High-quality data labeling leads the model to generalize effectively and ensures stable model behavior in production. Even slight label inaccuracies can reduce a model’s generalization performance.
How is data labeling done?
Data labeling work is categorized into three types:
- Manual labeling: Human annotators assign labels to raw data and draw bounding boxes around objects or audio recordings. The results are precise, but the process is slow and costly.
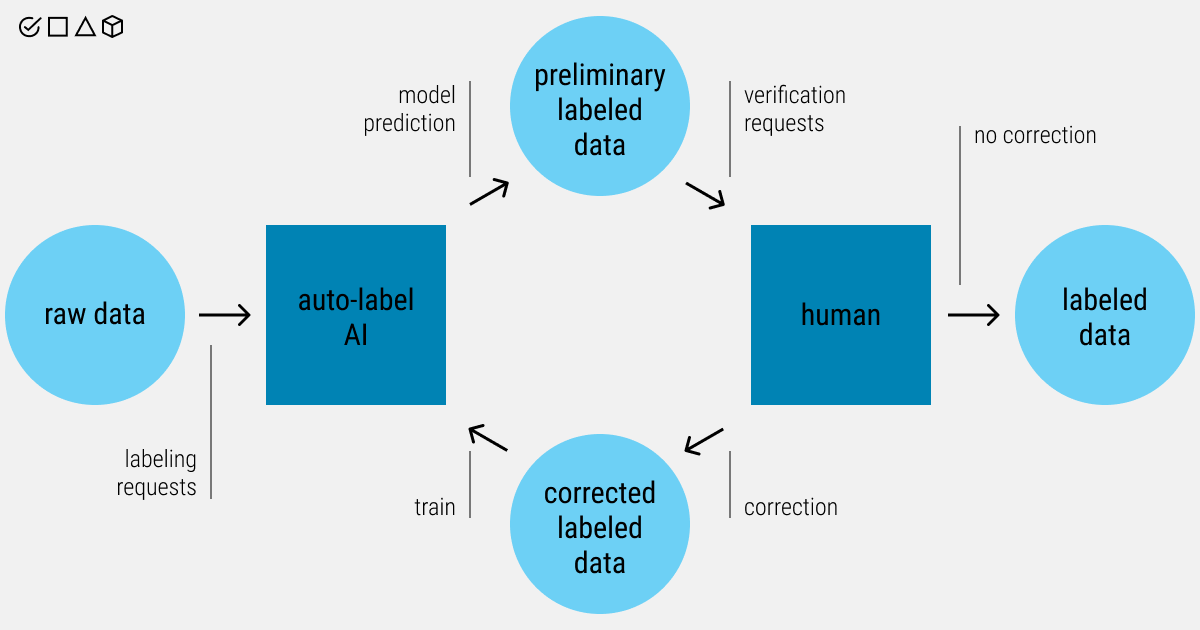
- Automated labeling: This method uses machine learning models or business heuristics to automatically associate labels with the appropriate data. It is faster than manual data labeling but requires human review (human-in-the-loop) for validation.
- Hybrid labeling: Initially, the ML model assigns labels to the data, and active learning helps identify which uncertain samples should be prioritized for human review.
What are common data labeling tasks?
Data labeling tasks are dependent on the task domain.
Computer vision tasks require adding annotations to image data. These annotations include class labels for image classification, bounding boxes for object detection, and pixel-level segmentation masks for semantic segmentation.
In natural language processing, data labeling includes class labels for text classification, entity tagging for named entity recognition, part-of-speech tagging, and transcriptions for automatic speech recognition (ASR).
Every task calls for domain-specific tools. You need polygon tools for segmentation, span selectors for NER, or waveform interfaces for audio transcription.
What tools or platforms are used?
Specialized data labeling tools help annotate workflow management, quality assurance, and label auditing. Tools such as LabelStudio, CVAT, and commercial platforms such as Scale AI and Amazon SageMaker Ground Truth support annotators in drawing bounding boxes and labeling.
Developers should also evaluate whether platforms support dataset versioning via DVC, Biases, or in-house metadata stores.
What are the challenges in data labeling?
Labeling data can be a slow and error-prone task, especially with a lot of data involved. With more data, there is a higher risk of human error because annotators may become tired, switch between different tasks, and handle ambiguous cases.
Sensitive information can also raise privacy issues during data labeling. With programmatic labeling and active learning, the manual data labeling process can be reduced without losing quality.
Before AI, data labeling was an overlooked, tedious backstage task. Now, it plays a key role in building strong AI systems by turning raw data into useful information. Sometimes, having a small amount of clean, well-labeled data is preferable to a large amount of messy data.
This guide will break down the data labeling process, tasks, tools, and challenges.
We will cover:
- What is data labeling?
- How does data labeling work?
- Common data labeling tasks and data types
- Why data labeling is critical for ML
- Data labeling tools and platforms
- Challenges in data labeling
- Future trends in data labeling
Labeling data can be expensive and time-consuming, but smarter data selection reduces both.
LightlyOne helps you choose the most valuable data to label, minimizing cost while maximizing impact.
With LightlyTrain, you can pretrain models on your unlabeled images first, so your labeled data goes further when fine-tuning.
You can try both for free :)
What is Data Labeling?
Data labeling means adding clear and useful tags to raw data. These tags highlight important parts or categories that a machine-learning model needs to recognize or predict. This includes objects in images, sentiment in reviews, or transcripts in audio clips.
During training, supervised machine learning models can learn to associate these labels with the data features and predict them during inference.
Often, the terms "data labeling" and "data annotation" are used interchangeably. However, they have subtle differences.
Labeling is typically used in classification tasks to define output classes (e.g., “positive” or “spam”). In contrast, annotation is used for more complex tasks that require richer information, such as bounding boxes or highlighted entities.
Both labeling and annotation help create clear, organized data that models can easily learn from. Most of the time, they are done together in the same process.
Labeled Data vs. Unlabeled Data
To better understand the concept of labels, let’s look at the difference between labeled and unlabeled data in more detail.
- Unlabeled data: Real-world systems like sensors, web interactions, web scraping, and system logs all produce unlabeled data. It is easy to gather, but it lacks context and cannot be used for supervised learning.
- Labeled data: Each data point in labeled data has an annotation that explains its contents or meaning. Labeled data acts as fuel for training, validating, and testing models, but it is costly and time-consuming, and often depends on the field of use.
Labeling an extensive collection of unlabeled data for a specific purpose is difficult, and it can lead to a bottleneck in most AI processes.
💡Pro Tip: You can check our list of 12 Best Data Annotation Tools for Computer Vision (Free & Paid) to pick a tool that suits your needs.
The model may perform poorly if the training data has incorrect, unclear, or inconsistent labels. This makes label quality vital for successful deployment.
It is important to use ground truth data, which acts as a reliable foundation for training and evaluation, to ensure models learn correctly.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Ground Truth
A model learns from a dataset that contains correct and verified labels. This is often referred to as ground truth data.
Ground truths should resemble real-world situations as much as possible. Also, annotators should identify bias by reviewing the distribution of labels (e.g., an overabundance of one class) and making adjustments to improve the model’s results.
For instance, you could train a natural language processing model to analyze the sentiment in customer reviews. First, we gather a set of reviews without labels and ask experts to label each as "positive," "negative," or "neutral."
These labeled reviews will act as ground truth for the model. If a review that is actually "negative" is incorrectly tagged as "positive," the model may make the wrong prediction in future reviews.
Clear labeling standards and careful review of labels are crucial to make accurate predictions.
Data Labeling and Machine Learning Pipeline
Building a robust machine learning system requires a reliable data labeling pipeline to ensure the AI model’s predictions are consistent and accurate. While each pipeline may vary depending on the use case, the following guidelines highlight the critical steps a pipeline should include:
- Data Collection and Organization: The process starts with collecting and organizing raw data from multiple sources. For example, if a company is building a recommendation system, it will collect user behavior data from various platforms, including websites and social media platforms.
- Data Cleaning and Preprocessing: Before annotation, data is cleaned, normalized, and augmented to make it usable. This may also include pre-labeling data using AI algorithms to speed up the process.
- Human-in-the-Loop (HITL) Annotation Verification: In HITL workflows, human annotators verify and improve automated labels. With automated tools and expert input, the annotations are highly accurate, especially in situations where context is crucial.
- Training Models: Once the data is labeled, it is used to train the models. For example, a speech recognition system uses labeled audio transcripts to learn how to change spoken words into text.
- Challenge with Unseen Data: Models can struggle when exposed to new scenarios. For example, images captured in unfamiliar lighting conditions. These situations often reveal the limits of the initial training data.
- Continuous Retraining with New Data: Modern pipelines integrate continuous retraining with new data and labels to address the challenge of unseen data. They use tools like Airflow, Metaflow, or Kubeflow Pipelines with CI/CD systems for retraining.
Rather than only improving the model, data-centric AI focuses on providing better training data to make the model work more accurately.
💡Pro Tip: Every supervised pipeline, regardless of its complexity, relies on labeled data. If you don’t have a lot of labeled data, try using self-supervised learning techniques to reduce the amount of data you need to label.
How does Data Labeling Work?
The data type and machine-learning model workflow determine the labeling approach. In manual workflows, humans use specific tools to tag data by drawing boxes, selecting text, or applying labels.

Automated labeling relies on pre-trained models or weak supervision techniques, such as Snorkel, to assign labels to large volumes of data. Often, human-in-the-loop reviews update these labels based on a confidence threshold to ensure accuracy.
Common Data Labeling Tasks and Data Types
Data labeling methods vary depending on the use case, as each scenario may require different annotation types. Here, we explain the most common types of data labeling, covering computer vision and natural language processing domains.
Data Labeling in Computer Vision (Images & Video)
Computer vision deals with visual data, such as images and video frames. Typical tasks include image classification, object detection, segmentation, facial recognition, and object tracking.
Image Classification
In image classification, each image receives a single label assigned by an annotator without the need for detailed region-level annotations. For example, a chest X-ray may be labeled simply as “pneumonia” or “normal.”
To make this process efficient, annotators typically use lightweight, web-based tools. These tools display a predefined list of class labels. They allow annotators to select the correct label with minimal cognitive effort, quickly.
Tagging, a related technique, supports assigning multiple labels to the same image. For example, an image could be tagged as “beach,” “sunset,” and “people,” or its caption might be “a group of people walking on the beach at sunset.”
These captions provide valuable context and help train models that generate descriptions for accessibility tools. However, they are less commonly used when training computer vision models for tasks like segmentation or object detection, such as creating bounding boxes.
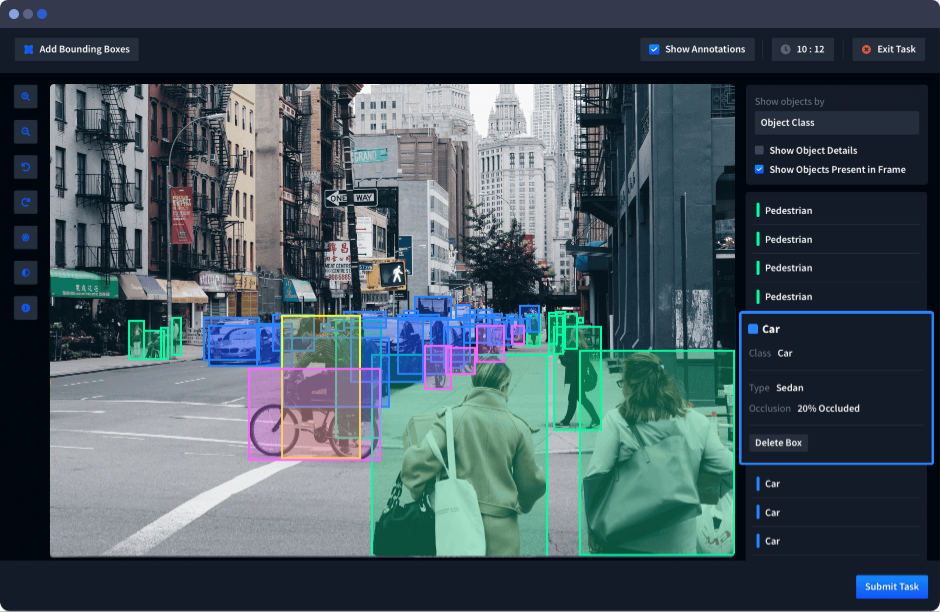
Object Detection
In image annotation, each object of interest is marked by a bounding box and labeled with its class name. The bounding box fits closely around the object and is assigned a label like “car” or “dog.”
For objects with irregular shapes, annotators might draw polygons instead of boxes. Rules help labelers decide how to handle objects that overlap. For example, common detection tasks in urban street scenes often involve cars, traffic lights, and pedestrians.

Image Segmentation
Image segmentation takes labeling a step further by assigning a class to every pixel. In semantic segmentation, each pixel is assigned a class, such as “road” or “sky.” Instance segmentation goes deeper by distinguishing each object within the same class, such as labeling each person separately in a group.
Data labelers use tools for polygon drawing, masking, and smart brushes. Some platforms offer model-assisted segmentation to pre-fill shapes.
Object Tracking in Video
Object tracking begins by annotating an object with a bounding box in the first frame and then tracking those same objects in subsequent frames. This process can be done manually or with the help of interpolation and motion prediction tools.
The aim is to track the same object over time, linking detection with consistency. Tools like CVAT or Labelbox help assign IDs, use optical flow, and transfer annotations. These features save time while maintaining accuracy.

Why Data Labeling is Critical for ML
Model performance in computer vision and natural language processing tasks heavily depends on label quality. Poor labels create unstable results, while high-quality labels make machine learning models more reliable.
Here, we explain the importance of high-quality labeled datasets and their impact on machine learning (ML) models.
Necessary for Supervised Learning
Supervised ML models need labeled data to learn. Without labels, the model can’t know what to look for or how to make decisions. For example:
- A spam filter learns from emails labeled “spam” or “not spam.”
- An image recognition model learns from pictures labeled with objects like “car” or “tree.”
Impact on Model Performance
Irregular or noisy labels can lead to poor training signals and degrade the model’s performance and generalization ability. A decrease in the label accuracy can lower the model’s performance.
This is a clear example of the “garbage in, garbage out” principle. If your model is trained on inaccurate ground truth, it will eventually learn wrong patterns.
💡Pro Tip: If your dataset includes histology images and you want to ensure balanced sampling and robust validation, our Lightly-Train Histology Benchmarks article shows how to curate and benchmark histology datasets successfully.
Enhance Predictive Capabilities
Fine-grained labels act as guides, directing the model to focus on important and subtle features during training. It helps the model to identify patterns and relationships precisely, making its predictions more accurate.
For example, training a model to detect vehicles works better when the dataset includes multiple features, such as vehicle type, weather conditions, and location.
Pro Tip: Models that use high-quality embeddings can learn more effectively and generalize even with fewer examples. It is valuable when labeled data is challenging to obtain, as embeddings allow the model to learn richer features from smaller datasets.

Helps with Assessment and Observation
A labeled dataset is a benchmark for evaluating the model’s predictions against the ground truth. After deploying the model, regularly updating it with fresh labeled samples helps catch any performance drops.
For example, in manufacturing, products are inspected for defects using machine learning models. Frequently labeling a sample of product images helps the model spot defects and maintain the product’s high quality.
Interprets Data for People and Creates Models
Developing annotation categories makes it easier to express the key elements in the dataset. For instance, grouping customer reviews by sentiment (positive, neutral, negative) helps sort through subjective data and discover insights beyond learning.
Required for Deep Learning (Big Data)
Modern deep-learning models require large amounts of labeled data. For example, image classifiers can require thousands of labeled images for every class. In contrast, translation and sentiment analysis models need a large labeled text corpus.
Fortunately, several open-source datasets are available for training deep learning models. For example, ImageNet, with its roughly 1.2 million labeled images in 1,000 classes, allows neural networks to learn from rich representations.
Cost/Benefit Trade-Off
Better labels result in better models, which create business value by providing more accurate predictions, better automation, and an improved user experience. But some data points can be left unlabeled.
Active learning, programmatic labeling, and semi-automated quality assurance reduce the workload while keeping quality high. The goal is to focus on labeling the most informative samples using active learning or data pruning. This helps strike a balance between thorough coverage and cost efficiency.
Data Labeling Tools and Platforms
Choosing the best data labeling platform can have a major impact. It makes annotations more accurate, speeds up the labeling, and helps expand the project.
Below are some key elements to look for in a labeling platform:
- Support for Annotation Types: The platform should handle annotation types that include bounding boxes, text spans for NLP, and 3D point clouds. For example, tools like CVAT are good at CV tasks, and Label Studio can deal with various kinds of data. You can also check out Lightly’s open-source project Labelformat which allows for label conversion.
- Interface and Usability: A user-friendly interface with quick controls will enhance the labeler’s effectiveness. Commercial platforms like SuperAnnotate offer advanced tools for annotation, enabling team members to collaborate in real-time.
- QA Workflows: Label accuracy can be enhanced by using consensus, various audit modes, and feedback loops. Tools like Appen and Labelbox offer well-structured QA processes.
- Integration and Scalability: If your data is large, make sure the platform allows for quick integration and scalability. Commercial platforms like AWS can handle large projects with fast data transfers and simple API access.
- Security: Look for tools that provide data encryption, access control, and compliance features if you are managing sensitive information. Open-source tools mostly rely on users to set them up, while managed services are designed with strong security features.
💡Pro Tip: If you are choosing an annotation tool for your labeling workflow, our Lightly vs. CVAT comparison explains how both tools differ in automation, usability, and data quality.

Most platforms are open-source or commercial, with some providing managed services and others combining automated and manual labeling. Here, we compare popular labeling tools and platforms.
Human Workforce for Data Labeling: In-House vs Outsource vs Crowdsourcing
Labeling can be done automatically, manually, or using a combination of both, depending on the project's needs. Also, different stages of the ML process may require different labeling models based on data sensitivity, volume, and available resources.
For instance, sensitive information often requires manual labeling for accuracy, but large data can be handled efficiently with automated tools. Here, we compare the strengths and weaknesses of each approach to help you choose the best fit for your project needs.
Choosing the right labeling approach often means mixing methods. For example, you might begin with your in-house team to get a good feel for the data and task, then outsource the larger bulk once your instructions are clear. Or you could rely on a vendor for most labeling, but have your team check the quality of some samples.
Sometimes, crowdsourcing is used for a quick first pass, with your in-house team reviewing tricky parts. The best choice depends on the size of your dataset, your budget, the privacy of the data, the quality you need, and the speed you want the results.
Challenges in Data Labeling
When you ship your model to production, you understand that labeling can be slow, costly, and messy. Tooling may seem perfect at first glance, but most teams encounter problems when they work at a larger scale and need quality. Some challenges include:
Scale and Volume
Labeling 10,000 images differs significantly from labeling 100,000. Maintaining the same taxonomies and correct categories becomes difficult as the dataset increases. A poorly designed labeling process may result in imbalanced class distribution, making it necessary to retrain the models.
Label Quality and Consistency
Label quality suffers when multiple annotators label the same data, especially for subjective descriptions. Any data that requires subjective descriptions, such as art or social media content, can face similar problems.
It is important to have clear guidelines to ensure uniformity in labeling, which enables the model to perform more effectively.
Ambiguity and Subjectivity
Labels become messy when objects overlap, are partially hidden, or their meaning depends on context. A tweet such as “another Monday” could be marked as positive, negative, or neutral without the right context. A certain degree of subjectivity is inevitable if the instructions are clear.
Class Imbalance and Edge Cases
If your dataset contains 1% “bicycle” data and the rest “car” data, the model will ignore the minority class. This is why it is important to ensure data balance. Techniques like active learning can help surface those rare samples so your model can learn during training.
Bias in Labels
Bias in data is often due to the way data is labeled rather than the data itself. Unclear task definitions, uneven class representation, and cultural differences can all skew results. For example, a sentiment containing the word “awesome” may be interpreted as sarcastic or negative, depending on the context.
Tooling and Infrastructure Issues
Scalable workflow annotation depends on effective tooling. Teams often end up with messy workflows when they don’t have the right tools, like 3D labeling or grouped labels. For example, exporting from CVAT to Excel just to count bounding boxes shows a workflow gap.
Continuously Changing Data/Requirements
Labeling systems must keep pace with changes to labels or categories. For example, if “neutral” is split into “neutral-positive” and “neutral-negative,” models trained on old labels might fail. Managing these changes carefully avoids confusion downstream.
Quality Monitoring at Scale
As the volume of labeled data grows, manual QA doesn’t increase efficiency. To maintain accuracy, it’s important to automate quality monitoring and track changes over time. Reviewing a small sample size, even 1%, using stratified sampling can catch label issues early before they scale.
Future Trends
As models require more data and edge cases become increasingly critical, the data labeling process is also evolving. Smart, connected, and model-driven processes are replacing traditional, manual methods for labeling images and data.
Here are the key trends shaping the future:
- AI-Powered Labeling: Many platforms now provide automatic labeling, model recommendations, and confidence-based systems to accelerate annotation. As a result, human-in-the-loop pipelines have become a standard approach rather than an optional enhancement.
- Programmatic and Weak Supervision: People now use rule-based labeling and labeling functions Such domains are ideal for unsupervised learning, as it is challenging to label them all manually.
- Synthetic Data Generation: Simulated worlds are now commonly used when building vision systems for robots or autonomous machines. Synthetic data ensures classes are balanced, makes rare events visible, and allows training models with data that is either scarce or needs protection.
- Labeling for Advanced AI Models (RLHF and Beyond): Labeling goes beyond simple tagging, especially for large language models and techniques like RLHF. It involves ranking and aligning outputs with human preferences to optimize for alignment with real-world user intent.
- Data-Centric AI Tools: The focus in AI is now on data rather than models, as better data enables the model to perform more effectively. Therefore, new methods must be introduced to identify inaccurate labels, eliminate unnecessary data, and focus on data that provides the latest information.
- Real-time Labeling and Edge Cases: Labeling is becoming faster and more flexible with live feedback during production. Real-time updates help identify and address rare or unexpected cases promptly. This trend requires tools that adapt on the fly and maintain accurate models.
Pro Tip: Model-driven labeling is becoming common due to contrastive learning. You can use this to train models with unlabeled data and speed up your process without affecting the quality.
How Lightly AI Simplifies the Process of Labeling Data
Lightly AI simplifies labeling data by incorporating intelligent data management and automation in machine learning pipelines. This approach builds on techniques like self-supervised learning and active learning.
- LightlyTrain helps with self-supervised pre-training on data from a specific domain using SimCLR and DINO. This method allows models to pick up useful representations independently, so fewer labels are needed. LightlyTrain works well for classification, detection, and segmentation tasks.
- LightlyOne uses innovative data selection methods to improve the labeling process. Using similarity-based filtering and active learning techniques, it chooses which samples to include and ensures the data is not redundant. LightlyOne makes labeling less expensive and improves the model's performance.
Conclusion
Good-quality labeled data is the key to building accurate and reliable machine learning models. Automation and new data methods are changing how labeling is done. Combining human work with smart tools helps make labeling faster and better. Creating strong labeling pipelines is key to handling more data and complex tasks. These investments lead to models that work well and improve over time.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)



{kind=link}
{kind=link}