
EoMT: Your ViT is Secretly an Image Segmentation Model
Table of contents
Share blog post



EoMT is a 2025 state-of-the-art universal segmentation model using only a ViT encoder—no pixel or transformer decoder—achieving up to 4× faster inference with competitive accuracy, powered by DINOv2 pretraining and optimized for simplicity and scale.
Share blog post
Quick answers to common questions about EoMT:
Encoder-only Mask Transformer (EoMT) is a new state-of-the-art universal segmentation model (2025) that simplifies the architecture by relying solely on a Vision Transformer (ViT) encoder: no pixel decoder, no transformer decoder (no problem).
It’s up to 4× faster than prior models while maintaining competitive accuracy. This architectural simplicity is made possible through large-scale self-supervised pretraining with DINOv2.
Introduction
Semantic segmentation is a core task in computer vision where each pixel in an image is assigned a class label. It’s fundamental in applications where understanding the precise shape and location of objects matters.
Some key examples include:
- Autonomous driving: identifying lanes, vehicles, pedestrians, and traffic signs at the pixel level.
- Medical imaging: segmenting tumors, organs, or other anatomical structures from whole slide images, MRI or CT scans.
- Satellite imagery: distinguishing between urban areas, forests, water bodies, or roads.
- Agriculture: detecting crop boundaries or disease-affected areas in aerial imagery.
Achieving accurate segmentation in these domains requires models that are both precise and computationally efficient.
In many applications, such as autonomous driving, drones, or edge devices in healthcare, inference must happen in real time with limited memory and compute. For instance, a self-driving car must segment roads, obstacles, and pedestrians in milliseconds, while a medical device might need to run segmentation on-device during surgery or imaging.
Balancing accuracy with efficiency is critical, not just for performance, but for feasibility. Over the years, the architecture of segmentation models has evolved significantly to address this tension, moving from convolutional neural networks to transformer-based designs.
In this post, we’ll briefly revisit the major milestones in the field of image segmentation, highlighting the key architectural innovations that paved the way for EoMT.
And while EoMT brings architectural advances for segmentation, pairing it with smart training workflows is key. Lightly helps with:
- LightlyTrain: Pretrain and fine-tune segmentation models like EoMT on curated, domain-specific datasets
- LightlyOne: Select the most relevant and diverse samples for training to reduce redundancy and improve performance
If you are here to learn about Lightly + EoMT, you are also welcome to skip ahead to the EoMT section.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Evolution of Semantic Segmentation
UNet: A Foundational Design Beyond Segmentation (2015)
Originally developed for biomedical image segmentation, UNet quickly became a cornerstone in the field. The UNet architecture essentially boils down to three core ingredients:
- An encoder that compresses high-resolution RGB images into a low-resolution, high-dimensional embedding space, capturing the high-level semantic structure of the image.
- A decoder that transforms these compact embeddings back into high-resolution predictions.
- Skip connections that bridge the encoder and decoder at each level, injecting fine-grained spatial detail into the reconstruction process by combining low-level features with high-level context.
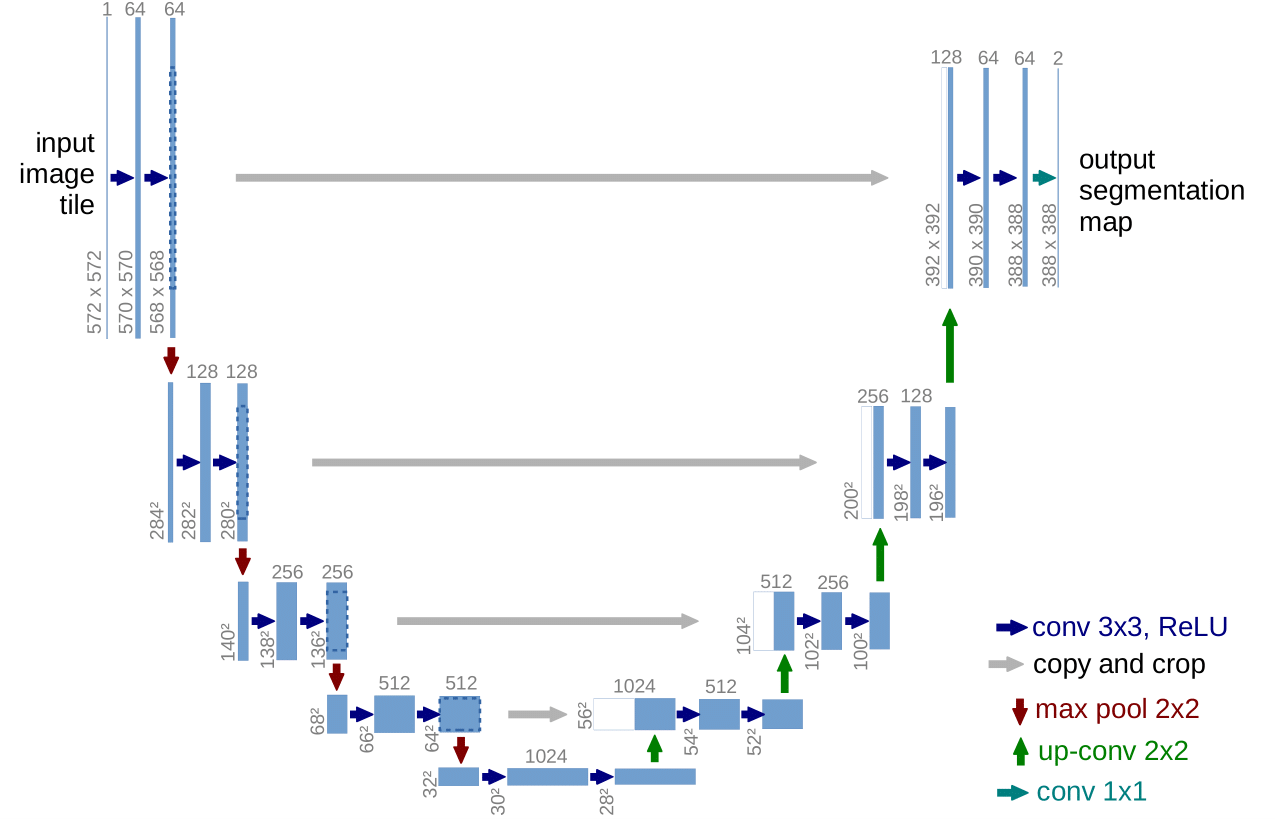
Variations of these components continue to appear in modern architectures.
UNet’s enduring success is likely due to its data efficiency, flexibility, and the fact that it makes minimal assumptions about the encoder design, allowing it to adapt easily to different tasks and backbones.
Interestingly, this architectural pattern isn’t limited to segmentation.
Depending on the output space and the use of skip connections, UNet variants have been applied to pixel-level prediction tasks like depth estimation, optical flow prediction, and even image reconstruction in self-supervised and generative modeling contexts.
DeepLabv3: Capturing Context with Dilated Convolutions (2017)
While UNet focused on combining local and global information through skip connections, DeepLabv3 approached the problem from a different angle: how to capture multi-scale context without sacrificing resolution.
At the heart of DeepLabv3 is the use of dilated (atrous) convolutions, which allow the model to expand its receptive field without downsampling the feature maps. This makes it possible to incorporate broader contextual information while preserving fine spatial details.


A key component of DeepLabv3 is the Atrous Spatial Pyramid Pooling (ASPP) module, which applies multiple parallel dilated convolutions with different dilation rates. This effectively captures features at multiple scales, helping the model handle objects of varying size and structure in a single forward pass.
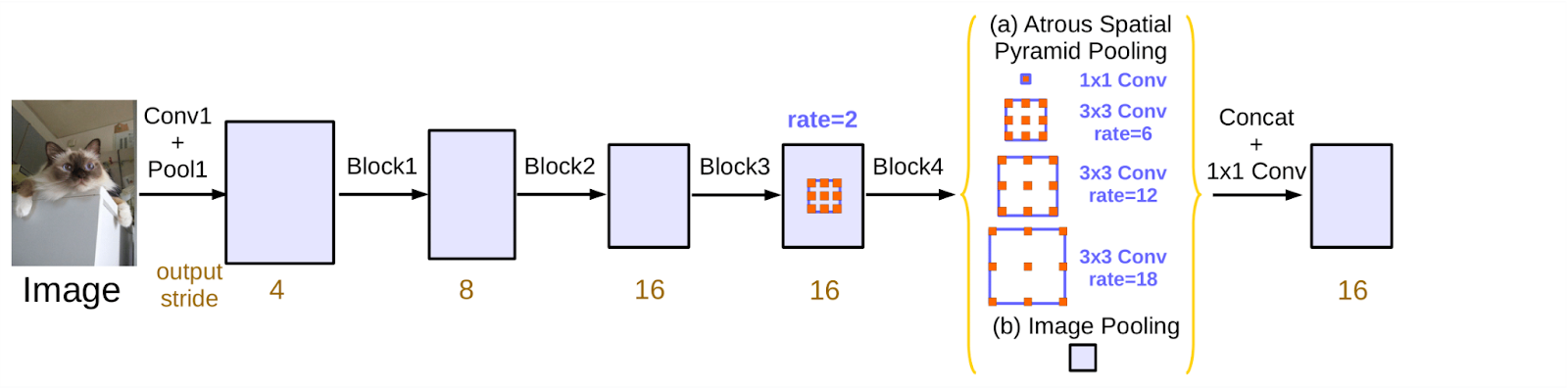
Unlike UNet, DeepLabv3 does not use a symmetric decoder. Instead, it relies on upsampling and lightweight refinement layers, making it more compact and often more efficient in high-resolution settings.
MaskFormer: From Pixels to Object Masks (2021)
While UNet and DeepLabv3 introduced major advances in semantic segmentation, they share a core limitation: they follow the pixel classification paradigm, predicting a class label for each pixel independently.
This formulation is well suited for semantic segmentation, where the goal is to assign category labels like “road” or “tree” to every pixel, but it cannot distinguish between multiple instances of the same class.
This is the goal of instance segmentation: assigning separate masks to each object instance, even when they belong to the same category (e.g., identifying two distinct people in the same scene). Some applications go even further and require panoptic segmentation, which unifies semantic and instance segmentation by labeling both “stuff” (amorphous regions like sky or sidewalk) and “things” (discrete, countable objects like cars or pedestrians), each with its own mask. Traditional pixel-level classifiers like UNet and DeepLabv3 are ill-suited for instance or panoptic segmentation.
Inspired by the DEtection TRansformer (DETR) object detection framework, which introduced set prediction using transformers, MaskFormer reimagines segmentation using the mask classification paradigm.
Instead of predicting one mask per class, MaskFormer decouples the processes of segmentation and classification. It first predicts a fixed-size set of class-agnostic masks, and only then assigns each mask a class label. This enables a flexible and unified approach to all segmentation tasks, while avoiding the limitations of dense pixel-level classification.
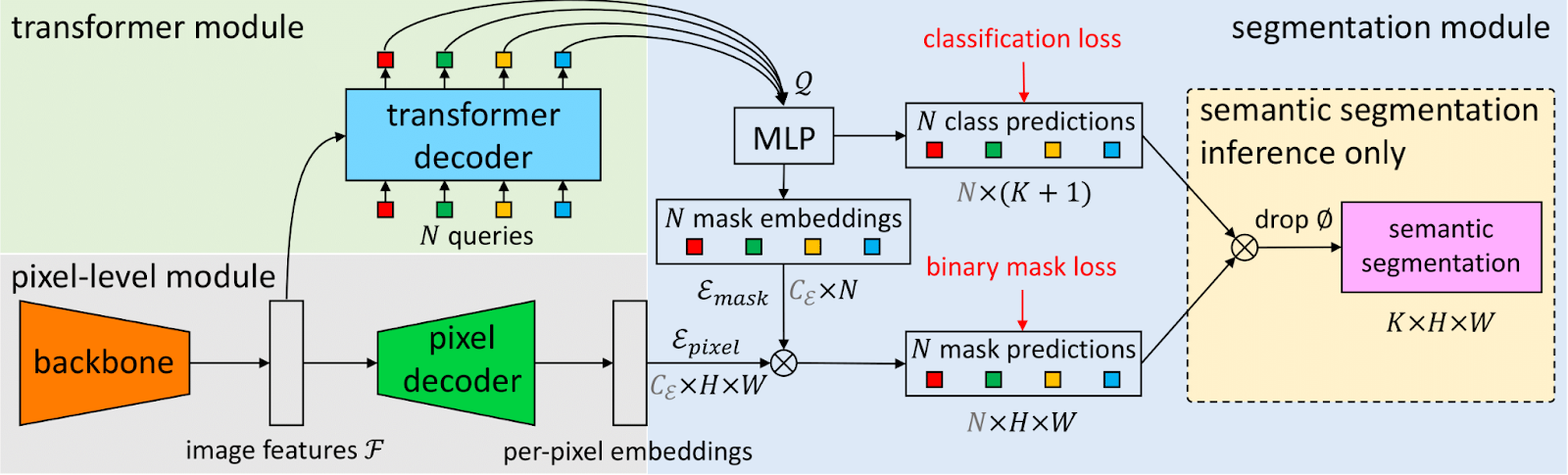
Interestingly, the mask classification paradigm is not only more flexible, it also outperforms the traditional pixel classification approach in direct, apples-to-apples comparisons for semantic segmentation.
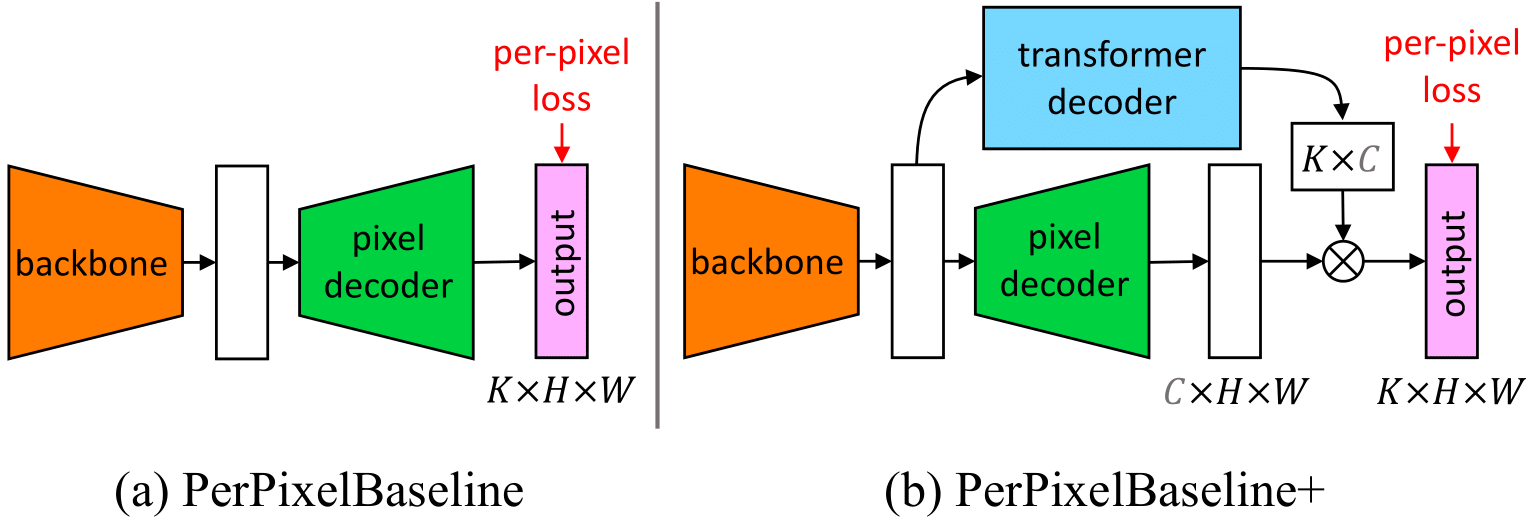
To demonstrate this, the authors of MaskFormer designed a controlled experiment using an identical architecture, PerPixelBaseline+, which shares the same backbone and decoder as MaskFormer.
The only difference lies in the prediction strategy: instead of predicting a set of masks, the baseline sets the number of queries equal to the number of classes in the dataset, effectively reverting to the pixel classification paradigm.

The results are clear: as shown in Table 1, the mask classification approach consistently outperforms its pixel-level counterpart, especially as the number of classes increases.
This suggests that reasoning over a set of object masks is not just more general, it also leads to better segmentation performance, even for standard semantic segmentation tasks.
Mask2Former: A Universal Architecture for All Segmentation Tasks (2021)
While MaskFormer popularized the mask classification paradigm and unified segmentation under a shared framework, it still lagged behind specialized architectures both in terms of performance and training efficiency.
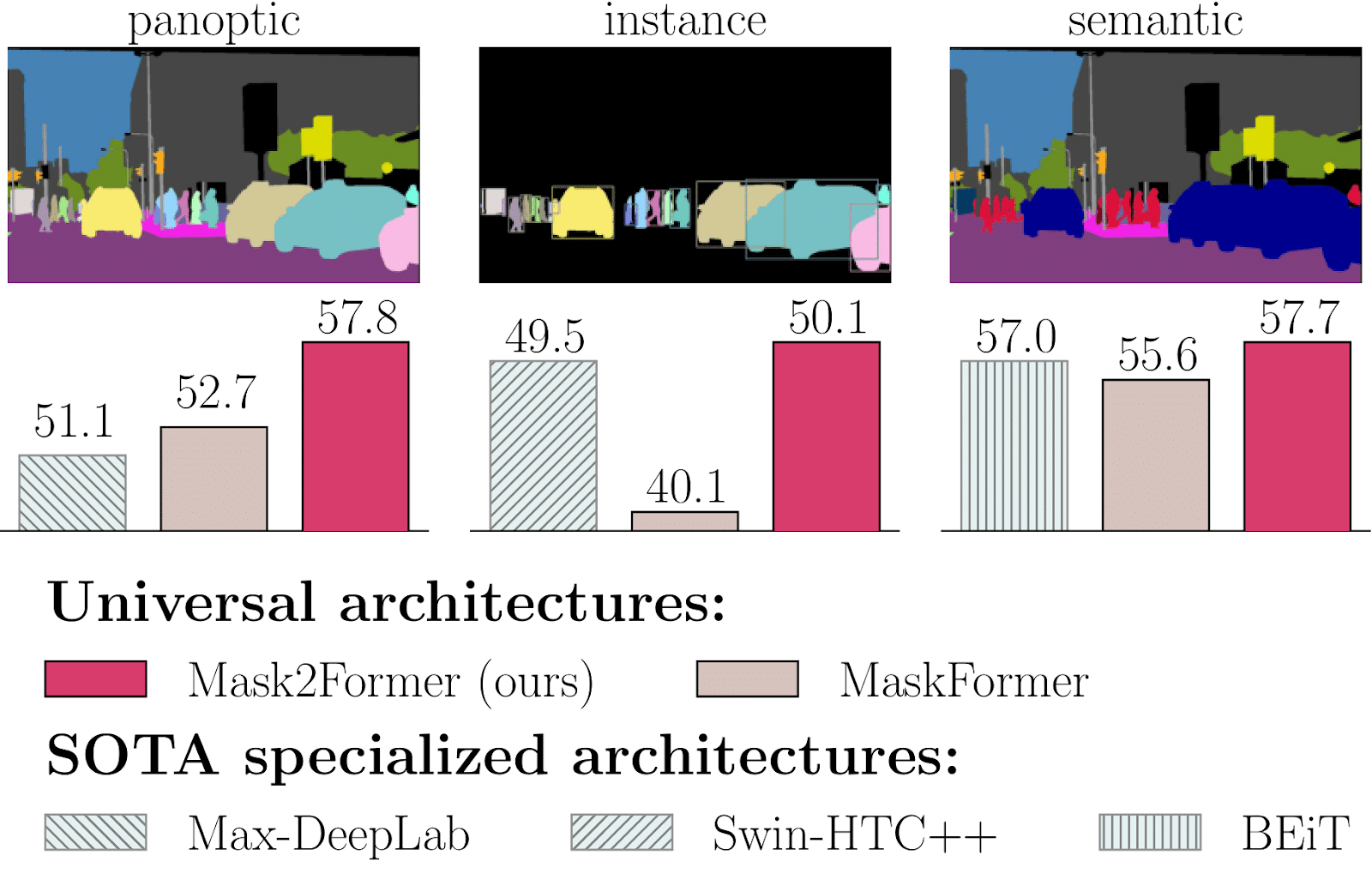
Mask2Former proposed key improvements to bridge the gap with specialized architectures.
Masked Attention
Transformer-based segmentation models like MaskFormer, which adopt the architectural philosophy of DETR, are known to converge slowly during training.
This issue has been analyzed in works such as "Fast Convergence of DETR with Spatially Modulated Co-Attention", which attributes it to global cross-attention (each query attends to all image features). Without strong spatial priors, it takes many training iterations for the model to learn to focus on relevant object regions.
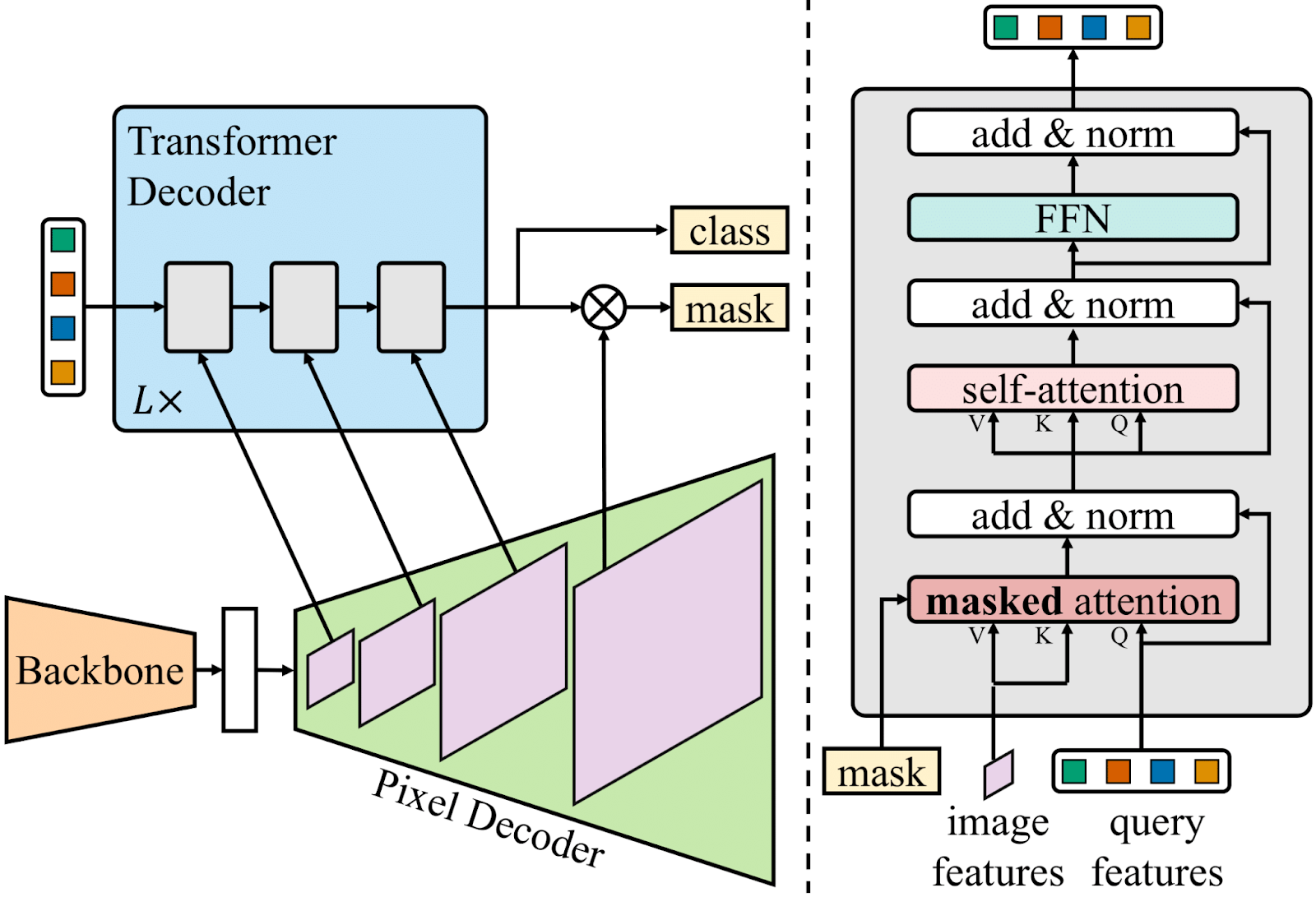
To address this, Mask2Former introduces masked attention, a variant of cross-attention that limits each query to attend only within its own predicted foreground region (see above diagram).
These regions are computed dynamically: the queries from the previous decoder layer produce soft masks, which are then binarized to obtain hard attention masks.
This mask filters the attention weights, ensuring that each query focuses on specific regions of the images.




While this doesn't reduce the computational cost of attention, since the full attention map is still computed, the mask guides the learning process, helping the model assign attention meaningfully from the start.
Broader context is still captured through the self-attention layers of the decoder blocks. Overall, this results in faster convergence.
Multi-Scale Feature Integration
As we've seen in both UNet and DeepLabV3, leveraging high-resolution features is critical for accurate segmentation, especially when dealing with small objects or fine-grained structures. UNet achieves this through skip connections, while DeepLabV3 uses atrous convolutions and spatial pyramid pooling to maintain spatial detail.
In contrast, MaskFormer operates on single-scale features, which limits its ability to handle object scale variation effectively. Mask2Former addresses this by introducing a more robust multi-scale feature integration strategy.
Inspired in part by the success of Deformable DETR, which showed that multi-scale features significantly improve performance and convergence in transformer-based detectors, Mask2Former adopts a feature pyramid produced by a pixel decoder. Instead of feeding all scales at once (which is memory intensive), the model feeds one resolution per decoder layer, cycling through coarse to fine scales in a round-robin manner.
This design gives each layer access to a different spatial resolution, allowing the model to capture both global context and local detail over the course of decoding, while keeping the overall computation tractable. The result is improved accuracy across objects of varying sizes and better generalization in dense, complex scenes.
Optimization Improvements for More Efficient Training
Mask2Former introduces several key improvements over MaskFormer to enhance both model stability and training efficiency. A central change lies in how supervision is applied to the queries: instead of waiting for the decoder output, early mask predictions are obtained by projecting image features onto the queries before the decoder, and these projected masks are directly supervised via the loss. This provides the queries with a stronger and earlier training signal.
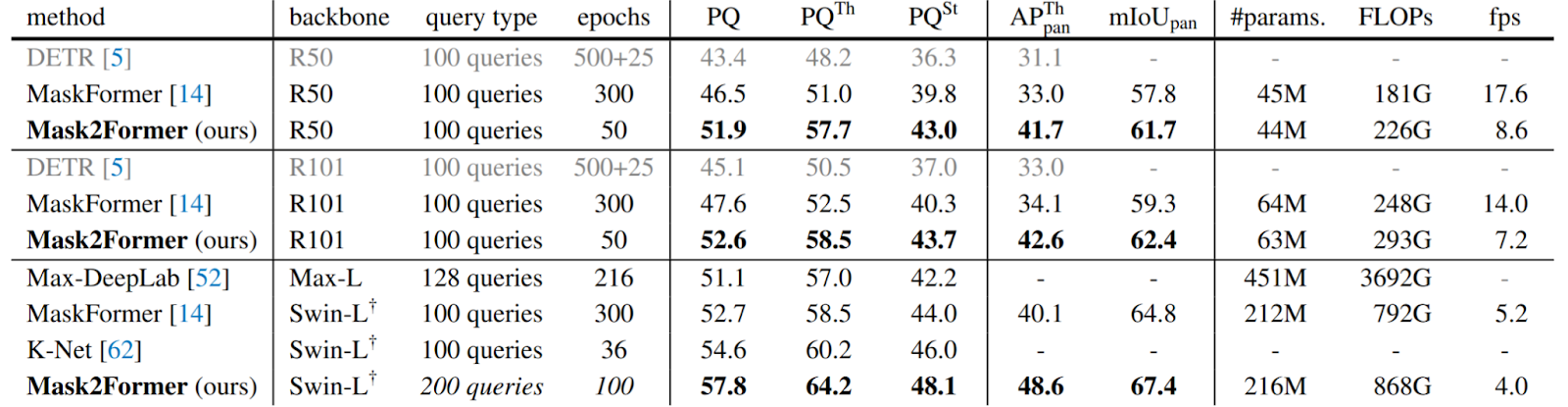
Additional architectural refinements include reordering the decoder operations to apply cross-attention before self-attention and removing dropout, which was observed to degrade performance. Finally, Mask2Former addresses a major GPU memory bottleneck in the matching stage: rather than computing losses over full-resolution masks for every prediction–ground truth pair, it samples a subset of pixels per mask to compute the matching cost.
This point-based approximation reduces training memory by a factor of three. As can be observed in Table 2 Mask2former significantly outperforms Maskformer, while typically requiring 6 times less epochs.
Encoder-only Mask Transformer: EoMT (2025)
Scale brings simplicity with EoMT
As we have seen with models like U-Net, DeepLabv3, MaskFormer, and Mask2Former, achieving accurate image segmentation has traditionally required a stack of architectural components, such as multi-scale feature extractors, pixel decoders, and Transformer decoders.
Vision Transformers (ViTs), despite their strong performance across vision tasks, remain underused in segmentation due to two main concerns:
- Firstly , the widespread belief that ViTs are too slow or memory-intensive for high-resolution inputs due to the quadratic cost of self-attention;
- Secondly, the fact that they produce low-resolution, single-scale features that don't align well with the expectations of segmentation heads.
However, the first assumption has been increasingly challenged and comparative studies such as this article, have shown that ViTs can already be competitive in terms of speed and memory consumption.
Furthermore, advances in hardware and algorithms, like FlashAttention, are making transformer-based architectures increasingly competitive. The second concern has typically been addressed through convolutional adapters, such as ViTDet and ViT-Adapter, which augment the transformer with parallel high-resolution branches. While effective, these additions, combined with multi-stage decoders, result in slow and complex pipelines.
EoMT challenges this design trend by fully embracing the scalability of ViTs and recent progress in large-scale visual pretraining. Instead of relying on task-specific modules, it uses a plain ViT backbone initialized from powerful vision foundation models (VFMs) like DINOv2, which are trained on massive datasets using self-supervised objectives such as masked image modeling.
Unlike architectures such as Swin or ConvNeXt, which are structurally incompatible with this pretraining strategy, EoMT directly benefits from the representational strength of VFMs. This enables it to achieve high segmentation performance with far greater simplicity and speed.
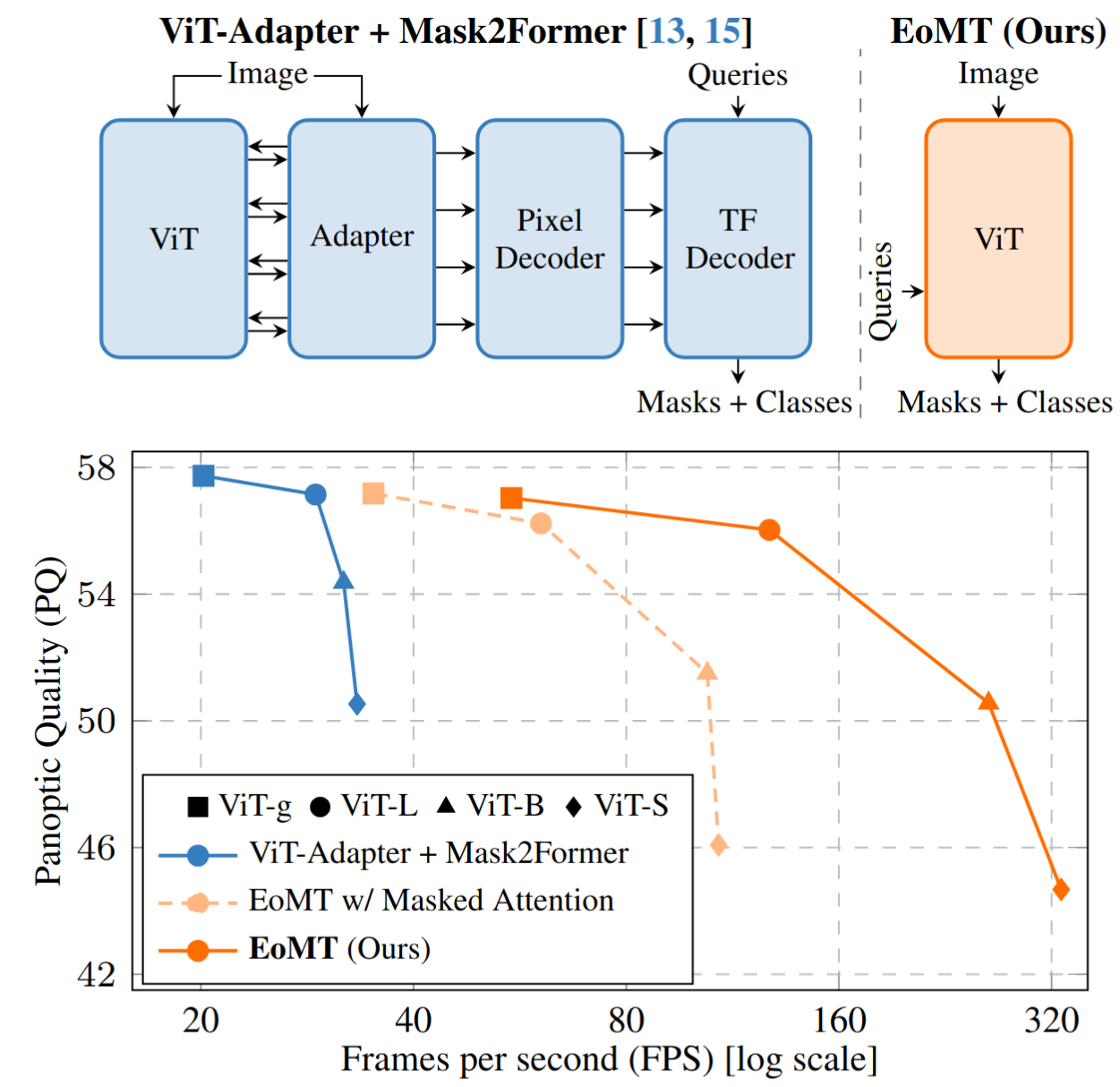
As illustrated in Figure 9, EoMT is derived from the state-of-the-art Mask2Former architecture, but simplifies it by removing the feature adapter, pixel decoder, and transformer decoder.
Importantly, like Mask2Former, it follows the mask classification paradigm, enabling it to perform instance, panoptic, and semantic segmentation within a unified architecture.
Architecture Simplification
Table 3 demonstrates that task-specific components can be removed with minimal impact on Panoptic Quality (PQ). At the same time, inference throughput increases by more than 4×.
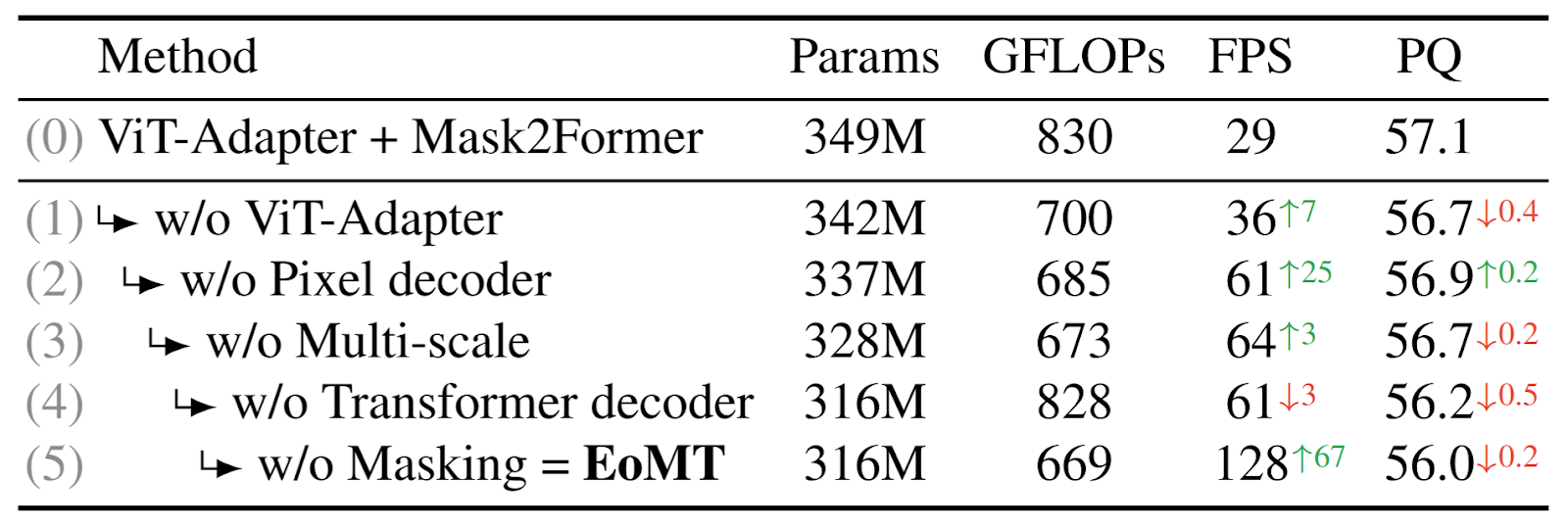
Some of these architectural changes are relatively straightforward to implement, but the removal of the transformer decoder and attention masking is more involved.
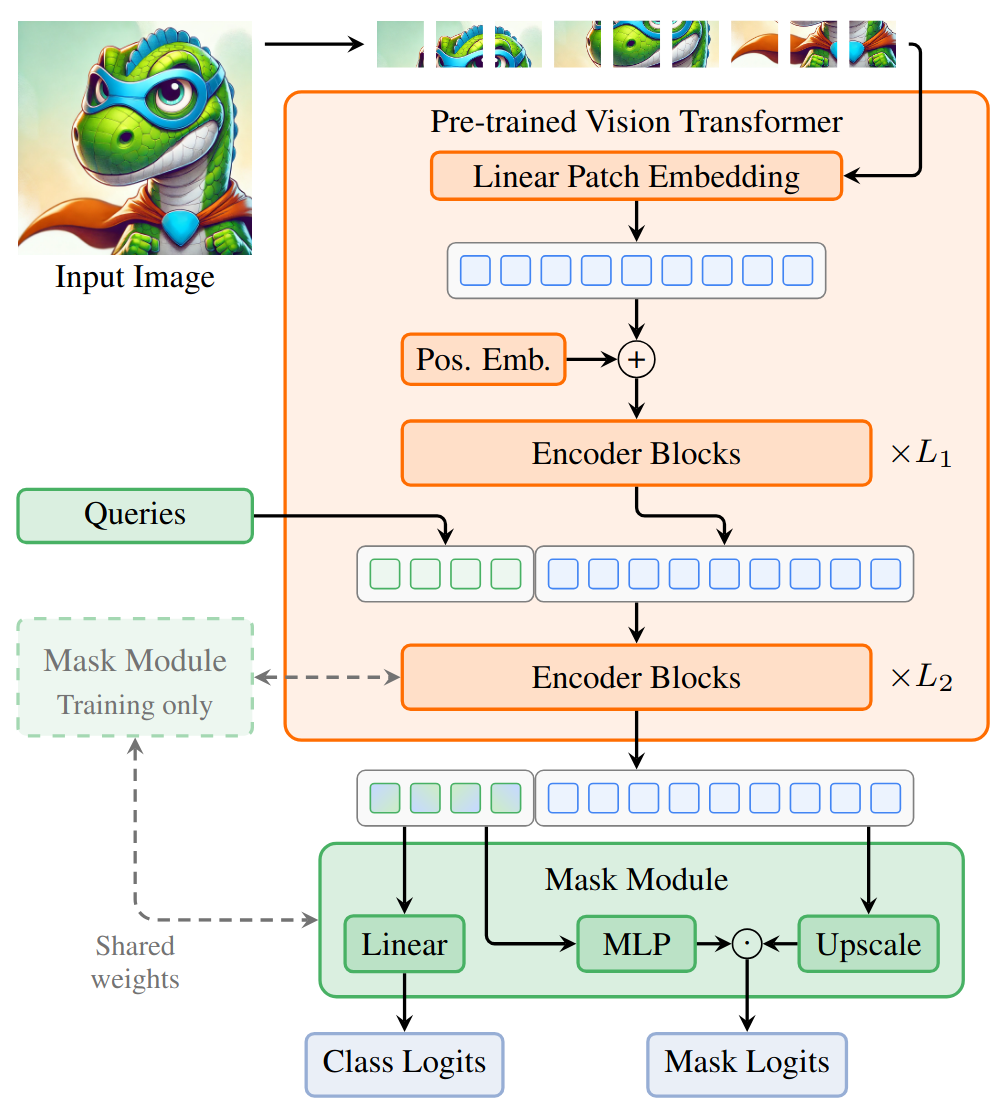
Instead of using a dedicated transformer decoder to process the queries, EoMT integrates query decoding directly into the encoder. In the final layers of the ViT encoder, learnable query tokens are prepended to the sequence of image tokens, allowing both sets of tokens to be processed jointly.
This approach replaces the traditional interleaved pattern of cross-attention (between image tokens and queries) and self-attention (within the queries) with shared self-attention, where query tokens simultaneously attend to each other and to image tokens through the encoder’s attention layers.
To improve convergence, similar to Mask2Former, query attention is constrained by masks, which limit the spatial regions that each query can attend to during training.
Although masked attention is beneficial during training, Table 3 shows that its removal at inference time yields a substantial boost in throughput. The reason is straightforward: when attention masks are present, FlashAttention cannot be used.
Without masks, however, PyTorch’s scaled_dot_product_attention can dispatch to FlashAttention, unlocking significant speed and memory improvements. This makes it critical to eliminate masking at inference.
However, as Table 4 below illustrates, simply removing the masks at test time leads to degraded performance, unless the model has been trained to operate without them.

Table 4: Mask annealing during training is key to achieving both high inference speed and strong accuracy.
To address this train-test mismatch, EoMT introduces a progressive mask annealing strategy. During training, attention masks are applied with a probability that gradually decreases from 1 to 0. As training progresses, queries learn to identify and focus on relevant image tokens independently, rather than relying on hard-coded attention constraints.
This enables the model to retain the convergence benefits of masked attention early in training, while fully benefiting from unmasked, FlashAttention-compatible inference at test time.
You can train this model on your own dataset with just a few lines of code:
import lightly_train
if __name__ == "__main__":
# Train a model.
lightly_train.train_semantic_segmentation(
out="out/my_experiment",
model="dinov2/vitl14-eomt",
data={...},
)
# Load the trained model.
model = lightly_train.load_model_from_checkpoint(
"out/my_experiment/checkpoints/last.ckpt"
)
# Run inference.
masks = model.predict("path/to/image.jpg")Conclusion
In this post, we’ve outlined the key developments in segmentation that paved the way for the recently introduced state-of-the-art universal segmentation model: the Encoder-only Mask Transformer (EoMT). EoMT achieves outstanding performance across all three major segmentation tasks, semantic, instance, and panoptic, while delivering throughput improvements of over 4× compared to concurrent methods, all with a significantly simpler architecture.
This breakthrough stems from EoMT’s successful bet on a combination of recent advances: the scalability of Vision Transformers, the efficiency unlocked by FlashAttention, and the power of large-scale self-supervised visual pretraining via foundation models like DINOv2.
By eliminating traditional task-specific components and leveraging modern infrastructure, EoMT offers a compelling case for simplicity through scale in dense visual prediction.
We hope this has sparked your interest in trying out EoMT on your own data. If so, you're in luck, LightlyTrain has already taken notice.
Designed to empower computer vision teams with the ability to build and adapt their own vision foundation models, LightlyTrain now makes it easy to experiment with EoMT. You can get started in just a few lines of code. Head over to our repository to learn more, explore tutorials, or discover other use cases enabled by LightlyTrain.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


