
Scanning Luggage for Dangerous Items with LightlyTrain
Table of contents
Share blog post



Discover how LightlyTrain enhances YOLO11 to swiftly detect dangerous items in luggage X-ray scans. Results show improved accuracy, higher recall, and quicker training, essential for efficient and secure airport baggage inspection.
Share blog post
Here is the key information on how LightlyTrain boosts luggage scanning with YOLO11 at airport security checkpoints.
- Enhanced Threat Detection Using AI:
LightlyTrain effectively trains YOLO11 models on luggage X-ray scans, significantly improving detection of dangerous items like guns, hammers, and knives, increasing overall security.
- Outstanding Accuracy with Few Labels:
By leveraging unlabeled data through advanced pretraining methods, LightlyTrain enables YOLO11 to achieve high detection accuracy even when very few labeled images are available.
- Faster, Cheaper Model Training:
Models pretrained with LightlyTrain converge up to three times faster during fine-tuning, saving valuable time and computing resources compared to traditional supervised methods.
Introduction
Many of us have probably experienced the following situation: You are at the airport, boarding time is quickly approaching, but there is still a long queue ahead of you at the security check. The officers are already scanning items at full capacity, but it's still a lengthy and manual process; every piece of luggage has to be manually inspected on the screen. What if the whole inspection process could be automated? Could recent advances in computer vision and deep learning help to make this process faster and equally secure?
In this blog post, we will try to explore just that. We will leverage the PIDray dataset, a large-scale dataset of airport X-ray images and train a model to detect dangerous items in the luggage. Specifically, we will use LightlyTrain to pretrain a YOLO model on unlabeled images from the dataset, and then we fine-tune it on a small number of labeled samples.
The goal is to demonstrate how LightlyTrain can be used for pretraining models on domains that are very different from the natural images typically used for pretraining, such as the COCO or ImageNet datasets.
Dataset
The PIDray dataset is a collection of around 125'000 images of luggage X-rays, together with labels for dangerous items such as guns, lighters, hammers and more. Object detection on this dataset is a challenging task, since the objects are often occluded by other items in the luggage.
The dataset is also strongly imbalanced, with many images containing no dangerous items at all, which strongly contrasts with standard datasets such as COCO, where most images contain at least one object of interest. Additionally, the pixel value distribution is also very different from natural images (photographs), since the images are acquired by X-ray scanners. All of these factors make this dataset a challenging benchmark for object detection models and a good candidate for pretraining with LightlyTrain, which is designed to overcome the limitations of supervised pretraining on natural images, such as background bias and domain shift. LightlyTrain is better suited to this task, since it first learns very strong abstract features of the image, which are not bound to specific objects or classes and those imbalances therefore matter less.
💡Pro tip: For safety-critical vision tasks, our An Introduction to Contrastive Learning for Computer Vision article highlights how contrastive embeddings boost detection robustness even with limited labels.
To illustrate above points, we can take a look at the distribution of the labels in the training set.
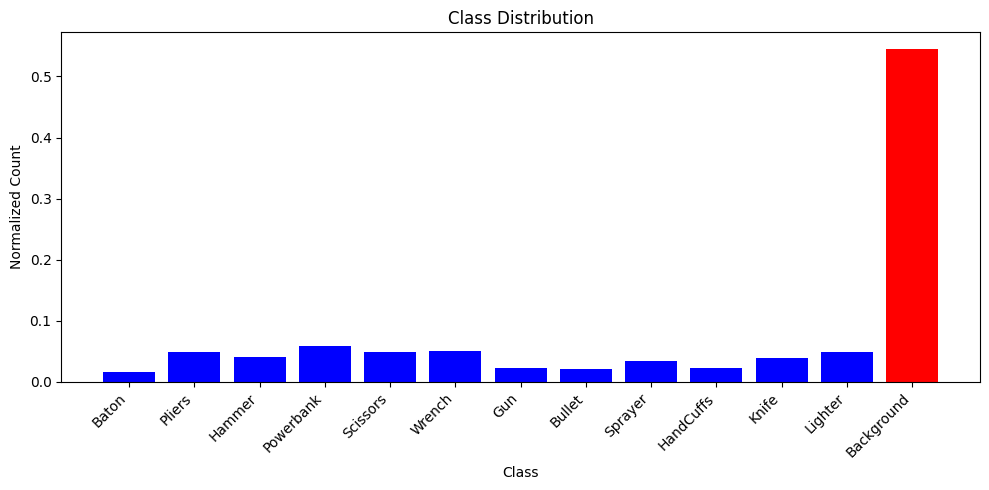
As we can see, more than half of the images do not contain any dangerous items at all – this reflects the real world use case, since most of the luggage will be completely harmless. The classes are also not all equally represented, however the imbalance in that regard is not very extreme.
We can also get a sense of what the images look like and how different they are from natural images by visualizing some samples from the training set together with the corresponding bounding boxes.
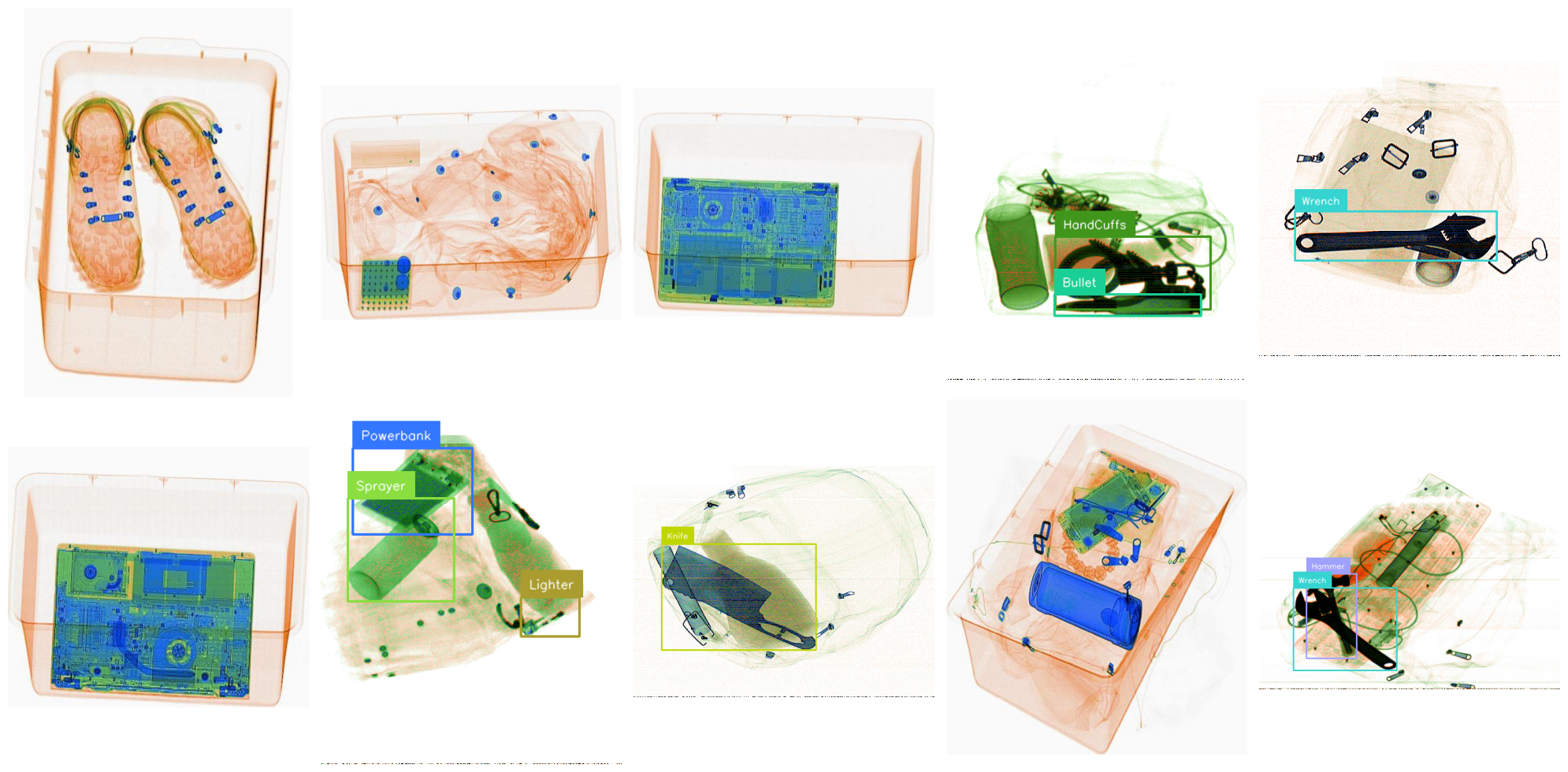
As can be seen, some of the images are relatively noisy and the majority of the pixels is very bright, indicating complete transparency to the X-rays. We can also observe that occlusions in X-ray images are very different from occlusions in natural images, since in most cases of occlusions will not completely hide parts of the object, but rather adjust the transparency along the occlusion boundary.
This can be additionally challenging for object detection models that were pretrained on natural images.
The YOLO11 Model
The detection model of our choice will be YOLO11, the most recent version of the YOLO family of models from Ultralytics. These models leverage a CNN backbone to extract features from the input image, which are then used to predict bounding boxes and class labels for the objects in the image by means of a detection head. YOLO11 is designed to be fast and efficient, making it suitable for real-time object detection, which is a core requirement for quickly scanning luggage at airports. In particular, we will use the YOLO11s (s for "small") model from the Ultralytics repository.
Using LightlyTrain, we will only pretrain the CNN backbone to extract robust features, while the detection head will remain unchanged until the fine-tuning stage, where we train the whole model towards the specific task of detecting dangerous items in luggage.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Pretraining with LightlyTrain
For pretraining the YOLO11s backbone, we will utilize LightlyTrain's knowledge distillation from DINOv2. DINOv2 is both, a self-supervised learning method and also a foundation model, that has shown strong performance on a wide range of compute vision tasks. It can therefore act as a very powerful teacher to the CNN backbone (the student) and help it learn robust and rich features from unlabeled images.
Since we can only pretrain the backbone, we will not start from a randomly initialized model, but rather from a model that has already been pretrained in a supervised manner on COCO. What this allows us to do is to conduct a label-free domain adaptation of the backbone to the PIDray dataset and having a detection head that is already well trained on detecting objects – albeit objects that are very different from the dangerous items we want to detect in luggage. As will be shown in the results section, this is a very powerful and effective approach to quickly adapt a model to a new domain, especially when labeled data is scarce.
Pretraining a YOLO model with LightlyTrain can be done with just a few lines of code.
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="pidray_pretraining",
model="ultralytics/yolo11s.pt",
data="/datasets/PIDray/train",
epochs=3000,
batch_size=2048,
)
As is visible in the code snippet above, we largely use LightlyTrain's default hyperparameters, but we train for a total of 3000 epochs and use a batch size of 2048. The pretraining in above case takes around 200 GPU hours on our Nvidia B200 GPUs. Above code snippet also already supports distributed training and will conveniently export the pretrained model in the same format as the original YOLO11s model, such that loading the pretrained weights is as simple as using:
from ultralytics import YOLO
model = YOLO("pidray_pretraining/exported_models/exported_last.pt")
LightlyTrain also has advanced logging capabilities to MLOps platforms such as Weights & Biases, TensorBoard or MLFlow in order to track training progress and log metrics and model checkpoints.
Fine-Tuning
After pretraining, we get a YOLO backbone that is already well adapted to the PIDray dataset and has a very comprehensive understanding of the dataset. We can now use a very limited amount of labeled samples to fine-tune both our backbone and the detection head to the task at hand: Detecting dangerous items in luggage. In order to have baselines to compare against, we will also fine-tune a YOLO11s that was only trained in a supervised manner on COCO, as well as a randomly initialized YOLO11s model. Further, in order to observe the influence that the number of labeled samples has on the performance, we will fine-tune on different fractions of the labeled training set, specifically on 5%, 10% and 20%, corresponding to between around 4'000 and 15'000 labeled samples. The fine-tuning runs for a total of 200 epochs for all three models, and we use a batch size of 64 and train on images of size 640x640 pixels.
The standard metric for object detection performance is mean average precision at IoU thresholds between 0.5 and 0.95, (mAP50-95) a metric that captures both, 1. how well the overlap of predicted bounding boxes to ground truth boxes is, and 2. also how well the classes of the bounding boxes are predicted. In below plot we report the metrics for the different models and the different fractions of labeled data.
As you can see from the results, the model that was pretrained with LightlyTrain outperforms both, the COCO model and the randomly initialized model, by a significant margin across all fractions of labeled data. Also observable is the fact that the performance difference is stronger the less labeled data is used during the fine-tuning stage. This highlights the importance of domain-specific like LightlyTrain enables it, when labeled data is scarce, which is often the case in real-world applications.
Since this is a task with security implications, we are also particularly interested in how many dangerous items are not detected by the model. This metric is caught by the recall, which we also report below for the different fractions of labeled data.
As visible, the model pretrained with LightlyTrain also significantly outperforms the COCO model in terms of recall, providing much improved security for the airport security use case.
💡Pro tip: To enhance retrieval and detection pipelines, our Embeddings in Machine Learning article outlines how embeddings enable efficient similarity search.
Visualizing the Results
With the models trained, we can now visualize some predictions on the test set to get a sense of how well the models perform. To this end, we show predictions for 5 randomly selected images from the test set (limited to samples that actually contain objects), together with the ground truths.

As can be seen, both models make some mistakes and from this limited sample size it is not possible to draw any conclusions about which model performs better. This is why we rely on metrics such as mAP and recall from above to evaluate a model's performance.
Convergence Properties
Since model fine-tuning is a time-consuming process, we are also interested in how quickly a model converges or how many epochs it takes to reach a certain desired performance. To this end, we can visualize the convergence properties of the different models by plotting the mAP50-95 metric over the course of the fine-tuning process. Below we show the evolution of the mAP50-95 metric for the three models during fine-tuning on 5% of the labeled training set.
Beyond higher performance of the final model, the domain-specific pretraining with LightlyTrain also leads to much faster convergence during fine-tuning. Specifically, the model pretrained with LightlyTrain reaches the COCO model's final performance (200 epochs) after only around 70 epochs, which is a significant speed-up.
Conclusion
In this blog post, we have shown how LightlyTrain can be used to pretrain a YOLO11 model on a domain that is very different from natural images, such as the PIDray dataset of luggage X-ray images. We have demonstrated that this label-free pretraining significantly improves performance across several metrics, such as mAP and recall and that the performance gain is particularly pronounced when labeled data is scarce, which is often the case in real-world applications. We have also shown that the pretraining leads to much faster convergence during fine-tuning, which can save a lot of time and resources.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


