
Teaching LLMs Swiss-German: Lightly’s Open-Source Project
Table of contents
Share blog post



Lightly is contributing to advancing AI in Switzerland with a Swiss-German dataset built on a small budget. Expanding on Apertus, Switzerland’s open-source LLM, the project shows how quality data curation drives multilingual AI progress.
Share blog post
Here is the quick summary of the points we have covered in this article:
We’ve decided to put our belief into practice: that great LLMs depend on high-quality data, not just compute. To prove this, our team set out three weeks ago with a sub 50K CHF budget to create a dataset and train a LLM not only Swiss German but also cultural knowledge.
- Challenge: Big LLMs for underrepresented languages
Big LLMs perform poorly once you move away from English, French, Spanish and similar widely-spoken languages. While big frontier labs have some models that work surprisingly well, the open-source-community lacks strong LLMs for specific underrepresented languages. Our team at Lightly thinks that creating good LLMs is all about good quality training data and not only the compute.
- Apertus as an example
Apertus is particularly well-suited for this demonstration because it's Switzerland's first fully open-source LLM, developed by EPFL, ETH Zurich, and the Swiss National Supercomputing Centre, and released with complete transparency, from training data and code to documentation and intermediate checkpoints.
It's designed with Swiss and European principles: transparent, EU AI Act compliant, privacy-respecting, and genuinely multilingual, with 40% of training data in non-English languages such as Romansh and Swiss German. This makes it the perfect canvas to showcase how strategic data curation can transform AI for underrepresented linguistic communities.
Introduction
In September 2025, Switzerland made a bold move: it launched Apertus, its first fully open-source large language model. Developed by EPFL, ETH Zurich, and the Swiss National Supercomputing Centre, Apertus is more than just another LLM, it’s a statement.

Everything about it is transparent: the code, the training data, the documentation, even the intermediate checkpoints. In a world dominated by black-box AI, Apertus opens the lid.
About Apertus
Apertus was trained on the Alps supercomputer with 15 trillion tokens, producing 70B and 8B parameter models. The project is driven by the Swiss AI Initiative, coordinated by EPFL and ETH Zurich with CSCS, and backed by partners like Swisscom. It performs on par with leading open-source LLMs like Meta's LLaMA 3 and France's Mistral, while distinguishing itself through radical transparency and stronger multilingual capabilities.
Though it may not yet surpass the very top proprietary systems, it represents Switzerland's ambition to build sovereign AI infrastructure that supports research, industry, and the wider community.
Why does this matter?
Because AI today isn’t just about performance, it’s about trust, sovereignty, and inclusion. Switzerland, with its tradition of neutrality and multilingualism, is positioning Apertus as a public digital good.
An initiative backed by national institutions, powered by the Alps supercomputer, and supported by strategic partners like Swisscom, the project already has momentum.
The pretraining alone on Alps cost 7 million Swiss Francs resulting in two variants: a 70B variant and a smaller 8B version. At 70 billion parameters, it stands shoulder-to-shoulder with Meta’s LLaMA and France’s Mistral, while distinguishing itself with radical transparency.
Think of Apertus as a foundation, it’s Europe’s chance to prove that open, multilingual, and compliant AI can be built in the public interest. The release is only the first step, but it sets the tone: Switzerland is ready to play big in sovereign AI.
Swiss-German in AI
Swiss-German is spoken every day, yet it’s largely invisible to AI systems. Most global models don’t support it, and that gap matters: if AI is going to be useful in everyday life, it should reflect the languages and cultures people actually use.
We want to change that.
Not through closed labs, but through community-driven, open-source AI. By collecting data together and sharing results openly, we’re proving that even smaller, underrepresented languages can find a place in modern AI.
And with Lightly being a Swiss startup, this is our way of contributing to the environment we’re part of. Switzerland now has its own open-source LLM with Apertus; by extending it to Swiss-German, we’re adding one small but meaningful piece to the country’s growing AI ecosystem.
We started small but concrete: together with volunteers and some external experts from our talent pool, we collected about 500 Swiss-German samples, short texts and speech snippets, and paired them with Standard German and English translations.
The result is still experimental, but it works: a model that better interprets Swiss-German, plus a demo UI where anyone can try it out and even submit new samples. Each new contribution makes the model stronger, and we plan to periodically release improved versions.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
How We Did It
If you just want to try out the model, you can find it here.
For those interested in the technical details, here’s a breakdown of our process:
Dataset Creation
We started by assembling a high-quality dataset of around 500 parallel samples.
Each sample contained:
- A question and answer pair in either English or German
- A corresponding Swiss-German translation of both the question and the answer
Screenshots of our data collection GUI. Available here.

This structure gave us aligned examples across three languages, enabling us to frame a wide range of tasks:
- Question answering in English, German, or Swiss German
- Translation in both directions (e.g. German ↔ Swiss German, English ↔ Swiss German)
- Mixed tasks, such as answering a question posed in English with a Swiss-German response
Swiss experts reviewed every entry. Their role went beyond translation:
- Linguistic review: ensuring the Swiss-German phrasing was natural and idiomatic
- Factual validation: checking correctness of Swiss-related content (history, politics, geography, landmarks, etc.)
The outcome was a dataset that balanced linguistic quality with cultural accuracy, rather than just literal translations.
💡Pro Tip: Even language aligned models benefit from visual data variety. Our Data Augmentation article shows how controlled transformations improve multimodal training stability.
Model Selection
For our base models we chose Gemma3 from Google (released in March 2025) because of its strong multilingual support and availability in different parameter sizes.
- We first used the 4B model for ablation studies and quick iteration.
- We then moved to the larger 12B model for higher-quality results once our approach was validated.
This progression gave us a good balance between efficiency on modest compute and strong multilingual performance.
Fine-Tuning Process
We fine-tuned Gemma3 using LoRA adapters. The setup details were:
- LoRA rank: 16
- Epochs: 2
- Batch size: 2 per GPU (8 total)
- Learning rate: 2e-4 with cosine decay
- Optimizer: AdamW
- Hardware: machine with 4× NVIDIA RTX 4090 GPUs
Our training process had two phases:
- Supervised fine-tuning (SFT): taught the model to handle Swiss-German tasks, but we observed a loss of general linguistic fluency
- Reinforcement learning with human feedback (RLHF): we applied direct preference optimization (DPO), which guided the model back toward fluent, high-quality responses without losing its Swiss-German skills
This two-step approach allowed us to combine task alignment with strong natural language output.
💡Pro Tip: Multilingual and multimodal setups face similar scaling challenges. Our Large Vision Models article explains why model size and pretraining strategy matter when extending models to new domains.
Evaluation
We noticed that model outputs were highly variable, making direct comparison difficult. To address this, we designed a three-stage evaluation pipeline:
- Eyeballing: we sampled responses at temperature 0 to reduce randomness and manually inspected outputs. This helped us quickly separate promising from weak candidates during both SFT and DPO.
- Automated evaluation with GPT-5: for each prompt–completion pair, we asked GPT-5 to rate grammar/style, truthfulness, and instruction following on a 1–5 scale. This gave us a large-scale, consistent quality measure.
- Expert evaluation: finally, two Swiss experts rated the models using a held-out benchmark set. The set included tasks across history, math, translation, and Swiss cultural knowledge. Ratings focused on:
- Truthfulness
- Grammar and writing style
- Instruction following
This layered evaluation gave us both breadth (automated judgments across many samples) and depth (expert human assessments), ensuring that improvements in Swiss-German handling did not compromise factual accuracy or overall usability.
How We Rated It
The rating was conducted by comparing responses from four models: Apertus and three of our fine-tuned models. All models were tested using prompts from three distinct categories, referred to as Prompt Labels:
Translation
This category includes prompts requiring the model to translate between:
- High German to Swiss German and vice-versa;
- English to Swiss German, and vice-versa;
Additionally, this category contains more complex prompts that are posed in one of these languages, include a question to be answered, and specify the language in which the response should be provided.
Calculation
These prompts consist of calculation tasks posed in Swiss German. Each prompt involves a mathematical problem with thematic ties to Switzerland, combining language proficiency with computational accuracy in a Swiss context.
CH Facts: Questions about Switzerland
This category comprises questions, posed mostly in Swiss German, that relate to Swiss culture and/or require knowledge about Switzerland. These prompts test the model's ability to understand general queries and provide accurate information about Swiss-specific topics.
Criteria
Each response was assessed across three criteria. The criteria are rated on a standardized five-point scale.
The goal of these criteria is to measure the model’s effectiveness across different aspects: what is said (Truthfulness), how it’s said (Grammar & Writing Style, Verbosity), and whether it follows instructions given by the user (Instruction Following).
Criterion 1: Grammar and Writing Style
This criterion evaluates the linguistic quality, coherence, and readability of the response, including proper organization and skillful use of formatting. The criterion also penalizes repetitive writing.
Reasoning for this criterion: A response, regardless of how factually correct, is only valuable if it can be easily understood by the user.
Criterion 2: Truthfulness
This criterion assesses the factual accuracy and reliability of claims made in the response, distinguishing between primary claims (central to addressing the prompt) and secondary claims (supporting information).
Reasoning for this criterion: The primary utility of an AI model is to provide reliable information. If a response is factually incorrect it’s not just useless but potentially detrimental to the user who relies on the information.
Criterion 3: Instruction Following
This criterion measures how well the response adheres to the prompt's requirements and instructions, including whether all components are addressed and the response is delivered in the correct format.
Reasoning for this criterion: A model must be controllable and capable of meeting specific user needs. This criterion assesses the model’s ability to act as such a tool.
Scoring System for the Criteria
Each of these three criteria was rated using a five-point scale with the following labels and corresponding normalized scores:
- Very Bad (0.00)
- Bad (0.25)
- Okay (0.50)
- Good (0.75)
- Very Good (1.00)
This normalized scoring system allows for quantitative comparison between models and facilitates statistical analysis of performance differences across criteria and prompt categories.
Average Score
For each prompt, two qualified raters assigned scores on the normalized 0–1 scale explained above. We first average the two rater scores per criterion to obtain a single Truthfulness, Instruction Following, and Grammar & Writing Style score for that prompt. We then compute an Overall Quality score as a weighted average that reflects the priorities of our evaluation: Truthfulness (weight = 4), Instruction Following (weight = 3), and Grammar & Writing Style (weight = 2). Formally:
From those weights we can derive the following formula to compute the Overall Score of a single prompt:
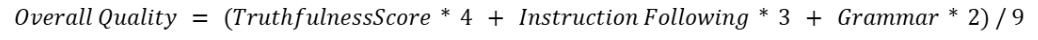
A model’s Average Score (AvgScore) is the mean of the Overall Quality scores across all prompts. The result is a consistent 0–1 metric (optionally scaled to 0–100) that enables fair comparison across responses and prompt categories while aligning the aggregate score with our evaluation goals.
💡Pro tip: When working with multilingual or dialect-rich datasets, our Efficient VLM Training blog shows how VLMs accelerate alignment between text and visual content.
Results
With ~500 curated Swiss-German samples, we fine-tuned Gemma3 and the change is immediately noticeable in real use. Our goal was to show how a small, but high-quality, dataset can steer a capable base model toward a local language.
That’s exactly what happened, as you can see in the table below.
Translation is where the gains show first
The fine-tuned Gemma3 follows language instructions more reliably (staying in Swiss-German when asked, or switching cleanly to High German or English) and makes fewer code-switching slips.
Swiss knowledge lands better
On Swiss-centric questions, answers are crisper and more accurate. This mirrors our data recipe: every example was linguistically reviewed and Swiss-fact-checked, so the model learned idiom + context, not just words.
Reasoning remains a big-model strength
For arithmetic-style prompts, large generalist models like Apertus still have an edge. That’s expected—our 500 examples weren’t designed to shift raw reasoning, but to elevate dialect handling and cultural grounding.
How to read this
The DPO-tuned Gemma3-12B became our most dependable option for Swiss-German tasks. It doesn’t “win” everywhere, but where dialect comprehension and instruction following matter, targeted data beats raw size.
💡Pro Tip: Check out our article, the Bias-Variance tradeoff in Machine Learning on how training data can affect a model
Why this complements Apertus
Apertus is a transparent, sovereign foundation - perfect as a public canvas. Our result shows how quickly any strong base (Apertus included) benefits from small, well-curated community data.
Scope and next steps
This was intentionally simple and public-facing: modest data, a lightweight rubric, and two human raters. We’ll open-source the data and the Gemma weights, keep collecting samples via the demo, and periodically release improved versions.
Conclusion
This initiative is still small, but it proves a bigger point: building AI doesn’t have to be the exclusive domain of big labs and closed systems. With openness, collaboration, and a bit of Swiss pragmatism, we can make AI reflect the languages and cultures that matter in everyday life.
Apertus gave Switzerland its first fully open-source foundation model. With our fine-tuning, we’re adding Swiss-German into the mix not as a finished product, but as a living project that grows stronger with each contribution.
Our promise is simple: we’ll keep collecting, keep improving, and keep sharing. We will make the data and the models available on HuggingFace Hub in the coming weeks.
Whether you’re a researcher, a developer, or just someone who loves Swiss-German, you can be part of it.
Together, we can show that even a small community can shape the future of AI.
👉 Test our model (to avoid abuse, you'll need to create an account)

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


