
The Ultimate Guide to Synthetic Data Generation
Table of contents
Share blog post



Synthetic data is artificially generated to mimic real datasets, easing privacy, access, and scarcity limits. Using GANs/VAEs or simulations, it scales, covers rare cases, and can be pre-labeled. It is best combined with real data to avoid bias and preserve realism.
Share blog post
Here is what you need to know about synthetic data generation:
What is synthetic data?
Synthetic data is artificially created information that doesn’t come directly from real-world events. Instead, algorithms and AI models generate it to reflect the same statistical properties as real data. In simple terms, it’s “artificial” data that looks and behaves like original data. This makes it valuable when real data is limited, sensitive, or hard to access.
How is synthetic data generated?
There are several ways to generate synthetic data. Popular methods include generative models such as GANs (Generative Adversarial Networks) or VAEs (Variational Autoencoders), which can create realistic data points. For instance, GANs can generate synthetic images that are nearly indistinguishable from real ones.
Simulations and agent-based models can also produce information by recreating real-world scenarios in a virtual environment..
Why use synthetic data?
Synthetic data helps data scientists and engineers overcome data bottlenecks. It can expand or replace training data for machine learning models, especially when access to sensitive real data is restricted. Some clear benefits of synthetic data include:
- Privacy protection: No real personal details are exposed.
- Unlimited scale: You can create as many synthetic records as needed.
- Coverage of rare cases: Simulate edge cases like anomalies or fraud that are underrepresented in real data.
- Pre-labeled datasets: Many synthetic datasets come ready to use, saving manual annotation time.
Is synthetic data as good as real data?
When generated well, synthetic data can closely match the statistical patterns of real data. It’s often used together with real datasets to strike a balance between privacy and accuracy.
Still, it’s not perfect. If the synthetic data doesn’t reflect real-world patterns accurately or carries over bias from the source data, machine learning models can suffer. That’s why synthetic data is usually best used to support real data, not replace it entirely.
Access to high-quality real data is often limited by privacy concerns, regulatory requirements, and the high cost of collecting data.
Synthetic data is becoming a valuable solution. It helps train machine learning models, test systems under different scenarios, and support research that can be repeated and verified.
In this article, we will explore various aspects of synthetic data, including:
- What is synthetic data?
- Types of synthetic data
- How to generate synthetic data (techniques and tools)
- Synthetic data vs. real data
- Applications and use cases of synthetic data
Scaling synthetic data isn’t as simple as running a generative model. Producing high-quality datasets requires domain expertise, reliable pipelines, and strong privacy controls.
Lightly enables teams to generate high-quality synthetic data that is balanced, realistic, and nuanced enough to capture the subtle patterns in complex datasets.
It gives ample control to generate datasets tailored to your specific use case and lets you combine them with actual samples to augment your original data.
Additionally, it lets you work with automated prompt and instruction generation pipelines to speed up systems consisting of LLM and agentic workflows.

See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What is Synthetic Data?
Synthetic data is artificially created information that resembles the statistical characteristics of actual datasets without revealing sensitive information.
Since synthetic data is mathematically the same as the original data, data scientists can safely use it to train, test, and verify machine learning models.
This facilitates experimentation and scalability without the privacy, compliance, and security concerns associated with real-world data.

Why do we Need Synthetic Data?
Synthetic data reproduces the statistical structure and mathematical properties of real datasets without exposing sensitive attributes. It supports model training, validation, and benchmarking when access to real data is limited, incomplete, or restricted.
Data Privacy Preservation
Generated datasets replace sensitive real data with artificial records. These artificial records preserve key patterns and relationships, which allow for safe model training without exposing individuals.
Techniques like differential privacy add noise to prevent tracing outputs back to real data.
K-anonymity protects privacy by ensuring each record is indistinguishable from at least K–1 others based on key attributes.
It does this by grouping or generalizing values (e.g., ages 30–39), making individual re-identification much harder.
Scalability and Cost Efficiency
Synthetic data generation frameworks reduce the cost and time needed to produce large, consistent training datasets. In object detection, using a mix of synthetic and real data can cut the need for real-world data by up to 70% while maintaining performance.
Systems like SDV and CTGAN scale tabular data by learning feature relationships and enforcing relational integrity. SDV uses probabilistic methods to create realistic, privacy-safe synthetic data that mirrors real database structures.
CTGAN captures nonlinear feature patterns and handles both categorical and numerical data, producing high-quality synthetic tables.
💡Pro Tip: Synthetic datasets become especially valuable at scale; the Large Vision Models article highlights how large-capacity vision backbones benefit from diverse, automatically generated training signals.
Customization and Control
Data generation methods allow adjustment of distribution parameters, feature relationships, and sampling schemes.
For example, engineers can increase the proportion of high-risk transactions in a particular time window to augment a dataset for training a fraud detection model.
Diverse and Balanced Datasets
Synthetic data improves class imbalance by generating minority-class samples through methods like SMOTE, ADASYN, or GAN-based synthesis.
SMOTE, for instance, generates new minority samples by interpolating between existing ones, preserving feature structure and improving class balance.
This balanced sampling enhances model generalization, reduces bias, and stabilizes performance across all target classes.
💡Pro Tip: If you generate synthetic images and want to pair them with a robust pretrained encoder, our DINOv2 Reproduction article explains how a state-of-the-art SSL backbone is reproduced and validated for real-world use.
Fast Experimentation and Model Development
On-demand generation of synthetic datasets enables rapid testing, validation, and iteration of models. Integration with MLOps processes allows automated training and testing workflows, data drift analysis, and efficient model performance assessment over time.
Types of Synthetic Data
Synthetic data exists in several forms, depending on the type of real-world information that it imitates. These forms can be classified by data modality (format) or by their relationship to the original dataset.
By Data Format (Modality)
Synthetic Tabular Data
Tabular synthetic data is structured into rows and columns similar to relational databases or spreadsheets. It reflects organized information like patient records, transaction history, or sensor data.
A single model, such as a Gaussian Copula, can efficiently generate this kind of data by learning the joint probability distribution of all variables.
It models correlations among features through a multivariate Gaussian transformation and then samples new data points that maintain those dependencies.
Synthetic Image and Video Data
Synthetic visual data in computer vision is artificially created images that mimic real-world scenes and textures with very high visual fidelity.
These images are generated using deep generative models like StyleGAN, Diffusion Models, and Neural Radiance Fields (NeRFs). The models learn detailed spatial, lighting, and texture features important to visual perception.

Synthetic Text Data
Synthetic text data is AI-generated language that replicates human writing with high grammatical and semantic accuracy.
It’s created using transformer-based models like GPT, T5, and LLaMA. Transformers rely on a mechanism called self-attention, which allows the model to weigh the importance of each word in a sentence relative to all others.
Synthetic Audio and Speech Data
Synthetic audio and speech replicate real acoustic spaces and speech in AI and signal processing.. These datasets record tone, pitch, and time dynamics, which are significant in natural-sounding output.
Models such as Tacotron, WaveNet, VITS, and DiffWave can convert text or latent features into high-fidelity audio, generating realistic voices and ambient audio.
For example, the ODSS dataset includes fake speech audio generated for 156 voices in three languages (English, German, and Spanish).
The dataset uses two main text-to-speech methods. The first, FastPitch + HiFi-GAN, predicts the rhythm and tone of speech before converting it into actual audio.
The second, VITS, generates natural-sounding speech directly in one step, creating realistic voices without separate processing stages.

Synthetic Unstructured Data
Synthetic unstructured data is algorithmically generated free-form information, including logs, chat transcripts, or documents. This data is created to simulate the context, sequence, and semantics of real data.
It’s created using probabilistic and simulation-based models that mimic real patterns and event flows over time. This lets teams safely test and train AI systems without exposing sensitive data.
A notable example is the SAGA project that generates synthetic audit logs with normal and malicious activity mixing according to the MITRE ATT&CK framework.
These logs allow security teams to train and test intrusion detection systems (IDS) safely, especially where real attack data is sensitive or classified.
By Dataset Composition
Synthetic data can also be categorized by its relationship to real-world data, with the main types outlined in the table below.
How to Generate Synthetic Data (Techniques and Tools)
Now that we’ve explored different types of synthetic data, let’s look at how it’s created in practice using various techniques, tools, and code implementations.
Statistical Simulation
Statistical simulation generates synthetic data by modeling the underlying probability distributions and correlations of real datasets. It works best for structured or tabular data, where relationships can be mathematically described.
This code fits a Gaussian Copula model that learns the marginal distributions and pairwise correlations from the real dataset. It then generates 1,000 synthetic records that closely match the original data’s statistical patterns and relationships.
Code Example
This code demonstrates how to generate synthetic tabular data that mimics real-world patterns using the Gaussian Copula model.
It starts with the Iris dataset, a classic dataset containing flower measurements such as sepal and petal length and width.
The model learns statistical relationships between these features and creates new synthetic samples that preserve similar correlations and distributions.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from copulas.multivariate import GaussianMultivariate
iris = load_iris(as_frame=True)
real_df = iris.data
print("Real data sample:")
print(real_df.head())
model = GaussianMultivariate()
model.fit(real_df) # Learn feature relationships
synthetic_df = model.sample(150) # Generate new synthetic samples
sns.pairplot(real_df, diag_kind="kde")
plt.suptitle("Real Data Distribution (Iris)", y=1.02)
plt.show()
sns.pairplot(synthetic_df, diag_kind="kde")
plt.suptitle("Synthetic Data Distribution (Gaussian Copula)", y=1.02)
plt.show()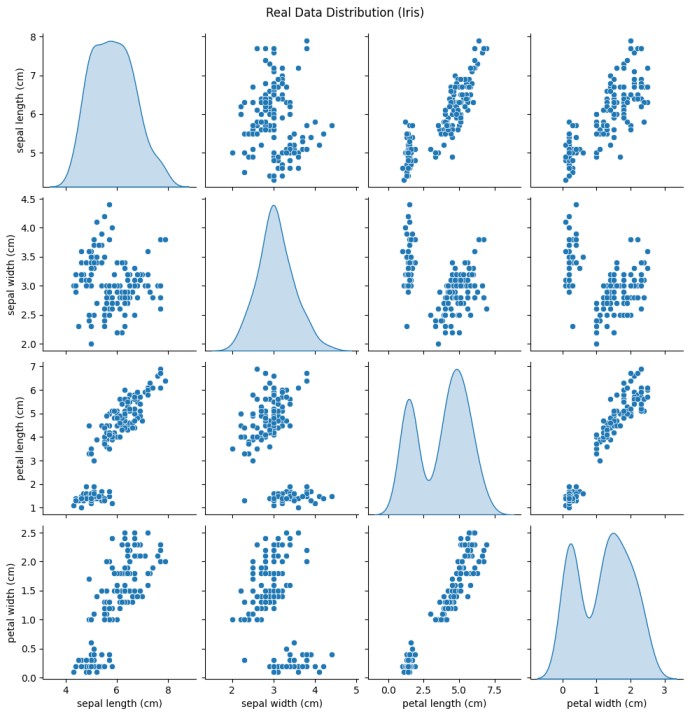
The image shows a pairplot of synthetic Iris data generated using a Gaussian Copula model.
Each diagonal plot displays the distribution of a single feature, while the scatter plots show how pairs of features relate to each other.
The synthetic data preserves the same general patterns as the real dataset, for example, petal length and petal width still show a strong positive correlation.
Generative Adversarial Networks (GANs)
GANs generate synthetic data by training two neural networks in an adversarial way. A generator creates new samples based on random noise, while a discriminator learns to differentiate between the real and generated data.

The generator adjusts its outputs during many iterations until the outputs are similar to the true data distribution. GANs are efficient, especially on high-dimensional, nonlinear data such as images, time series, and non-trivial tabular data.
Code Example
This code demonstrates the core idea of GANs, generating realistic images from random noise. We use BigGAN, which is a large-scale GAN developed by DeepMind for high-quality image synthesis.
BigGAN is a conditional GAN trained on the ImageNet dataset. It can generate highly realistic, detailed synthetic images from given class labels and random noise.
Random latent vectors are combined with class labels such as goldfish, castle, volcano, and coffee. The model then produces lifelike synthetic images corresponding to those classes.
NLTK (Natural Language Toolkit) is used here to access WordNet. This helps map simple class names (like “goldfish” or “castle”) to their corresponding ImageNet labels for image generation.
import torch, numpy as np
from PIL import Image
from IPython.display import Image as IPImage, display
from pytorch_pretrained_biggan import BigGAN, one_hot_from_names, truncated_noise_sample
import nltk
nltk.download('wordnet')
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BigGAN.from_pretrained('biggan-deep-256').to(device).eval()
# Pick a few ImageNet classes
classes = ['goldfish', 'castle', 'volcano', 'coffee']
z = torch.from_numpy(truncated_noise_sample(truncation=0.4, batch_size=len(classes))).to(device).float()
y = torch.from_numpy(one_hot_from_names(classes, batch_size=len(classes))).to(device)
with torch.no_grad():
out = model(z, y, truncation=0.4).clamp(-1,1)
img = ((out + 1)/2 * 255).byte().cpu().numpy()
# Make 2×2 grid
H,W = img.shape[-2:]
grid = np.zeros((3, 2*H, 2*W), dtype=np.uint8)
k=0
for r in range(2):
for c in range(2):
grid[:, r*H:(r+1)*H, c*W:(c+1)*W] = img[k]; k+=1
Image.fromarray(np.transpose(grid,(1,2,0))).save("biggan_grid.png")
display(IPImage(filename="biggan_grid.png"))
From top left to bottom right, it depicts a goldfish, a castle, a volcano, and a cup of coffee, all created entirely from random noise and class labels.
This output demonstrates how BigGAN can generate realistic-looking synthetic images that visually represent chosen categories without using any real photos.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) learn a compact latent representation of data that can be used to reconstruct and generate new samples. An encoder maps input data to a latent distribution, while a decoder rebuilds it from sampled latent vectors.
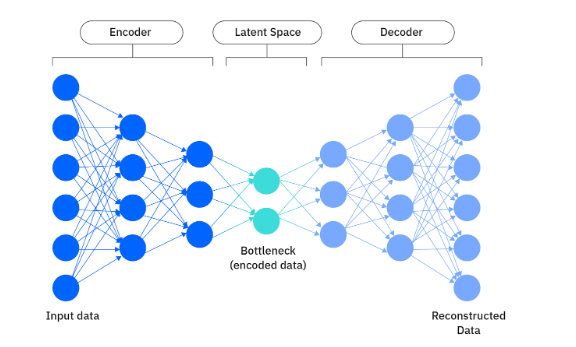
In computer vision, they’re used for data augmentation, anomaly detection, and privacy-preserving image synthesis.
Generating Data for Computer Vision using a Variational Autoencoder (VAE)
This tutorial walks through the working concept of a Variational Autoencoder (VAE) for generating synthetic image data. It uses a Convolutional VAE (ConvVAE) trained on the MNIST dataset to produce new handwritten digits.
The model has an encoder that compresses input images into a latent space and a decoder that reconstructs or generates images from this space.
Sampling random points within this latent space allows the VAE to create new, synthetic digits that look realistic but are not copies of real data.
import torch, torch.nn as nn, torch.nn.functional as F
from torchvision import datasets, transforms, utils as vutils
import matplotlib.pyplot as plt
from pathlib import Path
device = "cuda" if torch.cuda.is_available() else "cpu"
LATENT = 16
# ConvVAE #
class MNISTVAE(nn.Module):
def __init__(self, latent=16):
super().__init__()
self.enc = nn.Sequential(
nn.Conv2d(1, 32, 4, 2, 1), nn.ReLU(True), # 14x14
nn.Conv2d(32, 64, 4, 2, 1), nn.ReLU(True), # 7x7
nn.Flatten()
)
self.enc_out = 64*7*7
self.fc_mu, self.fc_lv = nn.Linear(self.enc_out, latent), nn.Linear(self.enc_out, latent)
self.fc = nn.Linear(latent, 64*7*7)
self.dec = nn.Sequential(
nn.ConvTranspose2d(64, 32, 4, 2, 1), nn.ReLU(True), # 14x14
nn.ConvTranspose2d(32, 1, 4, 2, 1) # 28x28 (logits)
)
def encode(self, x):
h = self.enc(x); return self.fc_mu(h), self.fc_lv(h)
def reparameterize(self, mu, lv):
std = torch.exp(0.5*lv); return mu + torch.randn_like(std)*std
def decode(self, z):
h = self.fc(z).view(-1,64,7,7); return self.dec(h) # logits
def forward(self, x):
mu, lv = self.encode(x); z = self.reparameterize(mu, lv); return self.decode(z), mu, lv
model = MNISTVAE(LATENT).to(device)
ckpt_path = Path("mnist_vae_state_dict.pth")
if ckpt_path.exists():
model.load_state_dict(torch.load(ckpt_path, map_location=device))
print("Loaded pretrained weights.")
else:
ds = datasets.MNIST("./data", train=True, download=True, transform=transforms.ToTensor())
dl = torch.utils.data.DataLoader(ds, batch_size=256, shuffle=True, num_workers=2)
opt = torch.optim.Adam(model.parameters(), lr=2e-3)
model.train()
for x,_ in dl:
x = x.to(device)
logits, mu, lv = model(x)
bce = F.binary_cross_entropy_with_logits(logits, x, reduction="sum")
kld = -0.5 * torch.sum(1 + lv - mu.pow(2) - lv.exp())
loss = (bce + kld) / x.size(0)
opt.zero_grad(); loss.backward(); opt.step()
model.eval()
model.eval()
with torch.no_grad():
z = torch.randn(64, LATENT, device=device)
imgs = torch.sigmoid(model.decode(z)) # [0,1]
grid = vutils.make_grid(imgs.cpu(), nrow=8, padding=2)
plt.figure(figsize=(6,6)); plt.axis("off"); plt.title("Synthetic MNIST samples (VAE)")
plt.imshow(grid.permute(1,2,0)); plt.show()
The generated digits resemble real MNIST numbers but appear blurry or distorted, which is common for simple VAEs trained for a short time. The output can be improved by training for more epochs, using a larger latent dimension, or applying deeper convolutional layers.
In computer vision, such VAEs are useful for data augmentation, representation learning, and understanding latent feature spaces in generative modeling.
Transformer-based Models (LLMs)
Transformers like the GPT family use self-attention mechanisms to understand relationships between words across long sequences. This allows them to generate text that is highly coherent, context-aware, and semantically consistent.
Initially used as language models, they are currently being used to generate synthetic data in text, images, tabular data, and multimodal content. Their scalability, flexibility, and ability to model intricate structures make them the most current option for synthetic data generation.
Example
Here’s a simple Python example using Hugging Face Transformers to generate synthetic text data.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load a compact GPT-like model
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prompt for synthetic data generation
prompt = "Synthetic customer feedback for a new AI product:\n1."
inputs = tokenizer(prompt, return_tensors="pt")
# Generate synthetic text
output = model.generate(
**inputs,
max_new_tokens=80,
temperature=0.9,
top_p=0.95,
do_sample=True
)
print(tokenizer.decode(output[0], skip_special_tokens=True))
The code loads a pre-trained Transformer (GPT-2) model and generates synthetic text from a given prompt. This shows how large language models can generate realistic, context-aware data samples.
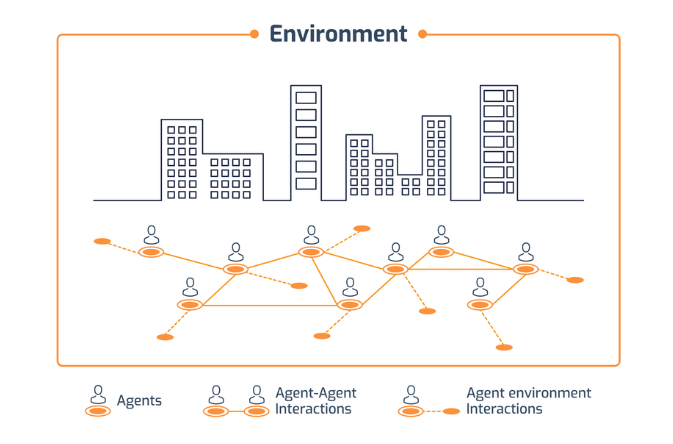
Agent-Based Modeling and Simulation
Agent-Based Modeling (ABM) is a bottom-up simulation approach where you define agents (entities) with their own behaviors and rules, place them in an environment, and let them interact.
The model doesn’t start with a dataset to learn from. Instead, it generates data by simulating the system's dynamics over time.
This is different from machine learning, which typically fits existing data. ABM creates its own data through the simulation of a domain-specific system and interactions.
A study High-Resolution Agent-Based Modeling of COVID-19 Spreading in a Small Town, develops a detailed simulation to model how the virus spreads and how interventions affect outcomes.
The study models individual-level interactions, such as people, households, and workplaces, to simulate COVID-19 spread. It shows how interventions like testing, isolation, and vaccination alter transmission over time, showing ABM’s power to explore complex what-if scenarios.
Other Techniques & Tools
Beyond the methods above, hybrid approaches are widely used. Frameworks like the Synthetic Data Vault (SDV) generate structured datasets across relational tables and time series.
Decision-tree–based methods model splits and decision boundaries, generating records consistent with those patterns. These methods increase flexibility, which makes it easier to tailor synthetic data to complex scenarios.
Ensuring Synthetic Data Quality (Fidelity, Utility & Privacy)
The reliability of synthetic data relies on how effectively it maintains the real-world structure, performs in the intended use cases, and ensures privacy protection. Finding the right balance between fidelity, utility, and privacy determines whether synthetic data can be considered production-grade.
- Statistical Fidelity: Synthetic data should preserve relationships between features found in real data to remain realistic. For example, if age tends to increase with income in the original dataset, the synthetic version should show a similar pattern. This relationship is commonly evaluated using Pearson correlation, which measures how strongly two variables move together.
- Use-Case Utility: Synthetic data should enable reliable insights and model testing in real-world settings. For instance, in medical diagnosis, a model trained on synthetic patient records should still identify diseases accurately when evaluated on real cases.
- Privacy & De-identification: Artificial data should protect real identities so that no original person or object can be traced. This can be achieved through latent-space generation, where images are generated from learned patterns rather than actual photos. For example, synthetic faces can be generated to train vision models without exposing any real individuals.
- Bias Control: Synthetic image generators can amplify bias if trained on unbalanced datasets. For instance, balancing the number of images across different skin tones or lighting conditions is crucial. This helps prevent biased model behavior in face recognition or object detection tasks.
- Validation & Reality Checks: Maintaining realism is vital to ensure synthetic visuals align with real-world expectations.. In computer vision, generated images must look natural, with correct proportions, lighting, and textures. Any distortions or duplicates signal the need to retrain or refine the generator.
- Quality Measurement: The quality of synthetic data is measured by integrating fidelity, utility, and privacy into comprehensive indices like the SDMetrics Quality Report. This ensures the dataset meets both analytical accuracy and compliance standards.
Synthetic Data vs. Real Data (and Other Data Alternatives)
It’s equally important to compare synthetic data with real data and other alternatives to understand where each delivers the most value. The following comparison table outlines the differences:
Applications and Use Cases of Synthetic Data
Synthetic data is increasingly applied across industries. It powers use cases ranging from machine learning training to privacy-preserving analytics. Let’s look at a few of them:
Model Training
Synthetic datasets scale machine learning training when real labeled data is limited, expensive, or biased. They preserve statistical properties of the original dataset while enabling faster model development.
💡Pro Tip: Synthetic data works best when combined with pretrained models. See this blog on how Transfer Learning improves downstream performance.
Testing and Validation
Synthetic data lets teams safely test software, APIs, and data flows. It’s useful for simulating edge cases, validating logic, and checking how systems behave in different scenarios, without needing real customer data.
Data Sharing
Organizations use AI-generated synthetic data to share insights with partners or researchers while maintaining data privacy.
Handling Rare Events
Synthetic samples balance datasets with scarce events such as fraudulent transactions, improving model accuracy through hybrid synthetic data.
Privacy-Conscious Analytics
Sectors like healthcare, banking, and insurance use partially synthetic data for analysis and predictive modeling while complying with regulations.
Research and Competitions
Synthetic data vaults allow safe dataset releases for Kaggle challenges and public research while preserving the mathematical properties of real data.
Scenario Planning
Businesses simulate entirely new data for what-if situations, testing strategies, risks, and real-world scenarios not captured in historical data.
Industry Examples
Synthetic data has moved beyond research into widespread industry adoption. The following examples show how organizations use it to enhance model accuracy, protect privacy, and scale data-driven innovation.
Automotive Industry
Capturing real vehicle sensor recordings (camera, LiDAR) risks exposing identifiable surroundings. A generative pipeline synthesizes realistic driving sensor data free of direct source traces.
One such method is SurfelGAN, which reconstructs a scene from sparse LiDAR and camera scans (using textured surfels). It then applies a GAN to render realistic novel camera views from different trajectories.

The method preserves scene geometry, lighting, and object layout. This allows perception models trained on synthetic data to approach real-world performance while ensuring privacy and flexibility in scenario replay.
Health Records
Sharing real medical records carries serious privacy risks. A privacy-preserving generative model creates realistic synthetic health records that mimic real patient data while preserving privacy.
It uses a conditional GAN with differential privacy. This adds controlled noise during training to protect identities while preserving data patterns.
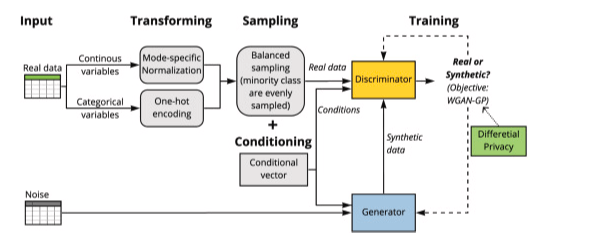
The approach accurately captures both common and rare medical cases. It maintains strong similarity to real datasets and high model performance, all while preventing re-identification.
Synthetic Data in Agriculture
Collecting real crop or field imagery often reveals sensitive farm details (e.g., field layouts, private land boundaries).
In one study, plant patches were clipped from UAV images or real scenes, augmented (rotated and color-jittered), and fed into GANs to create full synthetic field scenes.
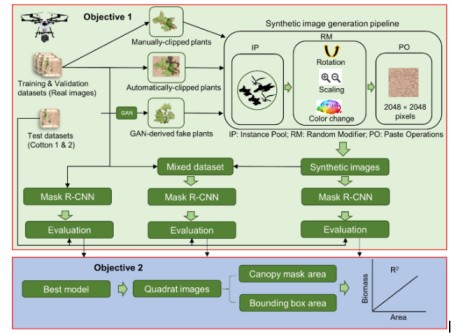
This synthetic dataset preserves plant morphology, spacing, and background variation.
Models (e.g. Mask R-CNN) trained on these synthetic images perform comparably on real-data tasks. Detection mAPs are 0.60 vs. 0.80 for real images, narrowing the gap while vastly reducing annotation cost.
Challenges and Limitations of Synthetic Data
Synthetic data brings major opportunities but also introduces complex risks that can affect quality, fairness, and trust. Let’s look at the key challenges and limitations organizations face when working with synthetic data.
Ensuring Realism and Avoiding Artifacts
Synthetic data often looks real at first glance, but can miss subtle variations and edge cases seen in actual data. These gaps produce visible or statistical artifacts that reduce realism. As a result, downstream models may struggle to generalize to real conditions.
Bias Replication and Amplification
Artificial data frequently mirrors the imbalances present in its source dataset. If the training data is biased, those same distortions reappear or intensify in generated samples. This can harm fairness and distort model performance across groups.
Model Collapse & Feedback Loops
Regular training on synthetic data may lead to model collapse, in which the generator reinforces its own patterns and produces homogeneous, low-quality samples. Such a feedback loop decreases diversity, increases bias, and weakens performance in the real-world situation.
Privacy Guarantees Are Not Absolute
Models can unintentionally memorize fragments of real data, leaking sensitive information. Even when anonymized, generated outputs may still be traceable back to individuals. This makes privacy protection incomplete without further safeguards.
Acceptance and Validation
Synthetic data often faces skepticism around its accuracy and utility. Users and regulators need proof that it behaves like real data in practice. Without validation, adoption and trust remain limited.
Complexity and Expertise
Generating reliable synthetic data demands strong expertise in generative modeling, privacy, and domain context. Misconfigurations or poor tuning easily degrade data quality. Building these skills and infrastructure adds significant operational effort.
Regulatory Uncertainty
There is legal ambiguity regarding ownership, consent, and the anonymization of synthetic data. In some cases, such as under the GDPR and the EU AI Act, synthetic data can still qualify as personal data if it can be re-identified.
Compliance criteria require the use of privacy risk assessment and transparent lineage recordings.
Best Practices to Address These Challenges
Overcoming the challenges mentioned above requires best practices that balance utility, fidelity, and privacy. Here are a few best practices that help achieve this:
- Blend Data Sources: Use a mix of real data and hybrid synthetic data to keep synthetic datasets grounded.
- Evaluate Rigorously: Compare synthetic vs. real on key metrics (utility, diversity, and privacy). Apply frameworks like TSTR (Train on Synthetic, Test on Real).
- Add Privacy Layers: Apply methods like differential privacy or k-anonymity before releasing sensitive data fields.
- Refresh Regularly: Update synthetic generation with new historical data to prevent drift and model collapse.
- Start Small: Run pilot projects to show value in specific use cases. Examples include testing software or generating test data for fraud detection.
- Document Thoroughly: Record how synthetic data was created, including techniques, input data, and evaluation results, for auditability and compliance.
Future Trends and Research in Synthetic Data
As adoption grows across industries, the next step is to examine where synthetic data is headed and the research that will shape its future.
Larger and Smarter Generative Models
Diffusion models and large-scale foundation models are raising the quality of synthetic data across images, text, and tabular formats.
Researchers now propose Large Tabular Models (LTMs) to generate scalable synthetic datasets and reusable embeddings for downstream tasks.
Active learning & adaptive generation
The focus is shifting from blind data generation to adaptive pipelines that target gaps in model performance. Models can now propose the most useful synthetic data samples for training, based on current errors or underrepresented cases.
Synthetic-data marketplaces
Curated synthetic datasets covering customer data, finance logs, and domain-specific packs are emerging as key resources for testing software and predictive modeling. The market is projected to grow from USD 0.3 billion in 2023 to USD 2.1 billion by 2028.

Analysts expect synthetic content to make up a significant share of AI training data this decade.
Better evaluation metrics and standards
Evaluation is maturing from ad-hoc checks to multi-metric dashboards. Common practices include TSTR alongside TRTR (Train on Real, Test on Real), plus privacy tests (e.g., membership-inference risk).
Standards bodies such as ISO/IEC SC 42 and the Data & Trusted AI Alliance are developing metadata and provenance frameworks for synthetic data. These efforts aim to improve transparency, traceability, and accountability in synthetic data workflows.
Integration with privacy tech
Synthetic data is being combined with federated learning and differential privacy to enable secure collaboration while preserving model performance.
Recent studies show that differentially private synthetic data can stabilize federated training across diverse clients.
Domain-specific generators
Specialized tools are emerging for genomics, medical imaging, NLP, and voice, tailored to domain constraints.
Diffusion models can preserve fine clinical features in healthcare. This can affect downstream model development and diagnostic accuracy.
Human-in-the-loop workflows
Human feedback is increasingly used to rank synthetic records, correct schema issues, and enforce business rules. New frameworks emphasize post-generation checks and expert review to keep the same mathematical properties while fixing semantic errors.
Lightly already supports integration into labeling and active learning pipelines. It acts as a bridge between embedding-based selection and human annotation loops.
Use in AI Safety and Robustness
Synthetic adversarial examples are now a common way to probe model vulnerabilities under unusual but plausible conditions. These stress tests help evaluate robustness, expose failure modes, and strengthen defences against distribution shifts and adversarial attacks.
Conclusion
Synthetic data is reshaping AI by offering scalable, privacy-safe alternatives to real-world datasets. It enables model training, rare event coverage, and rapid experimentation without the risks tied to sensitive data.
Ensuring fidelity, utility, and fairness remains essential to its success. As adoption accelerates, synthetic data will become a standard tool in modern AI development.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


