
Instance Segmentation in Practice: Techniques, Tools, and Applications
Table of contents
Share blog post



Instance segmentation is a computer vision task that identifies and outlines individual objects in an image at the pixel level. It combines the strengths of object detection and semantic segmentation, enabling precise object counting and shape recognition for tasks like autonomous driving, medical imaging, and robotics.
Share blog post
Quick answers to common questions about instance segmentation.
1. What is instance segmentation?
Instance segmentation is a computer vision technique that identifies each object in an image and outlines its exact pixel-wise shape. In other words, it predicts a unique mask, or set of pixels, for every individual object in the image. This goes beyond basic object detection, which only draws a box around an object. It involves outlining the precise edges of each object. It also goes further than semantic segmentation, which labels pixels by their type but doesn’t differentiate between different objects of the same type. Instance segmentation, on the other hand, can identify and separate each object, even if they belong to the same category.
2. How does instance segmentation compare to object detection and semantic segmentation?
Instance segmentation is like a hybrid of object detection and semantic segmentation. Object detection finds and classifies objects via bounding boxes, but it doesn’t give pixel-level details. Semantic segmentation labels every pixel with a class (e.g., “dog” vs. “background”), but it doesn’t differentiate between multiple objects of the same class. Instance segmentation provides the best of both. Each object gets its own segmented mask and class label, which allows it to count and separate objects individually.
3. What are popular instance segmentation models?
Some well-known models include Mask R-CNN, a two-stage model that first detects objects and then segments them. YOLACT is a one-stage model that performs detection and segmentation in one pass for real-time performance. SOLOv2 is an anchor-free model that segments objects based on their spatial locations in a grid, eliminating the need for bounding boxes. PointRend is a refinement module that enhances mask detail by focusing on selected point predictions, resulting in high-quality boundaries. Modern YOLO models (e.g., YOLOv8) also support instance segmentation in a single forward pass.
4. What are some real-world applications of instance segmentation?
Instance segmentation is used wherever the precise shape and location of objects matter. In autonomous driving, it helps self-driving cars spot and separate pedestrians, vehicles, and obstacles to navigate safely. Doctors use it in medical imaging to identify and outline tumors or organs in scans, which helps with diagnosis and treatment. Robots use it to recognize and handle objects with clear boundaries. It’s also helpful in aerial and satellite imagery, like mapping buildings or spotting ships at sea. In agriculture, it can count fruits or plants. Essentially, it’s useful anytime you need to identify specific objects in visual data.
Instance Segmentation in Practice: Techniques, Tools, and Applications
Technology is making computer vision a part of our everyday lives, from traffic cameras to self-checkout systems.
A key technique behind these applications is image segmentation, which helps computers understand visual data by dividing it into segments based on color, texture, or proximity.
Instance segmentation takes this a step further, providing pixel-level accuracy. It plays a crucial role in areas like self-driving cars and medical imaging.
In this guide, we will discuss instance segmentation and its key differences from other computer vision and image segmentation tasks.
We’ll cover:
- What is instance segmentation
- Key concepts in instance segmentation
- How does instance segmentation work?
- Instance segmentation models and architectures
- Instance segmentation vs. other vision tasks
- Applications of instance segmentation in the real world
Instance segmentation demands high-quality, diverse data, and a smart approach to using it. At Lightly, we’re building tools to help teams train better segmentation models through:
- LightlyOne: Curate the most representative and diverse samples to improve accuracy and generalization in segmentation-heavy workloads.
- LightlyTrain: Pretrain and fine-tune models with stronger visual understanding for pixel-level tasks like instance segmentation.
You can try it for free.
What is Instance Segmentation?
Instance segmentation is a computer vision algorithm that aims to detect, classify, and outline different instances of objects in an image. It assigns a unique instance segmentation mask (a pixel-wise outline) and a class label like "car" or "person" to every individual object.
Unlike object detection, which uses bounding boxes to locate objects, instance segmentation takes it a step further by outlining each object individually. It also differs from semantic segmentation, which labels all pixels by class but groups objects of the same category together. Instead, instance segmentation treats every object as a separate entity.
Pro tip: Check out YOLO Object Detection Explained: Models, Tools, Use Cases.
For example, in an image with several cows, an instance segmentation model would generate a separate mask for each cow to differentiate them as separate entities.

Each computer vision task provides a different level of detail and is suited for specific applications.
💡Pro Tip: If you are working with video data rather than still images, you will need segmentation methods that keep masks consistent across frames. For a practical overview, see our Video Segmentation Guide.
Below is a comparison table to distinguish them more clearly.

See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Key Concepts in Instance Segmentation
To understand how instance segmentation works, you need to be familiar with a few concepts and components related to object recognition.
These clarify how the model identifies regions and separates objects in an image. If a photo contains five cars, there are five distinct multiple instances of the "car" class.
- Class Label: The name of the object category, such as person, bicycle, or dog.
- Segmentation Mask: It's a pixel-wise outline that has the same dimensions as the input image. Each mask isolates one object from the rest of the image to show its exact shape.
- Bounding Box: Most instance segmentation models first perform object detection to draw a box around objects to define a rough location. These boxes then help define the scope for mask prediction.
- Ground Truth: This is expert-labeled data used for training instance segmentation models. Ground truth object segmentation masks are the pixel-accurate boundary of an object that the model tries to replicate.
How Instance Segmentation Works
The segmentation models are built on deep machine learning algorithms like Convolutional Neural Networks (CNNs) or Vision Transformers. While different architectures exist, most follow a general pipeline to get from an input image to a final set of masks.
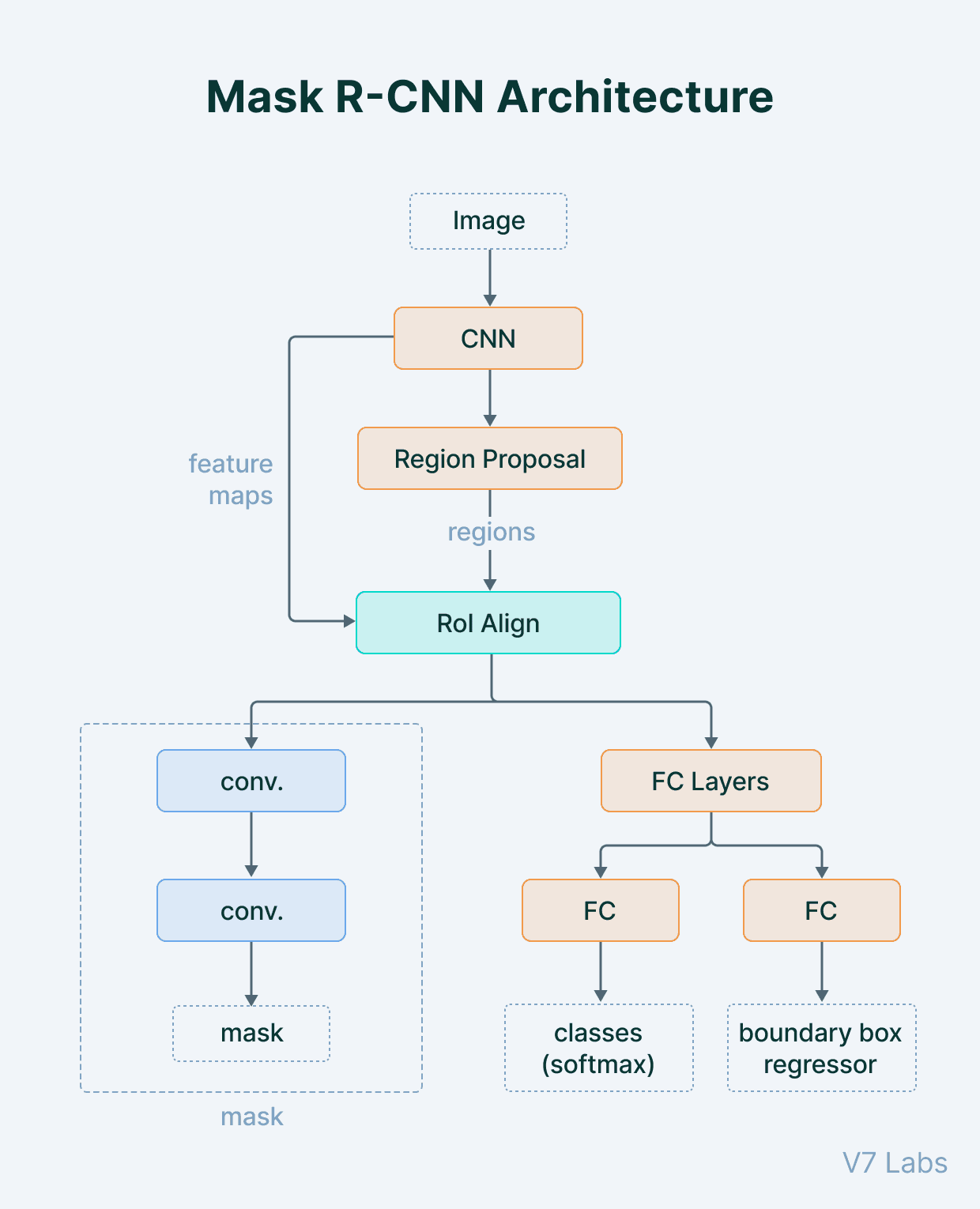
Here’s a detailed look at how a two-stage model like Mask R-CNN tackles the instance segmentation task.
The process starts by feeding the raw input image into a CNN, which transforms it into a series of feature maps. Early CNN layers detect low-level features like edges, colors, and textures. Deeper layers combine these to recognize complex patterns, parts, and whole objects.
After feature extraction, the model needs to identify object locations. This is done by the Region Proposal Network (RPN).
The RPN slides over the feature maps and suggests many rectangular regions of interest (RoIs), or object bounding boxes, that are likely to contain an object.
Next, the model extracts features from the feature maps for each proposed RoI. The RoIAlign layer ensures the features within each proposed box are properly aligned. These aligned features are then passed into the "head" of the network, which performs two tasks in parallel:
- Classification: It predicts the class label of the object within the RoI.
- Bounding Box Regression: It refines the coordinates of the bounding box to make it fit the object more tightly.
Pro tip: Read our Engineer’s Guide to Image Classification.
At the same time as classification and box refinement, the features from RoIAlign are passed into a separate "mask head." For each RoI classified as an object, the mask head generates a segmentation mask within that small box using a Fully Convolutional Network (FCN). This mask colors the pixels belonging to the object.
Since the process is done for each object instance individually, the model can effectively handle overlapping objects without confusion.
Here’s how you can implement instance segmentation for your computer vision project.
- Choose a Model Architecture: The first step is selecting a pretrained model. You can choose Mask R-CNN. For faster, real-time performance, consider models like YOLO11. These models have already learned general features from large datasets like the Microsoft COCO dataset.
- Prepare Your Training Data: You need a dataset of images with a corresponding ground truth mask. You can use annotation tools to draw polygons around each object in your images to create these masks. The quality of your training data directly impacts the model's performance. You can use tools with an active learning workflow to select high-quality data smartly from raw information for model training. This way, you save the time spent on annotation.
- Train the Model (Fine-Tuning): Fine-tune a pre-trained model on your specific dataset, rather than training a model from scratch. The model uses your labeled images to learn the features of your target objects.
- Evaluate and Deploy: After training, evaluate the model's performance using metrics such as Average Precision (AP) on a separate test dataset. Once you are satisfied with the accuracy, you can deploy the model to perform instance segmentation tasks on new, unseen images.
Pro Tip: The powerful visual features learned by models are captured as embeddings. These embeddings are numerical representations crucial for understanding image content and similarity.
Instance Segmentation Models and Architectures
Over the years, researchers have developed several architectures for instance segmentation, each of which is different in its approach. Here are some influential instance segmentation models.
- Mask R-CNN: A two-stage model that first detects objects by proposing regions with a Region Proposal Network. For each region, it then classifies the object and creates a segmentation mask. Mask R-CNN is known for its accuracy, but it is computationally expensive and often too slow for real-time applications.
- YOLACT (You Only Look At CoefficienTs): This is a one-stage model that performs object detection and segmentation in parallel. It generates a set of prototype masks for the entire image. And then predicts a set of "mask coefficients" for each detected instance. The final masks are produced by combining these prototypes with their respective coefficients. It’s much faster than Mask R-CNN but can be less accurate.
- SOLOv2 (Segmenting Objects by Location): This model uses an anchor-free approach. It segments objects by location and size through direct mask prediction without using bounding boxes. Next, it divides the image into a grid and predicts masks for objects centered in each cell.
- Transformer-Based Models: Newer models, like Mask2Former and Segment Anything Model (SAM), use transformers to extract features from images and generate masks with an attention mechanism. They efficiently distinguish multiple object instances in complex images in real-time.
Other notable models include DetectoRS, CenterMask, and TensorMask. YOLO-based models initially focused on object detection but now also support the segmentation task, including instance segmentation.
Instance Segmentation vs. Other Vision Tasks
When you have a deeper understanding of how instance segmentation compares to related vision tasks, you'll be able to choose the right method for your specific project.
Let's see the difference at a glance.

Applications of Instance Segmentation in the Real World
Instance segmentation enables various practical applications by providing detailed vision capabilities.
Autonomous Driving and ADAS (Advanced Driver-Assistance Systems)
Self driving cars use instance segmentation to interpret their surroundings. This helps them identify complex street scenarios, such as construction sites or crowded streets with many pedestrians.
Generating a separate mask for each object instance helps the car predict movement more accurately and navigate safely. Data from the LIDAR Bonnetal dataset or simulators like the Microsoft AirSim dataset and Stanford Background Dataset are used to train models for ADAS systems.

While instance segmentation is essential for pixel-level perception in autonomous driving, capturing the right data remains a major challenge.
That's where LightlyEdge comes in - Lightly’s smart data‑selection SDK built for autonomous systems.
Deployed directly on vehicle cameras and sensors, LightlyEdge analyzes streams in real time to filter and capture only high‑value frames like rare edge cases or pedestrian occlusions.
This dramatically reduces storage and bandwidth needs while ensuring training datasets remain focused on the most critical scenarios, enabling safer and more efficient segmentation model development in ADAS or self-driving systems
Medical Imaging and Healthcare
Instance segmentation has a wide range of applications in medical scan analysis. Radiologists use it to accurately segment tumors, lesions, and organs from MRIs, CT scans, and X-rays.
For example, histopathologic images are typically whole-slide images containing numerous nuclei of various shapes, surrounded by cytoplasm. Instance segmentation detects and segments these nuclei, which can then be further processed for disease detection, like cancer.

Robotics and Manipulation
Robots use instance segmentation for recognizing objects when they interact with their physical surroundings. To pick up an object, a robot needs to know its exact shape to grasp it properly.

Instance segmentation is used for automated quality control in manufacturing, where a model segments tiny defects, scratches, or assembly errors on products. This precise target detection ensures that only products meeting quality standards move forward in the production process.
Aerial and Satellite Imagery Analysis
Government agencies and environmental organizations use instance segmentation to analyze large-scale aerial images and satellite data. In urban planning applications, it can be used to distinguish residential areas from commercial zones or to identify green spaces in the input image.
Instance segmentation is used in transportation planning to classify road features, sidewalks, and traffic signs. This helps optimize traffic flow and improve pedestrian safety.
A notable project is the European Union’s Smart City initiative, where segmentation techniques help with traffic management, urban development, and environmental monitoring.

Instance segmentation also brings precision to a field-level analysis in agricultural aerial imaging. It classifies different land areas like crops, soil, and water bodies.
For example, instance segmentation can differentiate between various crop types, evaluate the health of individual plants, and identify specific areas impacted by diseases or stress.
The European Union’s Copernicus program uses semantic segmentation with instance segmentation to enhance precision farming techniques.

Construction Site Safety and Monitoring
Instance segmentation can play a key part in ensuring safety and efficiency at construction sites. For example, it can be used to create virtual safety zones, or geofences, around heavy machinery.
A real-world application involves setting up cameras that monitor an excavator. The instance segmentation model is trained to accurately segment both the excavator and any workers nearby.
A virtual boundary is drawn around the excavator's swing radius. If the model detects a worker's segmentation mask entering this restricted zone. Then the system automatically triggers an alarm and alerts both the worker and the machine operator to prevent a potential accident.
Beyond this, the insights gathered can help optimize the site layout and workflow, which boosts productivity.

Evaluation Metrics and Challenges in Instance Segmentation
Building and deploying instance segmentation models comes with its own set of challenges. Thus, we use specific metrics to evaluate how well they perform.
Below, we outline how to measure performance and discuss common challenges, along with some solutions.
Evaluation Metrics for Instance Segmentation
The primary metrics for instance segmentation are Average Precision (AP) and mean Average Precision (mAP). They measure how well the predicted masks match the ground truth masks.
Another metric is Precision, which measures how many predicted objects were correct (true positives vs. false positives). And recall measures how many ground-truth objects were detected.
There are some newer metrics like Boundary IoU (Intersection-over-Union) and Boundary AP. These metrics reward precise segmentation masks, particularly when it comes to object boundaries, where subtle contours are critical.
While evaluation metrics help quantify model performance, understanding real-world deployment challenges is equally important.
Key Challenges and How to Address Them
While instance segmentation offers powerful capabilities, it also comes with its own set of challenges that need to be addressed for optimal performance.
Occlusion and Crowded Scenes: When objects overlap or are closely packed, it becomes difficult for a model to separate objects and create distinct masks.
- Solution: Use transformer-based models or box-free architectures that better capture spatial context and object interactions.
Small Objects: Detecting and segmenting very small objects is a major challenge. They provide fewer pixels for the model to learn from, and features can be easily lost in the network. A feature pyramid network (FPN) is one technique used to help with this.
- Solution: Apply data augmentation like random crops, mosaic, multi-scale inputs, and adjust anchor or proposal settings to better detect small objects.
Annotation Quality and Domain Variability: Differences in annotation consistency and quality can skew evaluation. Poor annotation practices or inconsistent ground truth masks reduce model generalization.
- Solution: Ensure consistent, quality instance masks and use domain‑specific datasets to improve generalization across domains.
Class Imbalance: Real-world datasets are often imbalanced, with many examples of common objects like cars and very few examples of rare ones. This can cause the model to perform poorly on the rare classes.
- Solution: Use cost-sensitive or rebalanced loss functions, such as Focal Loss, Unified Focal Loss, or Seesaw Loss, to prioritize minority classes during training.
Real-Time Performance: For applications like autonomous driving or robotics, models must be both accurate and extremely fast. Achieving high accuracy at real-time speeds is a constant trade-off and an active area of research.
- Solution: Use lightweight, one-stage models like YOLACT or YOLO-NAS-Seg for fast inference without sacrificing accuracy.
Pro tip: Looking for the right tool to annotate your data? Check out our list of 12 Best Data Annotation Tools for Computer Vision (Free & Paid).
Future Directions and Research Trends
Emerging methods, like DINO-based self-supervision and U2Seg, create pseudo-labels for "things" and "stuff." This approach helps minimize the need for extensive annotations in panoptic and instance segmentation.
Zero-shot and promptable models, such as Meta’s SAM, enable universal instance segmentation even on unseen image categories without requiring fine-tuning.
As sensors like LiDAR become more common, there is a growing need for instance segmentation in 3D point clouds. New research adapts 3D segmentation models with transformers for efficient processing in autonomous driving and medical robotics.
There is an ongoing effort to make instance segmentation models smaller, faster, and more efficient, with models like MobileSAM, FastSAM, and EfficientTAM. The goal is for these models to run directly on edge devices like smartphones, drones, and cars.
Pro Tip: Learn how self-supervised learning trains models using data they have, which cuts down on the need for manual labeling.
How Lightly AI Improves Instance Segmentation Workflows
The challenge in instance segmentation is the cost and effort required to create quality training data. Manually creating pixel-perfect ground truth masks for thousands of images is a major bottleneck.
LightlyOne tackles the data problem and makes it easier for you to build better models. It finds the most valuable data from your raw, unlabeled images.
Instead of labeling everything, you can use LightlyOne to build an active learning workflow. Then select the most informative samples to annotate.
LightlyTrain addresses the data problem from another angle by using self-supervised learning. It helps you to pretrain your instance segmentation model on large amounts of unlabeled data.
Then the pretrained model is fine-tuned on the smaller, curated dataset selected by LightlyOne. This process builds better instance segmentation models faster and reaches higher accuracy with far fewer labels.
Pro Tip: Understand the basics of contrastive learning that powers self-supervised methods.
Conclusion
Instance segmentation gives machines a new way to see the world. Instead of just drawing boxes around objects, it cuts out their exact shape down to the smallest detail. Knowing exactly where things are is vital for advanced applications like self-driving cars and robots.
Although it can be challenging to create such detailed data, new ML tools and methods like active learning are speeding up the process and simplifying it too. With the right tool and curiosity, you can start building your own instance segmentation models in no time.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


