
Understanding 3D Object Detection And Its Applications
Table of contents
Share blog post



3D object detection identifies and locates objects in 3D space by estimating their position, size, and orientation. Unlike 2D detection, it captures depth using data like LiDAR point clouds. It’s essential for applications in autonomous vehicles, robotics, and AR/VR, enabling more accurate spatial understanding and better handling of occlusion and perspective.
Share blog post
Here are some key information about 3D Object Detection that you might find useful
- What is 3D object detection?
3D object detection is a computer vision task that identifies and localizes objects in three dimensions. It estimates each object’s position, size, and orientation in space. Unlike standard 2D object detection, 3D object detection captures depth (the Z-axis) in addition to height and width.
- How is 3D object detection different from 2D?
3D detection uses sensors like LiDAR to create point clouds or depth maps. It provides spatial depth, unlike 2D detection, which relies on flat images. A 3D bounding box includes an object’s distance and orientation. It helps models determine the distance to objects. It also improves handling of occlusions and perspective changes.
- Why is 3D object detection important?
3D object detection is important for applications like autonomous vehicles, robotics, and AR/VR. For example, self-driving cars rely on 3D detection to accurately assess distances and prevent collisions, a task that would be insufficient with 2D alone.
- What data does 3D object detection use?
3D object detection usually works with point clouds from LiDAR, depth images from stereo cameras or RGB-D sensors, and sometimes a mix of different sensor inputs. These sources add the depth and spatial detail needed to build a full 3D view of the scene. Well-annotated datasets with 3D bounding boxes are then used to train and test the models effectively.
We’ve come a long way with object detection in computer vision. What started with detecting shapes in flat 2D images has now moved into understanding depth and space through 3D detection. This depth awareness is crucial for various industries, such as robotics and AR.
In this guide, we will walk you through everything you need to know about 3D object detection.
We will cover:
- What is 3D object detection
- Why 3D object detection is important (applications)
- Comparison: 3D vs. 2D object detection
- 3D object detection and tracking
- Resources and tools for 3D object detection
While Lightly currently focuses on 2D vision tasks, we're actively expanding into 3D data workflows. Soon, you'll be able to use:
- LightlyTrain to improve your 3D object detection models with smarter pretraining and fine-tuning.
- LightlyOne: to curate the most relevant 3D data to train on, reducing noise and improving model performance.
Stay tuned as we bring these capabilities to 3D vision :)
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What is 3D Object Detection?
3D object detection involves identifying and locating objects in a three-dimensional (3D) space. Unlike traditional 2D object detection, which only looks at flat, two-dimensional images, 3D detection estimates both the full shape and the position of objects.
This includes their exact location (x, y, z coordinates), size (length, width, height), and orientation (such as yaw, pitch, and roll angles). This information is usually gathered with sensors like depth cameras, LiDAR (which uses light to create point clouds), or stereo cameras (which use two cameras to see depth).
3D object detection creates a 3D bounding box around each object to capture a complete view of the scene, not just a flat 2D rectangle.
Interestingly, 3D detection can handle situations where objects are partly hidden (occlusions). It also works well when the viewing angle changes. This makes 3D object detection useful for tasks that need an accurate understanding of space.
💡Pro Tip: If you want a clear understanding of how classification outcomes like true positives and false negatives are counted before computing detection metrics, check out our Confusion Matrix article for a simple guide.
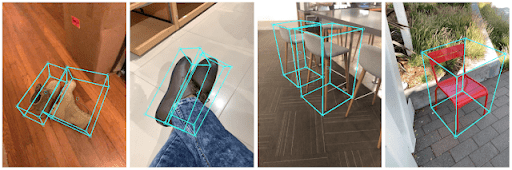
Why 3D Object Detection is Important (Applications)
3D object detection uses depth information to determine the location, size, and distance of an object. It also identifies exactly how it's positioned in the real 3D world. Such depth-aware analysis is vital to analyze spatial awareness in many real-life applications, including:
Autonomous vehicles (self-driving cars)
Self-driving cars and advanced driver-assistance systems (ADAS) rely on 3D detectors to perceive their surroundings in real-time. Autonomous cars use LiDAR, radar, and cameras to spot vehicles, people, cyclists, and obstacles in 3D.
For example, a 3D detection system can identify the exact location, size, movement direction, and speed of a pedestrian crossing the street. With this information, the vehicle’s planning system can predict movement and avoid collisions.

LightlyEdge is our solution for collecting data directly on the edge—built specifically for scenarios like autonomous driving. It’s loved by leading self-driving car companies for its efficiency and ease of deployment.
👉 Check out the demo video to see LightlyEdge in action.
Robotics and drones
Mobile robots and drones use 3D object detection to understand and interact with their surroundings.
For example, a warehouse robot uses 3D detection to locate and pick up specific objects from shelves. It then uses their exact position in space to retrieve them accurately. It also uses 3D detection to avoid obstacles at different heights while moving through its environment.
Drones equipped with depth cameras or LiDAR can detect 3D positions of buildings, power lines, or landing targets to navigate 3D space. For manipulation tasks, a robotic arm may use 3D object detection to recognize and grasp objects on a table. It must know their exact 3D coordinates relative to its position, not just their appearance in an image.

Augmented Reality (AR) and Virtual Reality (VR)
3D object detection improves experiences by accurately blending virtual content with the real world in AR/VR. For AR applications, your device, such as AR glasses, must detect real-world surfaces and objects in 3D so that virtual objects can interact with them realistically.
For example, AR headset systems use 3D plane detection and object detection to place virtual characters on your floor. They can also make them appear behind your furniture.
This allows for real-time object tracking. Virtual elements can bounce off or wrap around physical objects in a realistic way.

Immersive gaming and simulation
Building on augmented and virtual reality, many games and simulations use 3D object detection to populate and update virtual worlds based on real-time sensor inputs.
For example, in mixed reality games, a camera scans the room in 3D. Then, virtual elements like monsters or targets are placed into that space in a way that fits the real-world layout.
Additionally, in robotics simulation or AI agent training environments, 3D detection algorithms are used to explore and connect real sensor data to the simulated environment. This makes it easier to adapt to real-world conditions and build more realistic training scenarios.
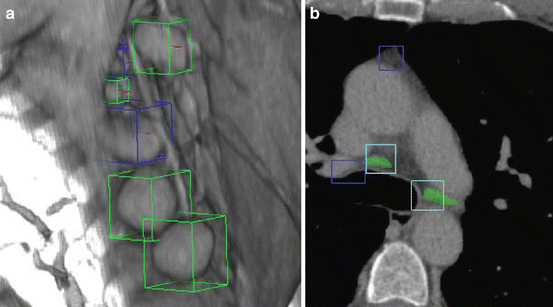
Healthcare and medical imaging
Outside of industrial use, 3D object detection is being applied in medical fields. When interpreting volumetric medical scans like CT or MRI, it helps spot anatomical structures or tumors.
For instance, a 3D detection model can be trained to spot and pinpoint tumors in an MRI scan by placing a 3D bounding box around the suspected area. This kind of automation can help doctors by quickly highlighting regions that may need closer attention during diagnosis.
Mapping and environmental scanning
3D object detection also helps with building detailed maps of the environment through methods like SLAM (Simultaneous Localization and Mapping).
As robots or self-driving cars move around, they detect items like traffic signs or trees in 3D. This adds useful context to the map and helps them understand their surroundings better.
Drones performing 3D scans of buildings can detect objects and identify structures. Examples include windows, doors, and damage within the 3D point cloud of a building. This makes inspections more detailed and helps create a clearer picture of the building’s condition.

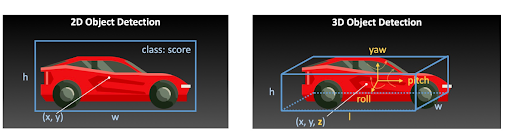
Comparison: 2D vs 3D Object Detection
Understanding the differences between 2D and 3D object detection is key to choosing the right method for your computer vision tasks. Let's compare traditional 2D with the more advanced 3D object detection.
3D Object Detection and Tracking
3D object detection finds objects in three-dimensional space. Object tracking, on the other hand, keeps track of each object’s identity and path over time.
It detects objects across a sequence of images or point clouds. Then it follows their movement and orientation from one frame to the next.
Here is the typical workflow for object tracking:
- Detect Objects in Each Frame: A 3D object detection system looks at sensor data like LiDAR data or stereo camera feeds. It finds objects and generates their precise 3D bounding boxes in the current frame.
- Associate Detections Across Frames: Matches new detections with existing object tracks. It uses techniques like 3D IoU and centroid distance to find likely pairs. The Hungarian algorithm helps make the best assignments and ensures consistent identities, even when objects briefly disappear or appear differently.
- Filter Trajectories and Predict Future Positions: After matching, filtering techniques like 3D Kalman Filters help smooth out object motion and estimate where each object is likely to appear in the next frame.
💡Pro tip: Check out our Guide to Reinforcement Learning.
Resources and Tools for 3D Object Detection
Several open-source frameworks, like OpenPCDet and MMDetection3D, speed up 3D object detection research. They support point clouds and multi-modal data with comprehensive deep learning implementations.
Libraries like PCL (Point Cloud Library) and Open3D make it easier to process and visualize 3D point cloud data. Use LightlyOne to analyze large point-cloud datasets, generate quality embeddings, and intelligently select the most informative 3D samples. It reduces the annotation costs and improves model performance on tasks such as KITTI and nuScenes.
Much of the progress in 3D object detection is driven by large benchmark datasets that provide annotated 3D bounding boxes and sensor data. Key datasets include:
- KITTI 3D Object Detection: The KITTI dataset contains about 7,000 training scans. It includes LiDAR scans, images, and annotated 3D bounding boxes. These are used for research in 3D object detection in self-driving cars.
- Waymo Open Dataset: A large-scale dataset with 1,000+ scenes from an autonomous car’s sensors in varied conditions. Waymo’s dataset is much larger than KITTI and more challenging. It serves as a modern benchmark for scaling up models.
- nuScenes: The dataset includes data from cameras, LiDAR, and radar. It provides 3D object box annotations for detection and speed measurement.
- Indoor Datasets (SUN RGB-D, ScanNet): Focused on indoor scenes, these datasets offer depth data for detecting objects like furniture and household items.
💡Pro Tip:If you are exploring which visual backbones work best for 3D tasks, our DINOv2 Reproduction article provides a hands-on look at reproducing a powerful SSL model that can enhance downstream feature quality.
Pretrained models and research code
Many research papers release trained models and code, often starting projects with pretrained detectors like PV-RCNN on nuScenes for fine-tuning or system integration.
Frameworks like OpenPCDet offer model zoos and config files. They make it easier to reproduce results and compare baselines. This helps teams move faster in development.
To support this workflow, LightlyTrain helps you pretrain and fine-tune models on curated 3D data, tailored for your specific task or environment. It integrates seamlessly into your existing pipeline and boosts performance with smarter training data.
👉 Check out the LightlyTrain demo video and GitHub repo for updates - don’t forget to star and watch!
Future Directions and Ongoing Research
Future directions in 3D object detection focus on new methods like multi-modal fusion. This means combining sensors such as LiDAR, cameras, and radar using BEV-based frameworks like BEVFusion.
Another key development, as technology advances, is the adoption of transformer-based architectures such as 3DETR, which promise better accuracy and efficiency.
Researchers are also focusing on the use of self-supervised and unsupervised learning methods to reduce dependence on labeled data. Tools like Lightly SSL and ReCon support this trend by helping teams extract meaningful representations from unlabeled sensor inputs.
Additionally, efforts are ongoing to make 3D object detection systems faster in real time. Researchers are exploring new sensor types like imaging radar, which helps continual learning for system adaptability.
💡Pro Tip: Understand the basics of contrastive learning that powers self-supervised methods.
Conclusion
3D object detection brings depth and spatial awareness to computer vision. It’s vital for use cases like autonomous driving, robotics, and AR/VR. While it demands more compute and complex data, the payoff is better accuracy and real-world understanding.
Advances in sensors and learning methods are making it faster and easier to adopt. As technology evolves, it’s becoming a key part of how we build immersive environments and more responsive AI in the real world.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


