LightlyTrain Introduces EoMT for Semantic Segmentation
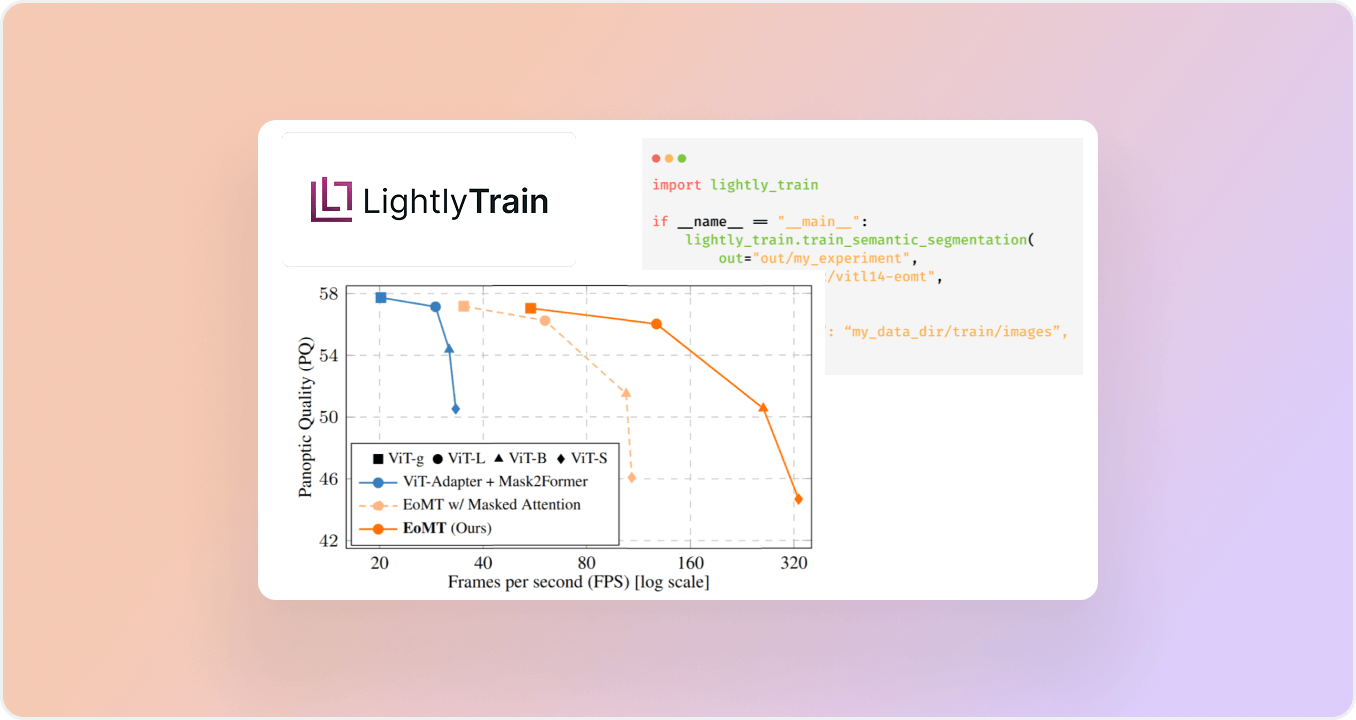
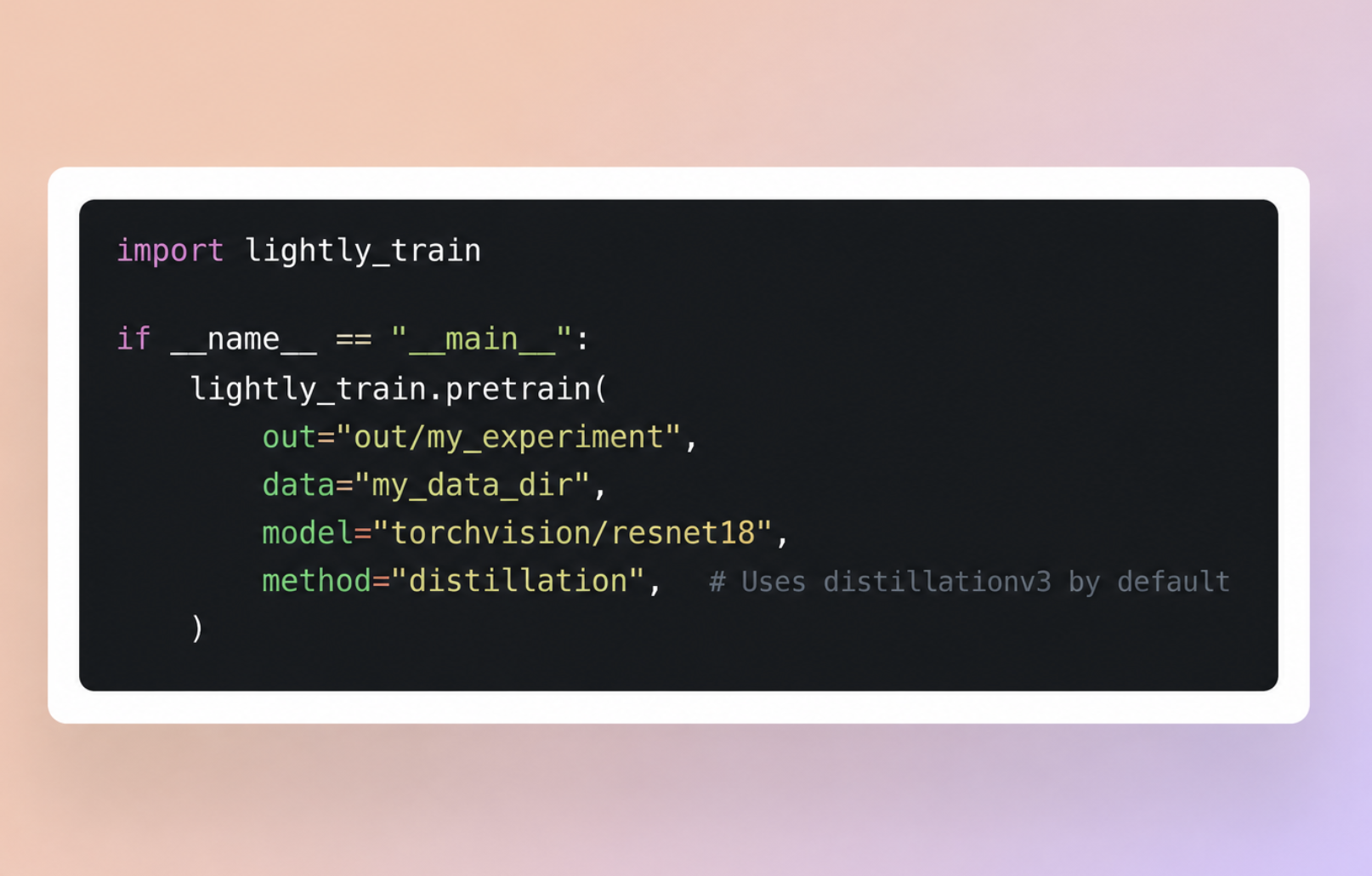
LightlyTrain now supports EoMT (Encoder-only Mask Transformer) for semantic segmentation. By removing decoder modules and integrating query tokens directly into the ViT encoder, EoMT simplifies design and boosts inference speed by up to 4× while preserving accuracy.
Get Started with Lightly
Talk to Lightly’s computer vision team about your use case.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
EoMT (Encoder-only Mask Transformer) is now available in LightlyTrain, enabling efficient semantic segmentation with transformer encoders. Unlike traditional architectures, EoMT removes decoder modules and instead injects query tokens directly into the ViT encoder. This simplifies the model design and improves inference speed by up to 4× while maintaining strong accuracy.







.png)

.png)
.svg)


