
Reinforcement Learning Guide: Algorithms, Applications, and Techniques
Table of contents
Share blog post



Reinforcement Learning (RL) is a machine learning approach where agents learn to make decisions via trial and error. By interacting with their environment and receiving rewards, they improve over time to achieve long-term goals in tasks like robotics, games, and more.
Share blog post
Below, you can find a quick summary of key points about reinforcement learning
- What is reinforcement learning, and how does it work?
Reinforcement learning (RL) is a machine learning method where an agent learns by interacting with its environment. It takes actions, receives rewards, and refines its strategy over time to maximize long-term gains through trial and error.
- How is reinforcement learning different from supervised or unsupervised learning?
Unlike supervised learning, which uses labeled data, or unsupervised learning, which finds patterns in unlabeled data, RL learns from feedback. The agent explores actions, evaluates outcomes via rewards, and balances exploration and exploitation.
- What are some examples of reinforcement learning in real life?
RL is used in robotics, autonomous driving, game-playing agents (like AlphaGo), financial trading, and NLP systems. These agents learn behaviors that maximize long-term performance by adapting through experience and feedback.
- How is reinforcement learning different from supervised or unsupervised learning?
RL algorithms include value-based methods (e.g., Q-learning), policy gradients (e.g., REINFORCE), actor-critic methods, and model-based approaches. Each type has unique strategies for decision-making and optimizing agent performance.
Reinforcement learning (RL) connects data-driven perception to adaptive control. It allows agents to learn action policies through direct interaction and feedback. You can use RL to adapt models to unpredictable inputs where traditional supervised learning falls short.
This guide helps you apply RL to real-world projects where models need to learn and adapt independently.
In this guide, we will cover:
- What is reinforcement learning?
- Core concepts of reinforcement learning
- How does reinforcement learning work?
- Reinforcement learning vs. supervised vs. unsupervised learning
- Important reinforcement learning algorithms and techniques
- Real-world applications of reinforcement learning
- Reinforcement learning in natural language processing
While reinforcement learning focuses on learning from interaction, it still relies on high-quality perception and data inputs. At Lightly, we’re building tools to support RL workflows through:
- LightlyTrain: Pretrain visual models that serve as strong perception backbones for RL agents.
- LightlyOne: Curate the most informative visual data to accelerate learning and improve sample efficiency.
These capabilities are especially useful when RL agents need to process complex visual environments. More to come soon.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What is Reinforcement Learning?
Reinforcement learning trains an agent to optimize sequential decision-making by interacting with an environment to maximize cumulative reward. At every time step, the agent perceives the current state, chooses an action, and receives numeric feedback as a reward signal.
The agent aims to acquire a policy, which is a mapping of states to actions that maximize long-term cumulative reward. This process is typically formalized as a Markov Decision Process (MDP).
The framework provides a mathematical framework to model reinforcement learning problems where outcomes depend on both current actions and future rewards.
How is Reinforcement Learning different from other types of Machine Learning
Supervised machine learning uses labeled data to train models to recognize consistent input-output patterns. Unsupervised learning identifies structure in unlabeled data, like clustering or dimensionality reduction.
However, reinforcement learning focuses on sequential decisions where each action affects future outcomes. The agent must balance immediate rewards with long-term impact.
Rather than learn using a fixed dataset, RL can learn through direct interaction with delayed feedback, suitable for real-world scenarios.
Advantages of Reinforcement Learning
What are some of the main benefits of reinforcement learning that make it such a potent method for solving real-world problems?
- Autonomous strategy discovery: Agents do not use labeled examples to learn behavior. Rather, they experiment with their surroundings, assess the results, and refine their tactics by trial and error or feedback cues.
- Long-term optimization: Policies are optimized for long-term rewards, even when short-term actions appear suboptimal.
- Adaptability: RL agents can adapt to uncertain and changing environments. It is suitable for fields like reinforcement learning, robotics, and intelligent transportation systems.
- Scalability: Suitable when manual rule design or supervised labels are impractical. RL scales across complex tasks without needing constant human input and supports large-scale automation.
- Delayed rewards resilience: Addresses cases where behavior yields future rewards that are delayed in time. RL learns to associate actions with eventual outcomes, which is critical in domains like finance, healthcare, and game-playing AI.
Pro tip: Learn more about various computer vision applications.
Deep Reinforcement Learning
Deep reinforcement learning combines deep neural networks with RL algorithms to handle high-dimensional state and action spaces. Traditional RL used explicit tables for action values or policies, which became impractical as state spaces grew.
Deep neural networks act as function approximators that learn compact representations and value functions. This helps models generalize to unseen states and perform well in continuous spaces.
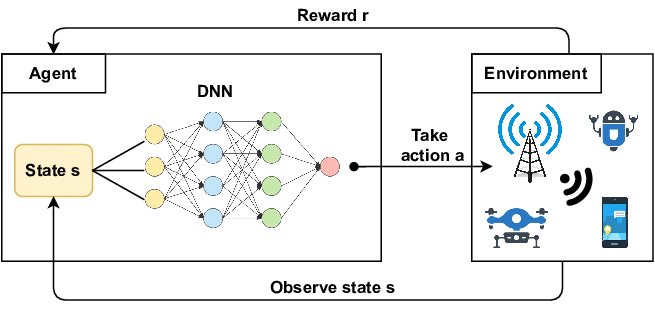
So why Deep RL?
Storing a separate value for each state-action pair, like raw images, is impractical because the state space is sufficiently large to be handled directly. Instead, deep reinforcement learning uses neural networks to approximate value functions or policies.
This method uses the representational power of deep learning to learn over large state spaces and model complex relationships between states, actions, and rewards.
It has been successful in areas such as natural language processing and robot learning, showing promising results in real-world environments.
Pro Tip: Distance metrics, latent-space clustering, and vector similarity all live inside an “embedding space.” Take a quick tour through The Importance of Embeddings in Modern Deep Learning to see why that matters for deep RL.
Core concepts of Reinforcement Learning
RL relies on an agent-environment interaction loop, where each action and reward shape the agent's behavior. Let’s look at each component of RL:
- Agent: An agent is an autonomous decision-maker who perceives the state space of the environment. It acts according to its policy and optimizes its strategy to maximize the sum of future rewards.
- Environment: The environment defines states, actions, transitions (which can be random), and the rewards linked to those transitions. In deep reinforcement learning, environments frequently involve large and complex state spaces.
- State: A state represents the environment’s condition at a given time step. It forms the basis for decision-making in reinforcement learning. In many real-world scenarios, states can include high-dimensional sensory data processed by deep neural networks.
- Action: An action is the selection that the agent makes at each time step. It may be discrete (e.g., left, right) or continuous (e.g., a particular physical torque or steering angle).
- Reward: A scalar signal from the environment given after each action. It reflects immediate feedback and helps guide long-term learning.
- Return (Cumulative Reward): The total reward is the sum of all subsequent rewards for a given state, typically discounted by gamma to favor earlier rewards. It weighs short-term vs. long-term objectives, informing policy optimization.
- Policy: A policy is a mapping from states to actions that defines the agent’s behavior. Policies can be deterministic or stochastic. Training seeks to learn an optimal policy that maximizes expected returns.
- Model: Model-based RL uses a model of the environment's dynamics, including transition probabilities and reward functions. Agents use this to plan by simulating future interactions. Model-free RL is based solely on real experience.
How does Reinforcement Learning work?
Reinforcement learning tackles how an agent chooses actions in uncertain environments to maximize long-term rewards.
Let's look at the working components of RL:
State space
The state space S is a set of all possible configurations that describe the environment at any given time. Every state carries the information that the agent will use to make decisions.
It can be measurements, context variables, or historical summaries processed by deep neural networks in deep reinforcement learning.
For example, in dynamic pricing, a state may add current demand estimates, inventory levels, and time of day.
Action space
Actions are all operations the agent can perform to influence the system. These can be:
- Discrete: Choosing from a fixed set of options (e.g., move left, move right, pick item A, or pick item B).
- Continuous: Adjusting values within a range (e.g., setting a steering angle or throttle level in autonomous driving).
The complexity of the action space impacts how efficiently RL algorithms can explore and learn optimal strategies.
For example, in a robotic arm control task, discrete actions might involve selecting joints to move, while continuous actions determine how far or fast each joint should rotate.
Transition dynamics
The transition model describes how the environment evolves in response to the agent's decisions. They define which of the following states are possible and how likely they are to happen.
This property assumes that future outcomes depend only on the current state and action, not the full history of past events.
For example, take an autonomous drone flying indoors. Given that the drone is at (2,3) and chooses the action of moving forward, it is likely to reach (3,3).
But when there is some airflow disturbance or an obstacle, then the transition model may give a lower probability of reaching (3,3).
Reward signal
Rewards measure the cost or reward of every action. The reward function R (s,a,s′) assigns a scalar value to the utility of each transition. For example, in supply chain optimization, rewards can be calculated as revenue minus holding and shortage costs.
In deep RL, the reward signal guides the training process of the neural network policy.
Discount factor
The discount factor (gamma) regulates the degree to which the agent prefers future rewards to immediate rewards. A low discount factor causes the agent to concentrate on short-term gains. At the same time, a higher discount factor allows it to consider the long-term effects of its actions.
This factor must be tuned to strike a balance between short-term payoff and long-term planning, particularly in an environment where decisions have delayed outcomes.
Policy
A policy defines how the agent selects actions based on the current state. In simple cases, it always picks the same action for a given state. More advanced policies learn to adapt and choose different actions depending on context.
The agent updates its policy over time to favor actions that lead to higher rewards. Algorithms like Actor-Critic and Proximal Policy Optimization (PPO) iteratively improve policies through trial and error.
For example, in a self-driving car, the policy might map road conditions and traffic signals to actions like accelerating, braking, or turning. As the policy improves, the car learns to navigate more safely and efficiently.
Horizon and Episode
Many problems are broken into episodes in reinforcement learning. These are bounded sequences of steps where the agent interacts with the environment, starting in an initial state and ending in a terminal state.
Consider an episode as a full trial, like simulating until a task is completed or fails. Upon the termination of an episode, the environment is reset, and the agent has an opportunity to begin again and improve its strategy.
There are episodic problems, which have a natural termination point, such as a batch of production or a delivery route. Others are ongoing, where the process does not come to an end, requiring temporal difference learning and a discount factor to avoid overvaluing distant outcomes.
In tasks that continue indefinitely, a discount factor reduces the weight of long-term consequences. This creates an effective planning horizon so the agent doesn’t overvalue outcomes that are too far away to predict accurately.
For example, in stock trading, each trading day can be treated as an episode, while in power grid management, decisions run continuously and require long-term planning.
Warehouse Robot Navigation Example
Consider an example of reinforcement learning robotics where a robot needs to learn how to navigate a warehouse to pick and deliver items efficiently.
The state consists of the current position, the obstacles’ locations, and the target item position. The action space includes movement commands, such as going forward, turning, or stopping.
Every movement results in a state transition. The position of a robot changes, and it gets a reward that indicates progress. A positive reward is received when reaching the target location, and penalties are received when unnecessary movement or collision occurs.
Over multiple episodes, the robot experiences different tasks. Each episode starts with a new item to deliver and ends once the delivery is complete. Through repeated interaction, the robot learns which decisions reduce delivery time and avoid errors.
Through trial and error, quantifying the results, and refining its decision-making process, the robot creates an effective policy. This allows it to complete deliveries safely and efficiently, even without a pre-programmed map of all possible scenarios.
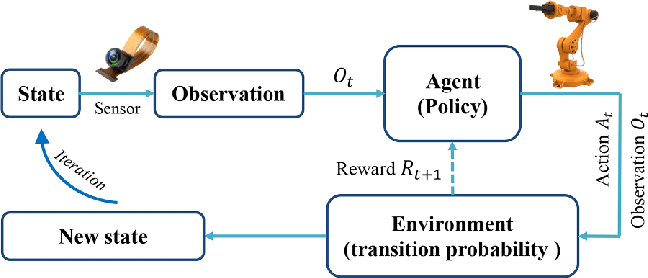
Reinforcement Learning vs. Supervised vs. Unsupervised Learning
Reinforcement learning combines sequential decision-making, real-time interaction with the environment, and reward-based optimization. Unlike supervised learning, which uses labeled input data, RL agents learn by observing how their actions influence long-term outcomes.
This iterative training process helps agents adapt to changing environments instead of relying on fixed examples. In reinforcement learning, each decision affects future states and long-term performance, creating dependencies across sequences of actions.
Techniques like dynamic programming and temporal difference methods are often used to improve policy estimation and maximize the agent's effectiveness.
Supervised and unsupervised learning typically process static datasets and don't require credit assignment over time steps. In contrast, RL agents must balance exploring new actions that might offer better rewards with exploiting known strategies. This trade-off is unique to reinforcement learning, as traditional methods deal with predefined data and don’t face this dilemma.
Pro Tip: Self-supervised learning lets you pretrain on raw data and still reap many of the benefits of supervision. Check out our Engineer’s Guide to Self-Supervised Learning to see how it bridges the gap between unsupervised and supervised methods.
Knowing the difference between these methods will make it easier to determine when to apply each one. The table below presents the main features of reinforcement, supervised, and unsupervised learning.
Along with these approaches, engineers integrate RL with artificial intelligence in deep reinforcement learning courses and experiment with Python code to develop solutions.
As a data scientist, software engineer, or machine learning engineer, you need to understand these differences to acquire new skills to solve complex decision-making problems.
Important Reinforcement Learning methods and algorithms
Reinforcement learning algorithms are broadly classified according to the method by which they learn policies. The majority of practical algorithms in practice are model-free. However, model-based concepts are again gaining popularity due to their sample efficiency.
Let's discuss a few of them.
Value-based methods
Value-based reinforcement learning uses an estimate of how good it is to be in a state or take an action, and selects the best option based on its value. The agent modifies these estimates over time by experience.
This is effective when the actions are discrete and the agent can frequently revisit states to make them more accurate. Here are some of them:
Q-Learning
Q-Learning trains an action-value function that approximates the expected return of taking an action in a state and subsequently following the optimal policy.
The policy is obtained by choosing the action with the maximum estimated value. It works well with discrete action spaces and serves as the basis for many early advances in RL, such as Deep Q-Networks (DQN).
SARSA
SARSA is like Q-Learning, but instead of assuming the agent will always pick the best action next, it updates values based on the action the agent takes.
This on-policy method is more conservative and tends to be more appropriate in settings where exploration is risky.
Policy Gradient Methods
Policy-gradient methods operate directly by updating the policy to maximize expected rewards rather than approximating value functions. This method is especially applicable to problems where actions are continuous or require random sampling.
REINFORCE
The most basic policy gradient algorithm is called REINFORCE. It directly updates the parameters of a stochastic policy to increase the probability of actions in proportion to their observed cumulative rewards.
Although conceptually simple, REINFORCE suffers from high variance and is sample inefficient.
Proximal Policy Optimization (PPO)
PPO enhances the policy gradient stability by restricting the amount of change that the policy can undergo in each iteration. It accomplishes this through a clipped objective function that avoids large, destabilizing parameter jumps.
PPO is favored due to its simplicity of implementation, stability, and performance on a wide range of continuous and discrete control problems.
Actor-Critic Methods
Actor-critic algorithms incorporate two elements. The policy network is the actor that chooses actions. The critic approximates the worth of such actions and gives low-variance feedback. This configuration generates more sustainable gradients compared to pure policy approaches.
Due to the synergy, actor-critic methods currently drive numerous state-of-the-art benchmarks. They combine the sample efficiency of value learning and the flexibility of policy gradients on continuous actions.
A3C / A2C
Asynchronous Advantage Actor-Critic (A3C) uses parallel training across reinforcement learning agents to achieve sample efficiency and update stability. A2C is a synchronous variant that accumulates experience in batches, rather than asynchronously.
Both use an actor to suggest actions and a critic to analyze them by approximating value functions.
Deep Deterministic Policy Gradient (DDPG)
DDPG builds on actor-critic in continuous action spaces with deterministic policies. It integrates the experience replay and target networks to boost stability in training.
The actor network produces continuous actions directly, whereas the critic approximates Q-values to determine learning. It can learn high-dimensional continuous control tasks efficiently.
Twin Delayed DDPG (TD3)
TD3 is an improvement of DDPG that mitigates overestimation bias in Q-value estimates, a common issue in function approximation. It has two distinct networks of critics and updates using the smaller of the two Q-values, which makes learning more conservative and stable.
TD3 lags behind policy updates compared to value updates and adds noise to target actions, which smooths learning in continuous domains.
Soft Actor-Critic (SAC)
SAC is a hybrid of maximum entropy reinforcement learning and an off-policy actor-critic method. In contrast to deterministic approaches, SAC employs a stochastic policy to sample actions and explicitly maximizes expected return and entropy.
This encourages broader exploration and prevents premature convergence. The entropy term balances exploration and exploitation, keeping SAC robust and sample-efficient in complex continuous action spaces.
Model-Based RL
Model-based reinforcement learning uses a different framework to learn an internal model of the environment. The agent can plan and simulate the results before taking actual actions using this model.
Monte Carlo Tree Search (MCTS)
Monte Carlo Tree Search (MCTS) operates by iteratively choosing and expanding nodes, simulating results, and revising estimates based on the results. The search becomes more certain about the best moves as it visits each action more frequently.
Simulation is avoided in AlphaGo and subsequent systems by using neural networks to approximate value and propose potentially good moves. This strategy minimizes the search possibilities that must be explored, while still ensuring good long-term performance.
Noise in the starting move preferences and reuse of the search tree between steps turns MCTS into an online learning planner. This setup allowed AlphaZero to reach superhuman performance within hours.
Other methods use neural networks to learn environment transitions and rewards, which agents can then use to plan. This can boost sample efficiency, but must be handled with caution in terms of model errors.
Types of Reinforcement Learning Algorithms: Comparison
Here’s a quick reference to see how these core reinforcement learning algorithms differ in their goals and strengths:
Pro Tip: Even before your agent makes its first move, teach the network to identify what is similar and what is different. Contrastive methods like SimCLR create a well-structured embedding space, reducing the need for thousands of exploration steps in downstream tasks. Read our Introduction to Contrastive Learning.
Real-World Applications of Reinforcement Learning
Reinforcement learning now plays a major role across industries. Here are some of the key domains where it drives real-world systems.
Robotics and Control Systems
Reinforcement learning is more suitable for robotics since it enables robots to learn how to behave step by step in real-time. Rather than coding all behaviors, you allow the robot to know what works by trial and error in its environment.
Robot Locomotion
RL allows legged and wheeled robots to acquire locomotion policies via direct trial and error. Agents find torque or position control policies to walk, run, or recover from disturbances.
DeepMind has conducted significant research with humanoid models that were trained in simulation to develop agile movement skills, which were later transferred to physical robots.
Robotic Manipulation
RL has accelerated complex manipulation tasks, including grasping, assembly, and tool use. For example, a robotic hand developed by OpenAI was able to learn how to solve a Rubik's Cube using domain randomization and reinforcement learning.
This involves visual perception with control policies that generalize across settings.
Drone and Process Control
RL has also been used in drone flight to achieve accurate maneuvers that surpass those of linear controllers.
RL helps optimize process parameters and HVAC systems by learning control strategies that cut energy costs or improve throughput.
The data center cooling project by DeepMind has demonstrated a 40% reduction in cooling energy. RL was used to optimize the complex interactions between equipment and ambient conditions.
Traffic Signal Optimization
City traffic lights present a large-scale sequential optimization challenge. RL agents learn timing policies that adapt to real-time vehicle flow, reducing congestion and travel delays.
This is extended to networked intersections that coordinate in a distributed manner with multi-agent reinforcement learning.
Natural Language Processing Reinforcement Learning
Supervised machine learning remains the primary approach for core NLP tasks. However, reinforcement learning is valuable for optimizing goals that depend on long-term consistency, user satisfaction, or sequence-level rewards.
Chatbots and Dialogue Systems
Conversational agents are fine-tuned with RL to boost contextual relevance and engagement. Rather than only imitating the next token, the learned reward model or human feedback assesses complete responses.
For example, Microsoft’s social chatbot XiaoIce uses a Markov decision process to optimize for long-term user engagement. On average, it reaches 23 conversation turns per session with hundreds of millions of users.
Reinforcement Learning with Human Feedback (RLHF)
RLHF fine-tunes large language models such as InstructGPT and ChatGPT. It combines supervised pretraining with reinforcement learning, where a reward model learns to predict which responses humans prefer.
Proximal Policy Optimization (PPO) optimizes the policy (the language model) to yield outputs consistent with human expectations.
Translation and text summarization
Reinforcement learning allows the optimization of tasks at the sequence level, like summarization and translation. Rather than working with only supervised goals, RL optimizes models to maximize other metrics, including ROUGE and BLEU.
Neural networks in these workflows are often combined with policy gradient methods to maximize the relevance and diversity of outputs. Training can be further stabilized and made more sample-efficient with Monte Carlo techniques.
Information retrieval and question answering
Reinforcement learning is applied to train agents that gather relevant evidence before producing answers. Their actions can include choosing documents, navigating information spaces, or ordering content based on relevance.
Rewards are given for correct answers and fast retrieval, combining data mining techniques with policy optimization. Ground truth annotations and simulation are also used in some systems to improve the performance of the agent before deployment.
💡Pro tip: For RL systems deployed at the edge, our Navigating the Future of Edge AI: Observability and Intelligent Data Selection guide outlines how intelligent data routing improves on-device feedback loops.
NLP-Related recommendation systems
Reinforcement learning helps optimize content recommendation engines by focusing on long-term user engagement and sustained interactions. Policies are trained to display a series of articles or items that change over time according to the user's preferences.
This iterative learning strategy combines training RL models with large-scale input data and performance metrics to enable scalable production deployment.
Conclusion
Reinforcement learning has become a powerful way to train agents for sequential decision-making. As it matures, research is shifting toward making RL more sample-efficient, stable, and easier to scale.
Blending RL with supervised and unsupervised learning can help close performance gaps and make adoption smoother. But real-world deployment will also require systems that are transparent, reliable, and easy to interpret. Model-based and offline learning will be key to applying RL in critical areas like healthcare, logistics, and finance.
RL is moving quickly, and the real challenge now is learning how to use it effectively in the systems we build next.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)



{kind=link}