LightlyTrain Adds Support for DINOv3: Pretraining, Fine-Tuning, and Distillation Made Simple
LightlyTrain now supports DINOv3, bringing state-of-the-art self-supervised pretraining, distillation, and fine-tuning into a simple and flexible workflow.

LightlyTrain now supports DINOv3, bringing state-of-the-art self-supervised pretraining, distillation, and fine-tuning into a simple and flexible workflow.
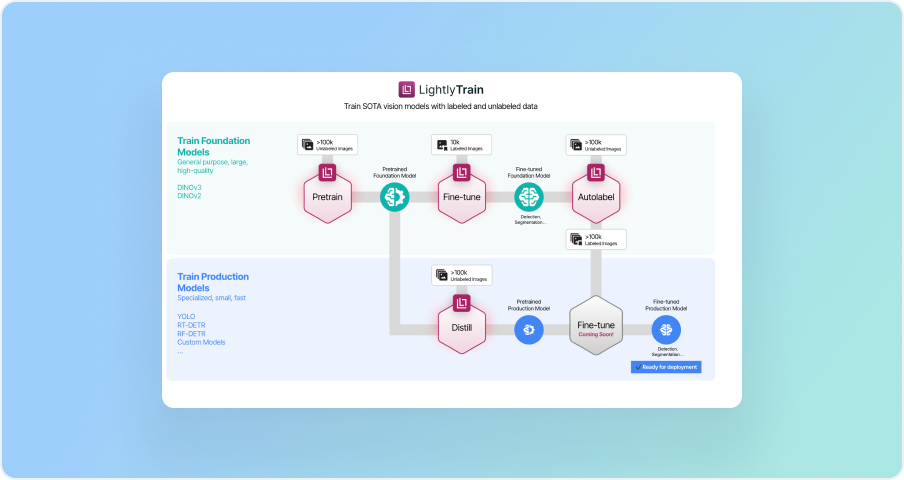
We’re excited to announce that LightlyTrain now supports DINOv3, the latest generation of self-supervised vision transformers. With this update, ML teams can take advantage of DINOv3 for distillation, pretraining, and fine-tuning, all integrated into LightlyTrain’s streamlined workflow.
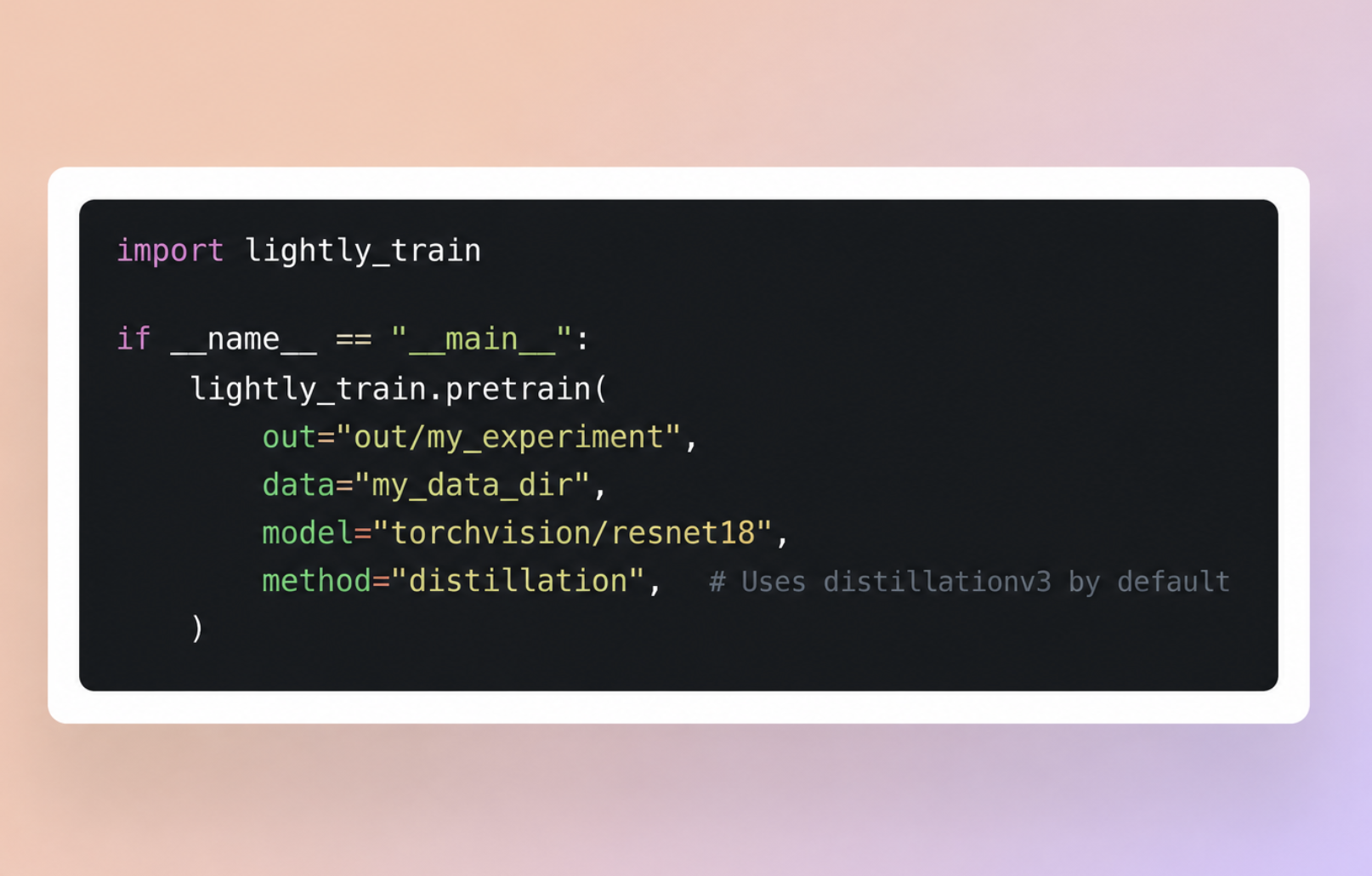
Just like with DINOv2, we’ve packaged DINOv3 into a simple-to-use solution that requires only a few lines of code to get started.
For more information about LightlyTrain, please check our documentation:
LightlyTrain lets you distill DINOv3 into any architecture, including YOLO, ResNet, RT-DETR, ConvNeXt, ViT, and custom models. This makes it easy to transfer the strong representation power of DINOv3 into your downstream tasks.
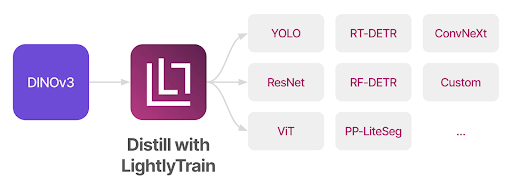
The code snippet below shows you how to get started, head over to the LightlyTrain documentation for more information.
Here’s how simple it is to distill DINOv3 into YOLO with LightlyTrain:
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="out/my_experiment",
data="my_data_dir",
model="ultralytics/yolo11",
method="distillation",
method_args={
"teacher": "dinov3/vits16",
# Replace with your own url
"teacher_url": "https://dinov3.llamameta.net/dinov3_vits16.pth"
}
)
We’ve also added support for EoMT, the new state-of-the-art semantic segmentation model originally built on DINOv2. By adapting it to DINOv3, LightlyTrain achieved a new SOTA on ADE20K with a ViT-L backbone:
Here’s how to fine-tune EoMT with DINOv3 using LightlyTrain:
import lightly_train
if __name__ == "__main__":
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov3/vits16-eomt",
model_args={
"backbone_url": "https://dinov3.llamameta.net/dinov3_vits16.pth",
},
data={
"train": {
"images": "my_data_dir/train/images",
"masks": "my_data_dir/train/masks",
},
"val": {
"images": "my_data_dir/val/images",
"masks": "my_data_dir/val/masks",
},
"classes": {
0: "background",
1: "car",
2: "bicycle",
# ...
},
# Optional, classes that are in the dataset but should be
# ignored during training.
"ignore_classes": [0],
},
)
With this release, LightlyTrain makes it easier than ever to integrate DINOv3 into real-world pipelines for detection, segmentation, and beyond. Whether you want to pretrain on your domain-specific data, distill into a custom model, or fine-tune for SOTA results, you can now do it all with just a few lines of code.
👉 Get started with LightlyTrain documentation.
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo


Self-Supervised Pretraining
Leverage self-supervised learning to pretrain models

AI Training Data for LLMs & CV
Expert training data services for LLMs, AI Agents and vision




.png)

.png)
.svg)