
LightlyTrain Benchmarks for Histology: SSL Pretraining and Segmentation
Table of contents
Share blog post



LightlyTrain sets new benchmarks for histology segmentation using self-supervised DINOv2 (Phikon-v2) pretraining and EoMT fine-tuning. The combination improves tissue boundary accuracy.
Share blog post
Find a quick overview of the key takeaways from this post below:
We’ve run new histology segmentation benchmarks with LightlyTrain. In-domain self-supervised pretraining with DINOv2 (Phikon-v2) consistently outperformed off-the-shelf models, showing the value of domain-specific representations.
When combined with Encoder-only Mask Transformer (EoMT) fine-tuning, performance improved even further, capturing fine tissue boundaries and complex structures more accurately. Both methods are now supported directly in LightlyTrain for real-world medical AI workflows.
Histology is one of the most demanding settings for computer vision. Whole slide images (WSIs) can span gigapixels, annotations require expert pathologists, and rare tissue patterns make datasets imbalanced. These factors make semantic segmentation especially difficult, and a prime use case for self-supervised learning and foundation model fine-tuning.
In this article, we share benchmark results showing how LightlyTrain supports medical AI teams working with histology data.
We evaluate two complementary strategies:
- In-domain self-supervised pretraining with DINOv2, which learns from large unlabeled histology datasets.
- Fine-tuning with Encoder-only Mask Transformers (EoMT), a segmentation architecture designed for ViT-based foundation models.
Both approaches are integrated into LightlyTrain, making them practical to apply in real-world medical AI pipelines.

See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Histology Segmentation: Data and Modeling Challenges
Histology, the microscopic study of tissues, is central to medical diagnostics. With the digitization of whole slide images (WSIs), computational pathology has rapidly emerged as a key application of computer vision.
Yet WSIs pose distinctive challenges for modeling:
- Scale: WSI size is typically in the order of 50,000 x 50,000 pixels, making direct processing infeasible without tiling or hierarchical strategies.
- Annotation scarcity: High-quality labels require expert pathologists, making them costly, time-consuming, and often limited to coarse slide-level granularity. Moreover, assigning labels sometimes depends on global slide context (e.g., tissue architecture or spatial relationships) that cannot be represented within small 224×224 tiles. As a result, there is a fundamental mismatch between available labels and model input, leading to inherently noisy supervision.
- Data imbalance: Rare disease patterns and subtle morphological cues are underrepresented in most datasets. In the supervised learning paradigm, this imbalance makes it notoriously difficult for models to learn strong and generalizable representations.
Together, these challenges make self-supervised learning (SSL) not only a natural fit but also demonstrably effective, as we show later, it outperforms natural-image pre-training by leveraging vast unlabeled datasets to learn rich tissue representations and reduce dependence on expensive annotations.
💡Pro tip: To boost representation quality in medical imaging, our An Introduction to Contrastive Learning for Computer Vision article explains how contrastive learning enhances downstream accuracy.
In-Domain Pre-Training vs. Off-the-Shelf Models
With the success of foundation models such as DINOv2 and DINOv3, a natural question arises:
Is domain-specific self-supervised learning (SSL) still necessary?
The answer is yes, especially in histology. Several factors highlight the value of in-domain pre-training:
- WSI tiling constraints: Because WSIs span gigapixels, they must be divided into smaller tiles for processing. In most workflows, these tiles are pre-embedded with a frozen encoder, and only the aggregator, typically a multiple-instance learning (MIL) method is trained. Updating the tile-level encoder itself is often computationally intractable at WSI scale. As a result, foundation models pre-trained on natural images may underperform in this frozen setting, since they cannot adapt to capture the subtle, domain-specific variations in tissue morphology.
- Domain shift: Models pre-trained on natural images can transfer reasonably well when fine-tuned, but their effectiveness is limited when used as frozen encoders under strong domain shift.
- Legal and regulatory considerations: In medical AI applications, reliance on models trained on non-medical data may introduce certification and compliance risks, making domain-specific pre-training more favorable.
These challenges have motivated the development of histology-specific foundation models such as UNI, UNI2, Virchow2, Phikon-v2, and H-optimus. Their emergence provides strong evidence that in-domain SSL delivers tangible benefits over off-the-shelf alternatives. To verify this claim, we focus on Phikon-v2, a ViT-L/16 model (without registers) pre-trained with DINOv2 on over 460 million pathology tiles, predominantly from breast tissue.
Qualitative Assessment of Retrieval Capabilities
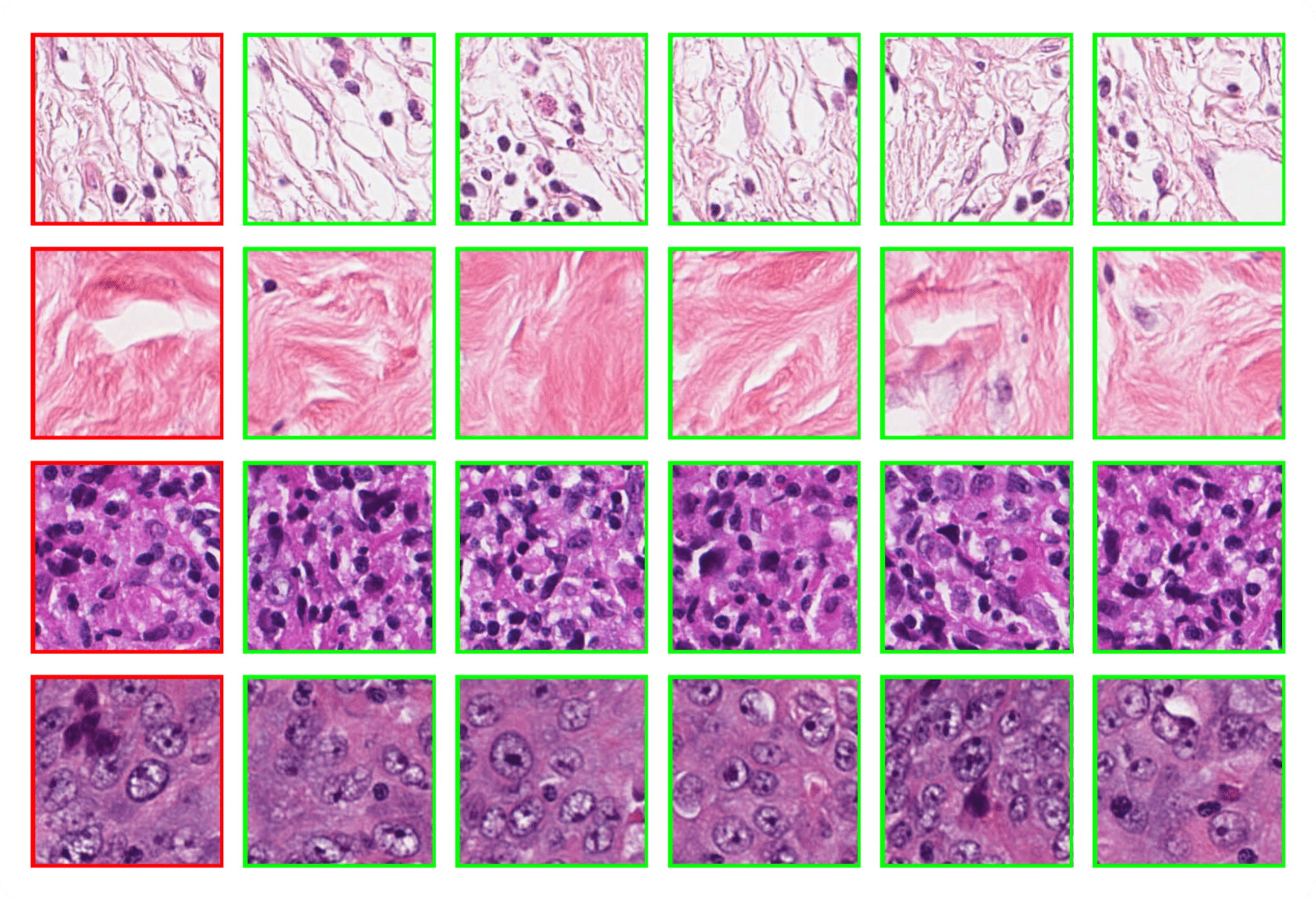
Our first experiment evaluates the retrieval capabilities of Phikon-v2 using the Breast Cancer Semantic Segmentation (BCSS) dataset. For each 224×224 validation tile, we compute embeddings with Phikon-v2 and retrieve its nearest neighbor from the training set based on cosine similarity.
The results, shown in Figure 2, demonstrate strong semantic consistency between queries and their neighbors. This suggests a practical scenario in which a pathologist could query a new WSI with representative tissue patches to automatically surface regions of interest, thereby assisting diagnosis. Such an approach is particularly appealing because it requires no additional training.
Interestingly, this strong k-nearest neighbor (k-NN) capability naturally emerges in self-supervised vision transformers (ViTs) and was first observed with DINO.
Linear Segmentation
To obtain a quantitative measure of the benefits of self-supervised learning, we compare Phikon-v2 with a comparable DINOv2 ViT-L/14 model. Both models are used without registers, since Phikon-v2 itself was trained in this configuration, and we opted for the same setup with DINOv2 to ensure a fair comparison. Using the BCSS dataset at 512×512 resolution, we then train a linear layer on top of each frozen encoder.
As shown in Figure 3, in-domain pre-training proves advantageous. It is worth noting that both models were evaluated at the same input resolution, which actually disadvantages Phikon-v2: its larger patch size results in a shorter sequence length. A fairer comparison would set the resolution such that both models operate at the same sequence length, and therefore comparable computational budget. Under this setting, Phikon-v2 would likely achieve even stronger performance, since in the current setup it is constrained by fewer tokens.
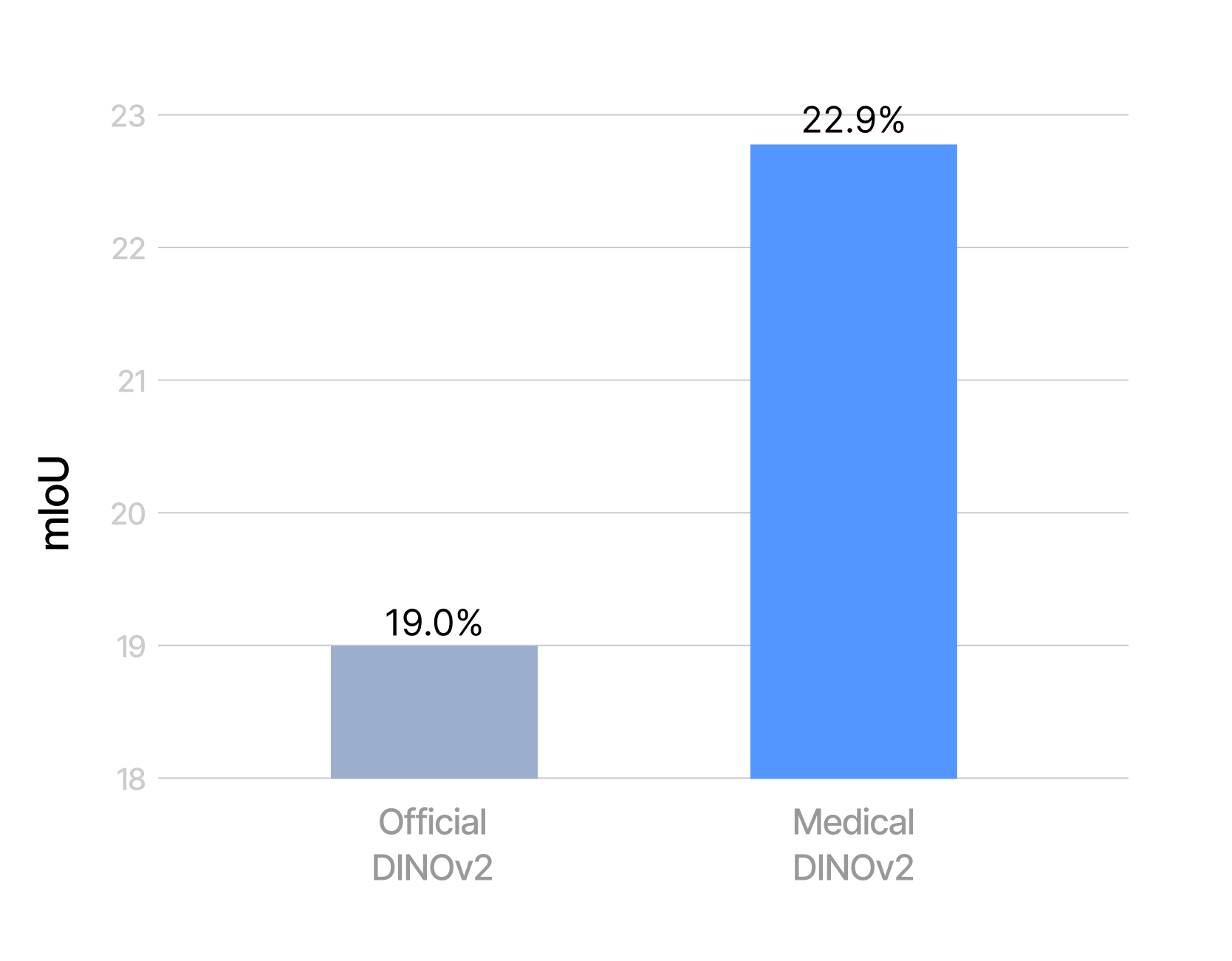
Overall, this benchmark remains highly challenging. In particular, we report results in the most difficult setting, i.e., without grouping related classes.
Going further with Encoder-only Mask Transformer
As seen in the previous task, fine-grained semantic segmentation of histology tissue is highly challenging, and strong performance requires fine-tuning with a dedicated architecture. For this purpose, we adopt the Encoder-only Mask Transformer (EoMT), a recent segmentation model designed specifically for ViT-based foundation models, offering high accuracy without compromising speed. EoMT training is supported in LightlyTrain, making it easy to apply this approach in practice. For a deeper dive into the architecture itself, see our dedicated blog post.
💡Pro tip: For stronger mask-based supervision in medical workflows, our Segment Anything Model and Friends article shows how foundation segmentation models can support complex tissue analysis.
Using the BCSS dataset at 512×512 resolution, we fine-tune Phikon-v2 with EoMT. On two B200 GPUs, a single epoch over the 6,000 images takes about one minute, comparable to the runtime of training a linear head on a frozen backbone. However, in the fine-tuning regime we run 40k optimization steps, which is roughly 3.5× more than in the linear segmentation experiment. The results, shown in Figure 4, demonstrate that in-domain pre-training and EoMT fine-tuning compound to deliver the strongest performance.
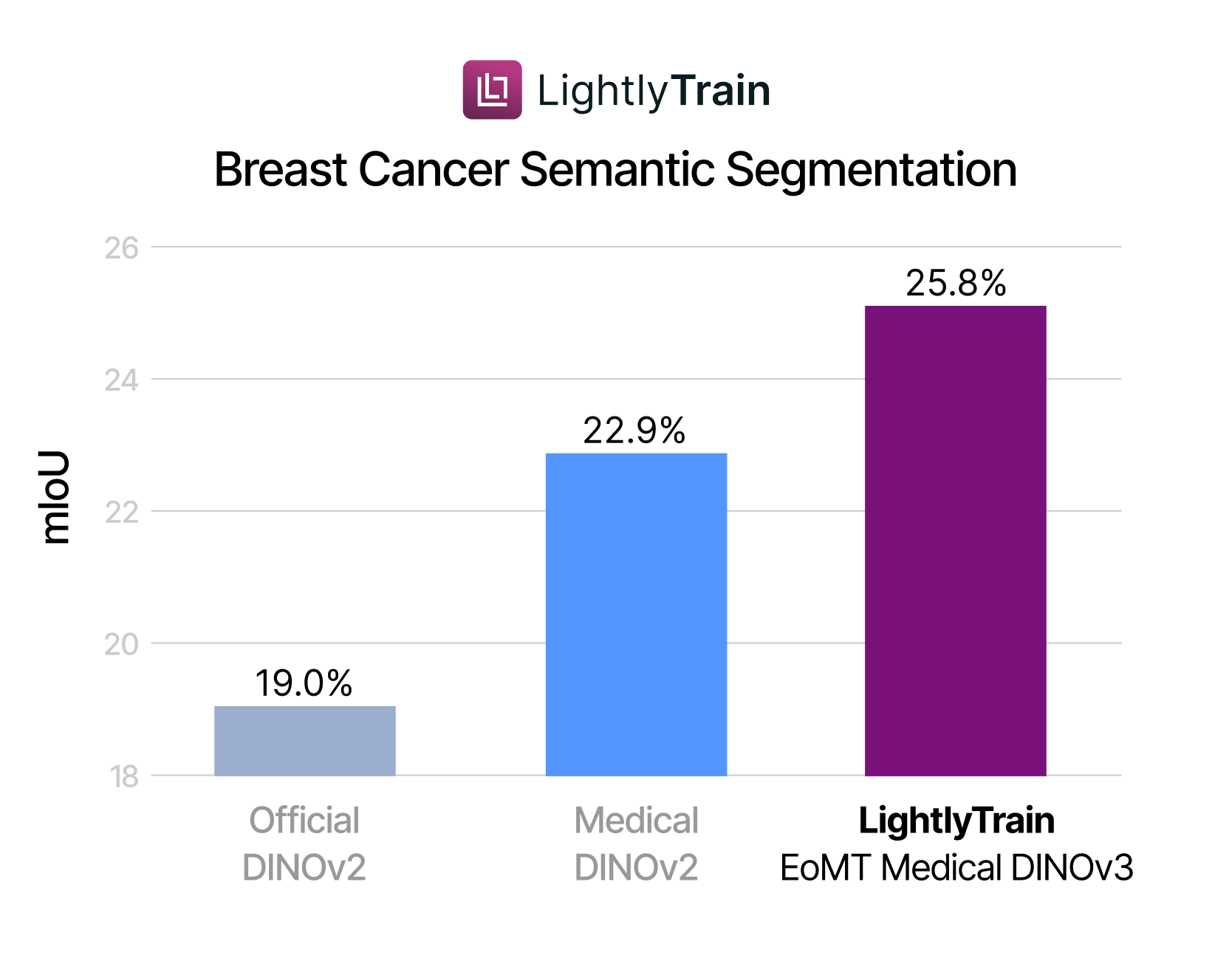
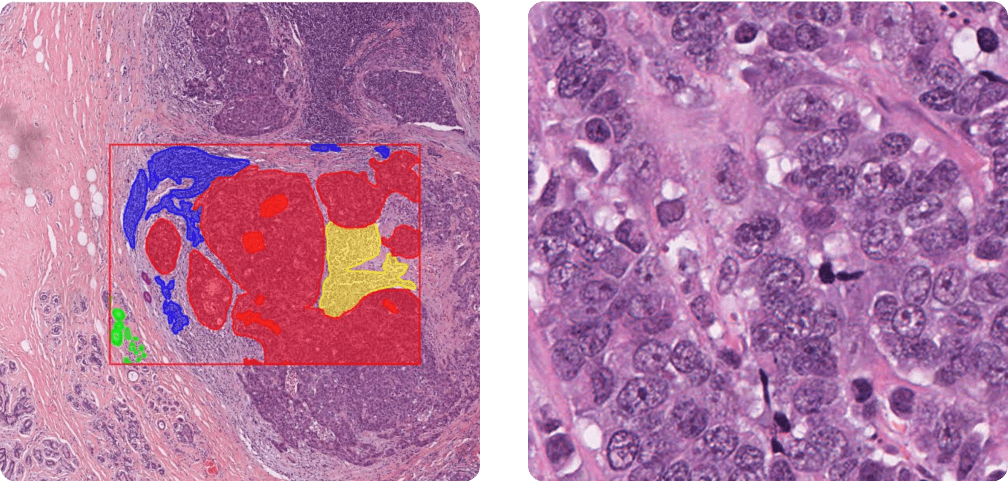
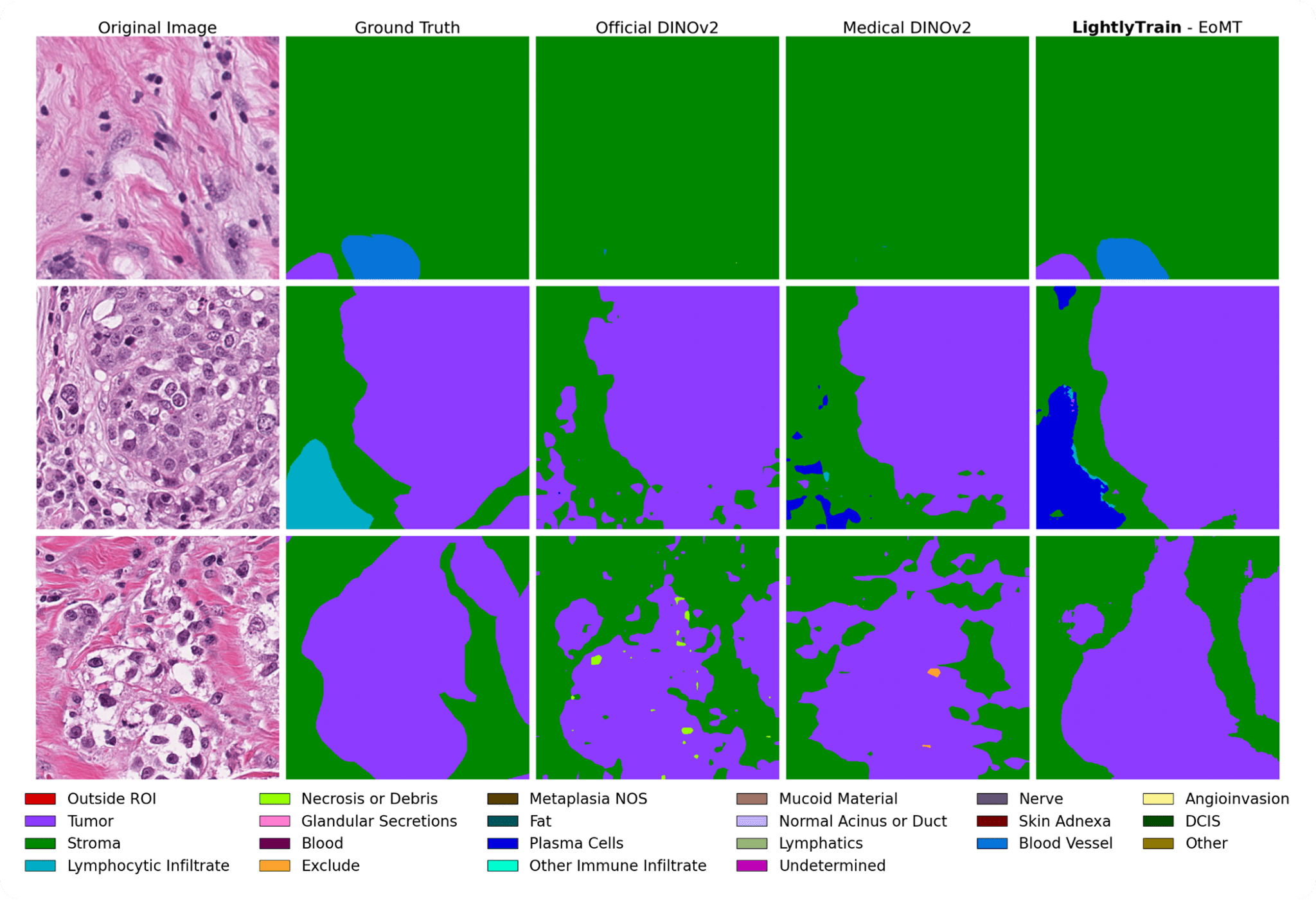
In Figure 5, we qualitatively compare the predictions of different segmentation models. These visual results are consistent with the quantitative findings and also highlight the difficulty of the task: even in light of the annotations, it can be hard to delineate tissue boundaries for non-pathologists. Part of this difficulty seems to arise from ambiguity in the expected granularity of the masks, where fine-tuning appears especially beneficial.
💡Pro tip: For label-efficient medical workflows, our Active Learning Strategies Compared for YOLOv8 on LincolnBeet article outlines selection methods that reduce annotation cost while boosting model performance.
Indeed, in the fine-tuning regime with a dedicated segmentation head, the model has the opportunity to base its predictions not only on local features but also on neighboring predictions. This mechanism is well captured in EoMT’s architecture, where predictions and patch representations are refined together in a multi-stage manner.
The best-performing model (LightlyTrain - EoMT) still makes errors, but these are interpretable. For instance, it sometimes confuses “other immune infiltrate” with “plasma cells”, two categories that the BCSS authors note can both be grouped under the broader class of inflammatory infiltrates.
Conclusion
Working with histology data means dealing with gigapixel-scale WSIs, limited expert annotations, and complex tissue structures, all of which make semantic segmentation a difficult task. In this post, we demonstrated two strategies that improve performance under these constraints:
- In-domain self-supervised pre-training with DINOv2, which unlocks the value of large unlabeled datasets.
- Segmentation architectures tailored for ViT-based foundation models, such as EoMT, which refine predictions beyond tile-level features.
Both of these approaches are supported in LightlyTrain. If you have a large collection of unlabeled data, you can pre-train your own foundation model in just a few lines of code. And if you already have a foundation model, LightlyTrain makes it simple to fine-tune it for segmentation with minimal effort.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


