
An Introduction to Reinforcement Learning from Human Feedback (RLHF)
Table of contents
Share blog post



Reinforcement Learning with Human Feedback (RLHF) trains AI models using human preference data instead of fixed rewards. Combining supervised fine-tuning and reinforcement learning, it aligns outputs with human intent, boosting safety, quality, and user satisfaction.
Share blog post
Quick answers to common questions about RLHF:
What is RLHF?
Reinforcement learning with human feedback (RLHF) is a method of training large language models with user feedback rather than with predefined reward functions. The model is trained on annotated data to build a neural reward model that aligns outputs with human values.
RLHF enhances safety and generative quality in natural language processing by combining supervised fine-tuning and reinforcement learning.
How does RLHF work?
The RLHF pipeline is a four-step process that uses supervised fine-tuning, reward model training, reinforcement learning, and iterative evaluation. Here's how it works:
- Supervised fine-tuning (SFT) involves adjusting a pretrained model with human data to align outputs with human intent.
- Annotators rank model responses to obtain data that trains a neural reward model to predict numerical reward signals.
- Proximal policy optimization (PPO) and reinforcement learning fine-tune the model to maximize rewards and align better with human feedback.
- Lastly, iterative assessment on held-out preference tasks refines the reward model, tunes hyperparameters, and prevents reward hacking.
Why is RLHF important?
RLHF enhances the safety and usefulness of large language models by aligning their actions with human intentions and reducing undesirable biases. RLHF training improves AI systems' ability to generalize and increases user satisfaction by focusing on user preferences rather than rigid metrics.
ChatGPT and similar AI models use RLHF to generate answers that are contextually accurate and aligned with user expectations.
Where is RLHF useful?
RLHF is effective for large language model tasks that rely on human evaluation, such as chatbots, text summarization, and question answering. It also extends to computer vision, where it aligns text-to-image models with human preferences to improve the quality of generation.
RLHF uses human feedback to improve reinforcement learning policies so that AI behaves more intuitively and effectively in robotics and gaming.
What are RLHF challenges?
RLHF requires many human annotators, making data collection costly and time-consuming. Subjective preferences can bias the reward model, so diverse annotators and robust collection methods are essential.
Models can also exploit reward functions (reward hacking), which can be mitigated through iterative evaluation and reward regularization.
What are the RLHF Alternatives?
Direct Preference Optimization (DPO) simplifies RLHF training by skipping the reward model and training directly on human preference rankings. Reinforcement learning with AI feedback removes the need for human annotators. It uses AI evaluators to reduce annotation costs and accelerate model training.
Introduction
Scaling language and multimodal models creates new challenges in aligning them with precise human intent. Supervised fine-tuning often falls short when tasks are vague or underspecified.
Reinforcement Learning from Human Feedback (RLHF) uses preference-based optimization to align models with human intent. It improves outputs for tasks with ambiguous or underspecified objectives.
This guide covers:
- What is RLHF, and its importance
- How does RLHF work: the training process
- RLHF in action: applications and examples
- Tools and frameworks for RLHF training
- Challenges and limitations of RLHF
- Alternatives and recent advances in alignment
Structured user feedback is a core component of evaluation and training. It drives improvements in RLHF workflows and ensures models meet quality standards.
At Lightly, we deliver RLHF services, from high-quality, human-labeled evaluation data to fully managed, preference-driven training pipelines. We help teams enhance model safety, alignment, and real-world performance.
Get in touch to see how Lightly’s RLHF team can accelerate your AI projects.
What is RLHF and Why It Matters: The Basics
Reinforcement learning with human feedback trains large-scale models using preference signals to guide policy optimization.
Instead of fixed reward functions, RLHF relies on human assessments of model outputs. This makes responses more aligned, useful, and precise.
Key Components of an RLHF Pipeline
A full RLHF system has several core parts:
Base Model (Policy)
The pretrained large language model, usually a transformer, acts as the base policy. It is trained with self-supervised next-token prediction.
Supervised fine-tuning (SFT) then adapts it using selected preference labels, which helps the model to align more closely with human intent.
The model is pre-trained on billions of tokens from vast text collections. This allows it to grasp language patterns and context effectively. It is the initial supervised model for reward-driven optimization.
Human-based Feedback Data
Model responses to prompts are compared and ranked by human annotators to produce preference data. Annotation protocols are designed to maintain label consistency and reduce bias.
The reward model is trained using these ranked comparisons. Human input ensures that the outputs of the models are sensitive to a diversity of user values, intents, and contextual needs.
Reward Model
The reward model is a neural network trained to map prompt-response pairs to scalar preference scores. It is typically trained with a binary cross-entropy loss on pairwise human preference comparisons.
The resulting reward function gives numerical reward signals that guide policy optimization. The model is kept aligned by frequently retraining the reward function using new user feedback data.
Policy Optimization Algorithm
Policy optimization algorithms refine the base model to maximize the reward signal. They balance exploration and exploitation to stabilize and improve outputs.
Why is RLHF important?
RLHF training fills the semantic gap between model goals and human values by training reward models on human preference data. PPO with a KL penalty stabilizes updates while maximizing rewards that align closely with preference labels.
It reduces hallucinations and toxic outputs by guiding models to match user feedback more effectively than proxy objectives. This approach is more effective than relying on indirect or proxy objectives.
Iterative reward assessment and off-policy testing help prevent distributional drift. This keeps models consistent with evolving user expectations and requirements.
This approach helps deploy AI quickly in chatbots, summarization, and generative apps.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
How Does RLHF Work? The Training Process
RLHF uses human preference data in a structured, multi-stage process to align the output of large language models with human values. It converts qualitative judgments into scalar rewards. The model is optimized using PPO, adding stability constraints like a KL penalty.
Large deployments often use PyTorch or TensorFlow. They also use mixed-precision GPU training and distributed parallelism. This helps them train models with billions of parameters.
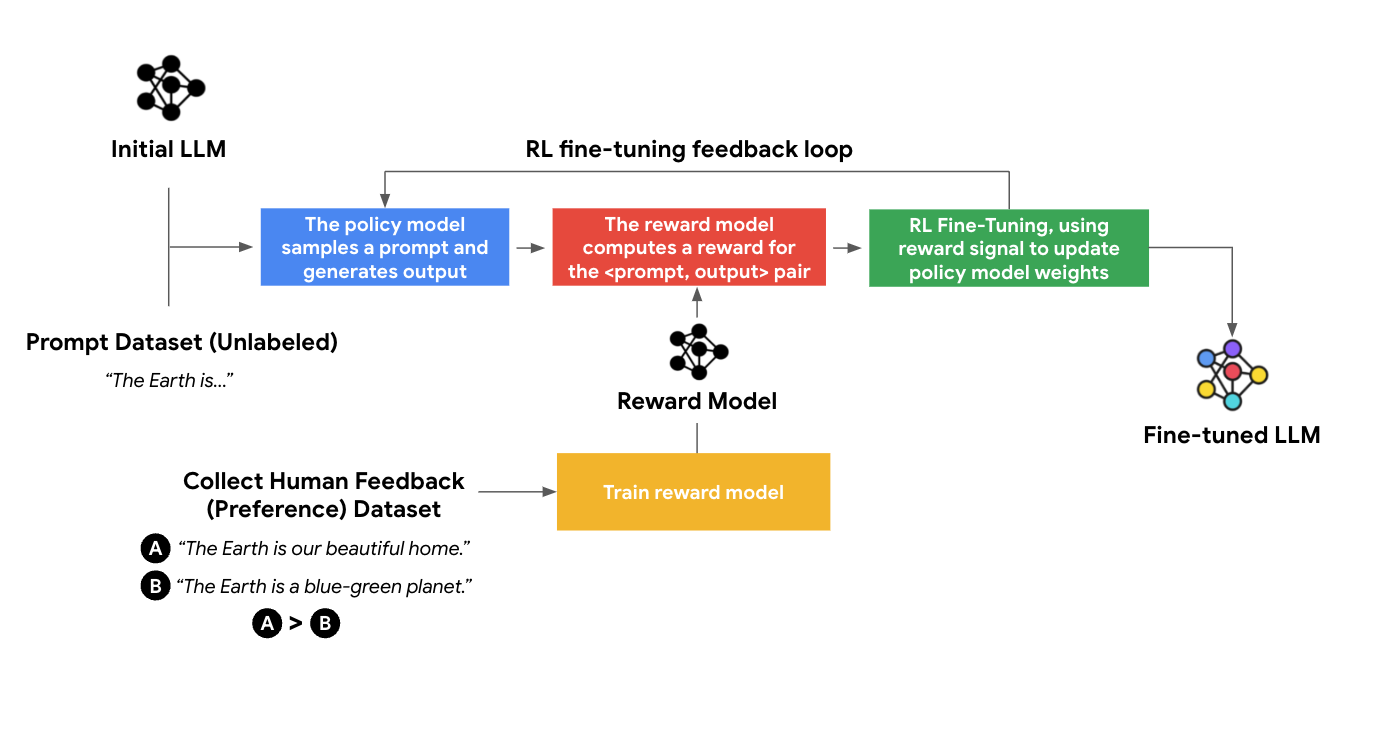
Let’s find out how it works step-by-step:
Data Collection & Supervised Fine-Tuning (SFT) of a Base Model
Gather quality datasets and apply supervised fine-tuning to build a strong, task-specific base model.
Purpose
Align the base model with human demonstration patterns and fine-tune it with curated data for PPO optimization.
Approach
Data gathering starts by collecting human responses or assessments from different prompt distributions. Annotators rank outputs in pairs or with Likert-scale ratings to create preference data.
Strict annotation guidelines and inter-annotator agreement measures help eliminate label inconsistency and subjective bias. SFT fine-tunes a pretrained transformer policy. It uses cross-entropy loss on prompt-response pairs from thousands of annotated examples.
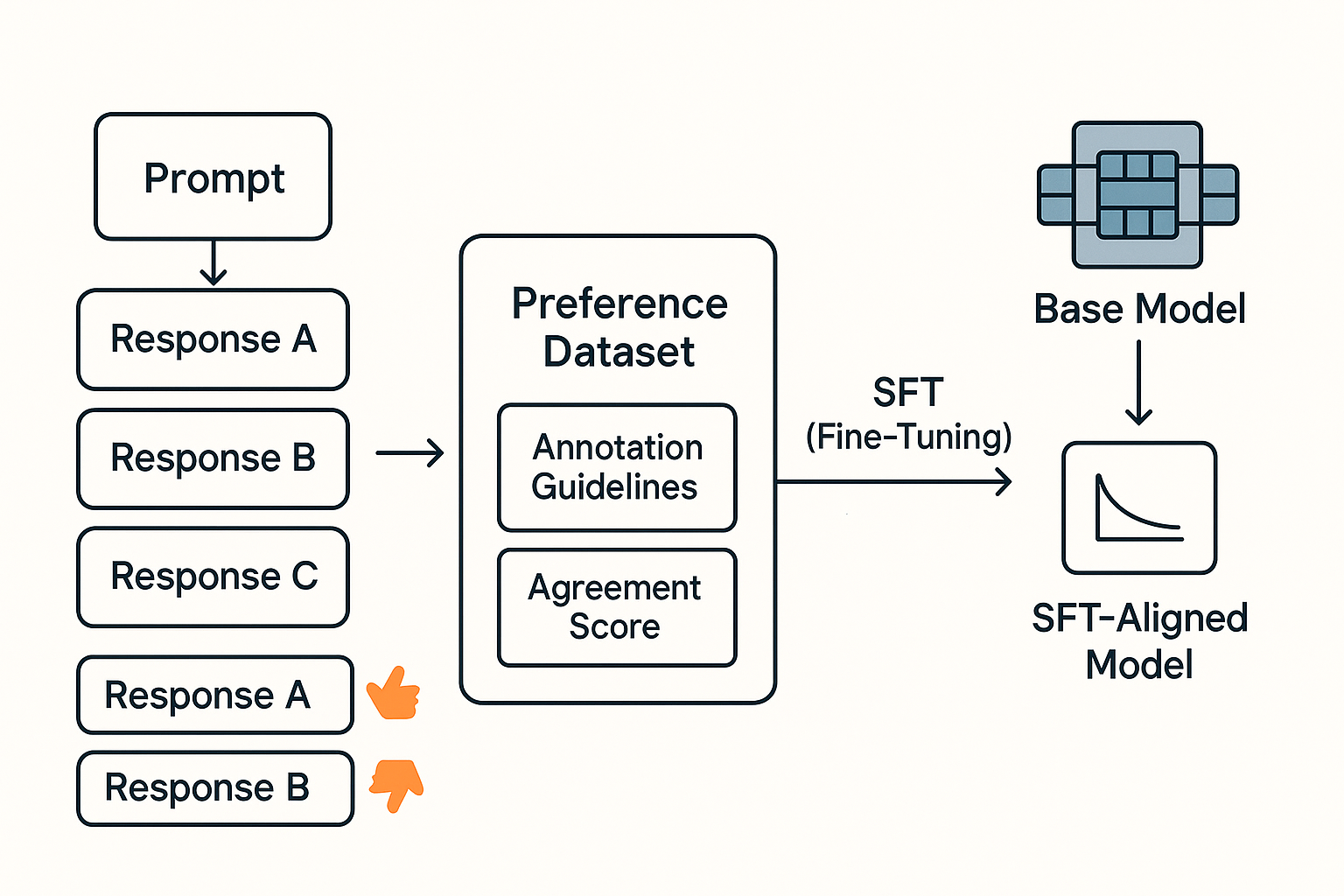
The common SFT hyperparameters are learning rates of 1e-5, batch sizes of 64, and weight decays of 0.01. The stage aligns the base model with human demonstration patterns. It then begins the PPO optimization process downstream.
Example
LLaMA-2 chat gathered human-written prompts and paired responses, with annotators ranking outputs via binary preference and safety veto labels.
The model was fine-tuned on around 27,000 prompt-response pairs. It used a learning rate of 1e-5, a batch size of 64, and a weight decay of 0.01 to match human style in demonstrations.
Pro Tip: Looking for the best labeling tool? Check out our 12 Best Data Annotation Tools for Computer Vision.
Reward Model Training
Next, we turn human preferences into a reward model.
Purpose
Train a reward model that accurately reflects human preferences. The model must remain stable against overfitting or data shifts.
Approach
The reward model mirrors the transformer backbone but adds a regression head to produce scalar scores.
It’s trained on pairwise preference data with a logistic (Bradley–Terry) loss, ranking preferred responses higher.
Dropout, gradient clipping, and L2 regularization help prevent overfitting. Calibration, like temperature scaling, keeps scores stable across runs.
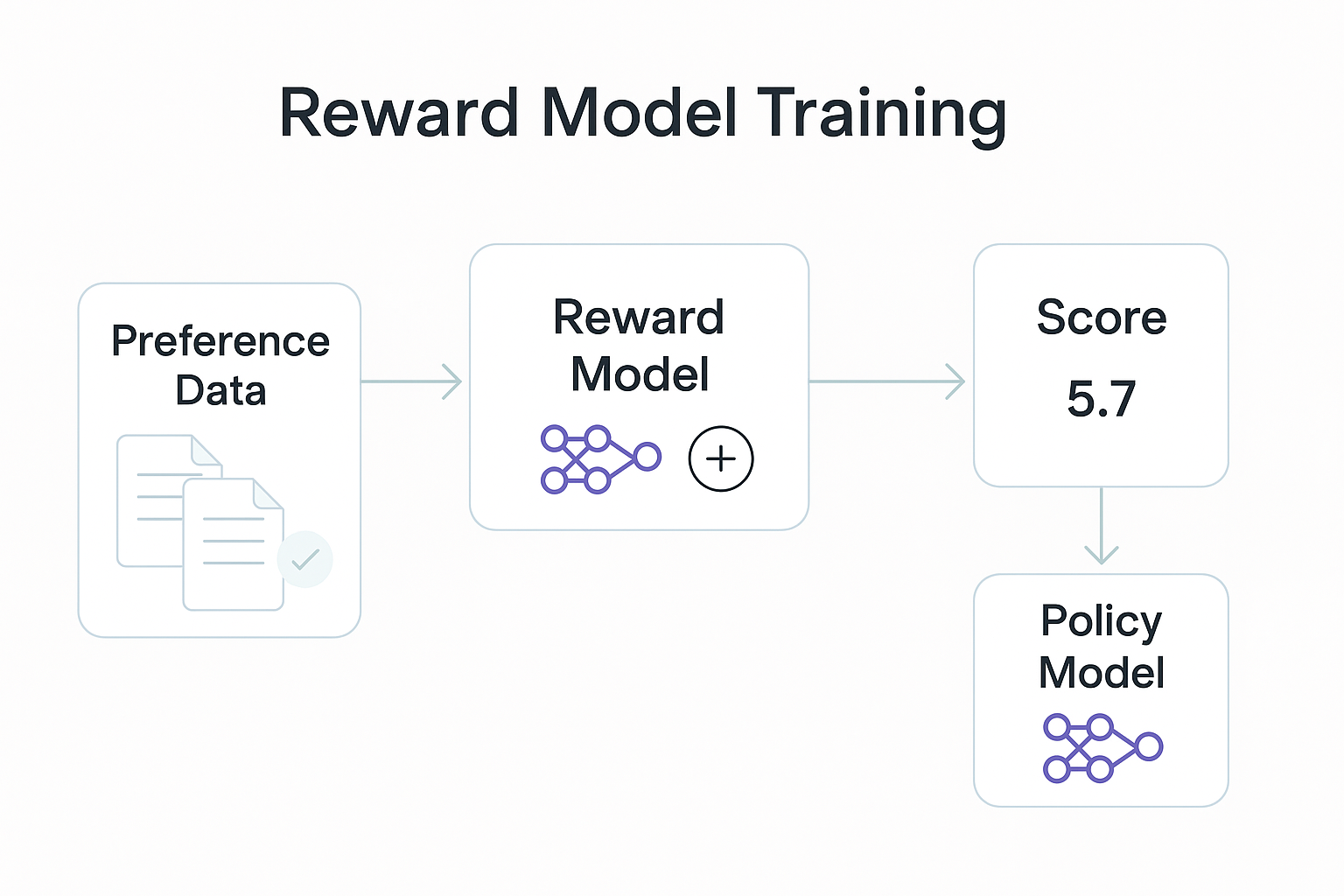
Regular retraining on new annotation batches helps resist changes in human preference data.
Example
A reward model was trained with a regression head on a transformer backbone using sentence-level preference annotations for long-form QA.
This detailed feedback helped the model improve its scoring outputs. As a result, it increased factual accuracy and reduced toxic completions.
Policy Optimization via Reinforcement Learning
The model is then refined via PPO to maximize rewards while maintaining stability against the SFT baseline.
Purpose
Enhance the model's responsiveness to human preferences. Maintain stability, clarity, and alignment with user expectations.
Approach
Policy optimization treats each token generation step as an action in a Markov Decision Process. It uses the learned reward as a signal and maximizes expected reward with a KL divergence penalty for stability.
The prompts and candidate completions are sampled in mini-batches to estimate advantage via a value-function baseline.
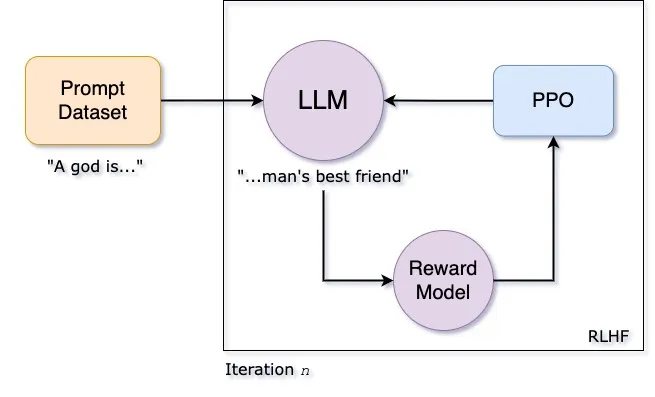
Entropy regularization boosts exploration. Gradient norm clipping with AdamW helps stabilize training on billions of parameters. Throughput is accelerated by mixed-precision arithmetic and gradient accumulation on multi-GPU clusters.
Example
RLHF is treated as a token-level MDP in the Reinforced Token Optimization (RTO) framework, with PPO optimizing token-wise rewards from a DPO-PPO pipeline.
This finer granularity improved alignment, beating sentence-level PPO by 7.5 on AlpacaEval 2 and 4.1 on Arena-Hard.
Evaluation and Iteration
Finally, continuous testing and retraining ensure alignment is preserved over time.
Purpose
Align with what people want, fix any gaps, and maintain strong performance. Regularly evaluate and refine your approach.
Approach
Alignment quality is measured through preference-agreement rates on a held-out set of human-ranked prompt-response pairs. Off-policy evaluation then estimates generalization to unseen inputs without needing extra annotations.
KL divergence is monitored against the SFT baseline to detect drift early. When drift is found, targeted annotation rounds and retraining are initiated.
Dashboards show reward distributions, loss curves, and user satisfaction. They give a clear view of model health and guide ongoing improvements.
Example
The ChatGLM-RLHF pipeline measured preference-agreement rates and monitored KL divergence to detect drift from the aligned policy.
They gathered feedback on failure cases repeatedly. Next, they retrained the reward model. This led to roughly a 15% boost in wins for Chinese dialogue preference.
RLHF vs. Traditional Methods
Let's look at RLHF and traditional methods together. This will show how they differ in reward design, adaptability, and sample efficiency.
RLHF in Action: Applications and Examples
RLHF uses human feedback for structured learning, aligning models with user values. This is especially valuable in NLP and computer vision, where matching human preferences matters more than raw power.
Large Language Models (Chatbots and NLP tasks)
Improving Multilingual Customer Engagement
Global customer support systems are turning to multilingual language models. These models connect people worldwide and translate words accurately. However, they often miss the tone and cultural nuances that affect how messages are received.
The HELM benchmark and BLOOM’s multilingual evaluations revealed that direct translations often missed cultural nuances, even when linguistically correct. For example, Japanese customer messages were sometimes translated too literally, losing intended politeness.
RLHF fine-tuning with native-speaker feedback corrected tone and preserved cultural appropriateness. Annotators selected translations aligned with meaning and norms, supported by a reward model.
This alignment enhanced user satisfaction in multilingual customer support. It highlights the importance of RLHF in developing culturally aware NLP systems.
Advancing Learning Reasoning
Tutoring systems in math, science, and writing need to answer questions, provide reasoning, and sometimes avoid giving direct answers to encourage learning.
For example, when asked, “How can I best solve this integral?” a base model might give the full solution. An RLHF-trained model instead offers guiding questions and hints.
Training data comes from interactions selected by educators. The best answers help with problem-solving instead of taking over.
Computer Vision
Vision-Based Preference Learning
Defining a numerical reward function is often impractical in vision tasks like image generation, captioning, or object arrangement. Questions such as “Is this image beautiful?” or “Does this movement look natural?” are better answered by people.
Diffusion-based models such as Stable Diffusion or DALL·E are trained to maximize likelihood on large datasets. Their outputs can still fall short in real-world use.
Human preference data bridges this gap. Annotators rate images for qualities like realism, composition, and prompt adherence.
These rankings train a reward model that scores outputs based on learned human criteria. The generator improves through reinforcement learning using PPO. The reward signal guides it to match user preferences.
Projects like Pick-a-Pic show how human feedback can notably improve visual quality without relying on hand-crafted loss functions.
Multi-Modal Alignment: Text and Vision in Harmony
Base models can often make mistakes in multi-modal tasks. This includes visual question answering, image explanation, or instruction following. Supervised fine-tuning helps, but cannot fully eliminate these errors.
RLHF-V addresses this with fine-grained human feedback, where annotators tag specific answer segments as correct, misleading, or irrelevant.
These segment-level preferences help the model train with Dense Direct Preference Optimization (DDPO). This method uses alignment signals for short spans and full outputs.
RLHF-V cut hallucinations by 34.8%, outperforming LLaVA-RLHF models trained on ten times more data, using only 1.4k annotations.
RLHF in Robotics: Matching Physical Behaviors to Human Preferences
Robots deployed in homes, hospitals, and warehouses encounter messy, dynamic, and deeply human-driven tasks. Many control systems and RL agents fail, not due to technical limitations, but from misaligned human intent.
New methods address this by embedding human feedback directly into training. The SEED framework (Skill-based Enhancements with Evaluative Feedback for Robotics) integrates human preferences into skills, removing hand-crafted rewards.
SEED decomposes tasks into primitive skills like grasping, rotating, or pushing, arranged in a skill graph. Annotators give feedback on individual skills, capturing precise intent with minimal oversight.
In trials, SEED-trained robots outperformed RL baselines in success, smoothness, and interaction efficiency.
SEED combines hierarchical learning with RLHF. This creates a practical and scalable way for robots to behave as humans want.
Tools and Frameworks for RLHF Training
Building an effective RLHF pipeline means balancing training data quality, reward modeling, policy optimization, and consistent human feedback.
As RLHF systems expand, specialized tools and platforms have been created. They assist in managing these systems for both research and production.
OpenAI RLHF Codebase
In 2019, OpenAI released one of the first public demonstrations of RLHF, implemented in TensorFlow 1.x and applied to text summarization. The system created several summary options for each prompt.
These rankings trained a reward model that scored new outputs, improving policy via reinforcement learning.
This codebase is outdated now, but it demonstrates the core RLHF pipeline. Its design influenced later systems like ChatGPT and guides how human judgments link to model behavior.
Reinforcement Learning of Language Models (RL4LMs)
Developed on PyTorch, RL4LMs is a framework to assess the impact of various reinforcement learning methods on the alignment of language models. It has several policy optimization methods like PPO, A2C (Advantage Actor-Critic), TRPO (Trust Region Policy Optimization), and NLPO (Natural Language Policy Optimization).
RL4LMs are notable for allowing custom reward functions, which can be based on learned reward models, rule-based logic, or both.
This flexibility helps study how reward signal design affects model behavior. It is especially useful for reducing hallucinations, which ensures truthfulness, and managing feedback variance.
With over 2,000 experiments, RL4LMs is one of the most comprehensive RLHF platforms for studying policy learning, reward shaping, and feedback loop dynamics.
Uni-RLHF: Universal RLHF Workflow
Uni-RLHF is an end-to-end RLHF research framework that aims to integrate a variety of training goals, feedback forms, and reward modeling methods. This isn't just for language models. It works with over 30 task categories.
These include truthfulness, toxicity control, intent alignment, and user preference modeling. It offers full offline RLHF pipelines, training a base model with human preference data and reward signals from comparison datasets.
These datasets have numerous prompts and responses ranked by humans. The framework can train a reward model, score new outputs, and optimize the policy with PPO or similar methods.
Uni-RLHF has a modular design that supports data collection, dataset curation, and benchmarking. The toolkit provides utilities to standardize the SFT phase. Additional features help debug the reward model training and track performance across feedback sources.
RLHF Libraries and Algorithms
After pretraining the base model and initial data, RLHF training uses libraries for reward modeling. It includes policy updates and reinforcement learning algorithms.
These libraries focus on improving language models or multi-modal models. They use annotated preference data from pairwise comparisons, rankings, or demonstrations.
Let’s look at some of them:
Transformer Reinforcement Learning (TRL) by Hugging Face
The TRL library is among the most accessible and production-ready reinforcement learning on human feedback applications to language models.
TRL provides training classes on:
- Proximal Policy Optimization (PPO)
- Direct Preference Optimization (DPO)
- Reward-Weighted Regression (RWR)
These algorithms enable users to fine-tune a policy model using a reward signal. This signal can be custom-made, rule-based, or based on a reward model that includes human feedback. Users can switch to a human-optimized model without needing to rebuild the RL loop.
The PPOTrainer in TRL handles the key steps of training. It samples model outputs, scores them with rewards, and updates the model to improve those scores.
TRL also integrates with DeepSpeed for efficient training of models with hundreds of millions or even billions of parameters.
TRLX Scalable RLHF Library by CarperAI
TRLX is an extended version of TRL with additional research flexibility, created by the CarperAI team. TRL is aimed at usability, whereas TRLX focuses on scaling RLHF to bigger language models and testing more advanced algorithms.
It supports offline RLHF and contains state-of-the-art techniques such as Implicit Language Q-Learning (ILQL). This renders TRLX suitable in scenarios where it is difficult or expensive to collect live feedback data.
The library can train with sparse and dense reward signals. This feature is helpful for fine-tuning on human preference data that has few annotations. It also has sampling, logging, and evaluation tools that are key for studying model outputs during training.
TRLX aligns models with up to 20B parameters. Its modular design lets you easily plug in custom reward functions. You can evaluate how different reward designs impact model performance.
Human Feedback Systems for RLHF
Human feedback systems act as the bridge between human judgment and model optimization. They capture, process, and structure feedback so it can be used effectively in training.
These systems turn personal preferences into trainable signals. This helps RLHF pipelines better align models with user intent.
Below are some examples of human feedback systems used in RLHF pipelines.
Research and Community Tools Implementations
A surge in open-source contributions and academic resources has also contributed to the RLHF ecosystem. These initiatives cut experimentation costs and speed up research. They focus on alignment, reward modeling, and direct preference optimization methods.
For example, Stanford's DPO (Direct Preference Optimization) has published implementations that bypass traditional RL algorithms like PPO to directly optimize policies using human preference data.
Other groups have contributed valuable open RLHF resources. For example, Anthropic released a publicly accessible dataset of human-preference comparisons for assistant helpfulness and harmlessness.
Meanwhile, the BeaverTails dataset (by Peking University) provides vast collections of safety-focused human annotations and pairwise comparisons.
These resources are great starting points. You can use them for training base models, tuning reward models, or benchmarking alignment techniques.
Monitoring tools and community datasets work together. They support the entire RLHF pipeline. This includes training, deployment, and ongoing optimization. The process is grounded in human values, supervised fine-tuning, and active feedback..
Challenges and Limitations of RLHF
Despite its efficiency gains, RLHF faces several challenges and limitations:
- Human Bottlenecks of Feedback: RLHF needs human input, which is slow. This is especially true for complex tasks and training language models. Inconsistent human interaction and multiple responses slow down the training process.
- Unstable Reward Models: Reward models do not always match human expectations. Problems arise from separate reward models, poor language understanding, or rigid reward functions.
- Overoptimization Misalignment: RLHF runs the risk of over-optimizing on the reward signals, which decreases creativity and constrains pretrained models. This makes it difficult to know how to align AI systems, how to reflect human intent, and how to train models.
- Inconsistent Human Preferences: It's tough to get stable rewards when annotators disagree. Unclear human guidance, feedback, or communication makes it harder to collect quality data.
- Low Transparency: RLHF is difficult to debug. Issues may originate in the base model, the reward model, or the RLHF training process. Limited understanding of training dynamics and timely human feedback slow alignment progress.
Alternatives and Recent Advances in Alignment
Active learning has reduced the need for constant human feedback to maintain optimal alignment. Here are some notable alternatives and recent advancements:
- Direct Preference Optimization (DPO): DPO removes the need for a separate reward model by training directly on human preference pairs. It simplifies the RLHF pipeline with soft constraints and enables more stable training without PPO.
- Reinforcement Learning with AI Feedback (RLAIF): RLAIF uses a supervised model or rule-based system (e.g., a “constitution”) to provide alignment feedback. This makes data cheaper and more efficient. It also helps create safer AI systems that don’t need constant human feedback.
- Active Learning and Query Efficiency: In an RLHF pipeline, active learning targets uncertain or unclear model outputs. This helps focus human annotation and boosts alignment signals. Entropy sampling, ensemble disagreement, and gradient selection find valuable responses.
Enhancing RLHF with Lightly AI
Lightly AI integrates into RLHF pipelines as a data pre-processing and prioritization layer that operates before annotation and reward model training.
Its role is to ensure only the most informative, diverse, and domain-relevant samples reach human annotators, reducing wasted annotation cycles.
Smart Data Selection
Lightly One adds a Data Selection Engine that automatically finds the most valuable data for labeling using embeddings and active learning. It’s a direct fit for reducing RLHF annotation cost and accelerating iteration.
Where it fits in RLHF:
- Build clean, de-duplicated preference sets before annotation.
- Prioritize uncertain or novel samples to focus annotation efforts.
- Provide reproducible, traceable selection processes for auditability.
Self-Supervised Pretraining
Lightly Train is a self-supervised pretraining framework to adapt vision backbones to your domain without labels. For RLHF in multimodal/vision setups, better pretrained features mean fewer labeled comparisons to reach stable reward signals and stronger downstream fine-tuning.
Where it fits in RLHF:
- Improve encoder representations so that preference data is more informative.
- Reduce the amount of labeled ranking data needed.
- Accelerate downstream training by starting from domain-aware features.
RLHF: Key Takeaways
Reinforcement learning with human feedback (RLHF) combines human preference data with a learned reward model to make large language model outputs consistent with human values.
PPO stabilizes the policy updates under the KL constraints and maintains the diversity of outputs. This improves coherence, factual correctness, and safety in AI systems by using comparative human feedback instead of hand-designed reward functions.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


