
The Complete Guide to Object Detection for ML Engineers
Table of contents
Share blog post



Object detection locates and classifies multiple objects in images or video by drawing bounding boxes around them. This guide explains how it works, compares detectors, and reviews popular models like R-CNN, YOLO, SSD, and EfficientDet.
Share blog post
Below, you can find a quick summary of key points about Object Detection:
- What is object detection?
Object detection is a computer vision task where a model identifies and locates multiple objects in an image or video. It not only classifies the objects present but also draws bounding boxes around each one. In essence, it answers “what objects are in the image and where are they?”.
- How does object detection work?
Modern object detection models use deep learning (usually convolutional neural networks) to extract features from an input image, then predict bounding boxes and class labels for objects. They perform both object classification (what the object is) and localization (where it is) simultaneously. The process often includes generating candidate regions, refining box coordinates via bounding-box regression, and applying non-max suppression to remove overlapping duplicate detections.
- Object detection vs. image classification vs. segmentation?
Image classification assigns a label to the entire image (e.g. “contains a dog”) but doesn’t locate it. Object detection both classifies and localizes each object with a bounding box. Instance or mask segmentation goes further by delineating the exact shape of objects at the pixel level instead of just a box.
- What are one-stage and two-stage detectors?
Two-stage detectors (e.g., Faster R-CNN) first generate region proposals and then classify them, achieving high accuracy but at slower speeds. One-stage detectors (e.g., YOLO, SSD) forgo an explicit proposal step and directly predict boxes and classes in one pass, trading a bit of accuracy for much faster inference. One-stage models are popular for real-time applications but can struggle with very small or dense objects.
- Which object detection models are popular?
R-CNN and its successors Fast R-CNN and Faster R-CNN (two-stage models with region proposal networks) set early benchmarks for accuracy. YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector) are one-stage models known for real-time performance. Modern variants like YOLOv7/v8, RetinaNet (with focal loss), Mask R-CNN (for instance segmentation), and EfficientDet (with multi-scale feature pyramid network) achieve top detection performance on benchmarks. Each has different trade-offs in speed, accuracy, and use-case suitability.
Introduction
Knowing where things are in an image or video can be helpful in many practical applications.
For example, if you're creating a wildlife monitoring system and want it to track objects like individual animals and observe their behavior, all of this is possible through object detection. It's a computer’s ability to identify and locate things within an image or a video frame.
In this guide, we’ll cover:
- Understanding object detection (classification & localization)
- Evolution of object detection algorithms
- Popular object detection model architectures
- Performance metrics
- Practical tips for training and deployment
Object detection tasks demand quality, diverse training data, and a smart approach to using it. We at Lightly provide tools to help you train better detection models through:
- LightlyOne: Curate the most representative and diverse samples for training to improve accuracy and generalization.
- LightlyTrain: Enables self-supervised pretraining on domain unlabeled data, so your object detection model adapts better when fine-tuned with less labeled data.
Try Lightly for free today!
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Understanding Object Detection (Classification and Localization)
Object detection is a core computer vision task that identifies not only which objects appear in an image or video, but also where they are located. In practice, it answers two key questions: what objects are present and where each one is positioned.
Object detection does two key tasks at once:
- Object Classification: It determines the kind of object. The model looks at a part of the image and labels it as "person," "car," or "animal."
- Object Localization: Localization determines the location of the object by drawing a tight rectangle (bounding box) around it. The box is described by its coordinates (x and y position of the top-left corner) and its size (width and height).

For example, in the image below, the object detection model first identifies and labels objects like "person," "bicycle," "truck," and "Road sign." Then, it draws boxes around each object to show exactly where they are.

Object detection is often confused with other computer vision tasks. So, before we move on, let’s clarify the difference.
Unlike image classification, which looks at an entire image and assigns a single label to categorize it, object detection takes it a step further. It creates a bounding box around the classified object and differentiates between multiple entities in the same scene.
It is also different from semantic image segmentation, which classifies every single pixel in an image. Instead, object detection simply marks the location of each object with a box.
💡Pro tip: Read about Instance Segmentation and Semantic Segmentation.
When we combine semantic segmentation with object detection, we get instance segmentation, which first detects object instances, then segments (a pixel-wise outline) each within the boxes.

How Object Detection Works (Pipeline)
Modern object detection uses deep learning networks to automate the process of finding and classifying objects. Although various models have specific details, they usually have the same pipeline.
Here's how object detection generally works from start to finish.
Input Image and Preprocessing
The process starts with an input image. Before the neural networks use the image, it goes through some preparation steps. These steps make sure the image is in the right format for the model architecture.
Preprocessing involves resizing the image to a fixed dimension, like 640 by 640 pixels, and adjusting the pixel values to a standard range.
Normalization helps the training process be more stable and efficient.
Feature Extraction (Backbone CNN)
After the image is preprocessed, it enters the "backbone" of the object detector.
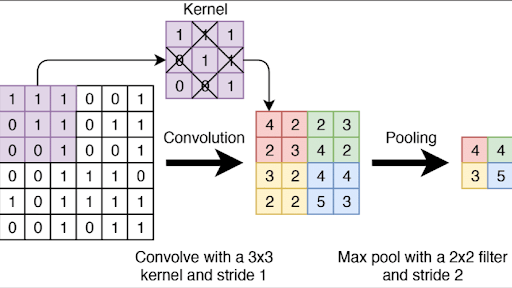
The backbone is a deep convolutional neural network (CNN), such as VGG or EfficientNet, which finds and extracts features from the image. It does this using kernels, which are small filters (such as with a 5x5 size) that slide across the image to detect patterns.
Backbone processes the image through many layers. The initial layers find simple features like edges, corners, and colors.
As the image moves through more layers, the CNN combines these simple features to find more complex patterns like textures, shapes, and parts of objects, such as noise, an eye, and more.

To make this hierarchical process faster, pooling layers such as max pooling are often used. Max pooling keeps the single highest value from the window to shrink the data and retain only the important information.
The output of the backbone is a set of feature maps, which are numerical summaries of the image's content at various levels.
Predicting Object Location and Class
When we have extracted features, the next step is to predict the location and identity of objects, and it depends on the model family we are using, whether it is:
- Two-Stage Approach: These models generate a set of candidate object regions first. A mini-network, like a Region Proposal Network (RPN), scans the feature maps and proposes a few hundred "regions of interest" that are likely to contain an object (process known as region proposal generation).

- One-Stage Approach: These models perform dense object detection. They treat the entire feature map as a grid and directly predict bounding boxes and class probabilities for many predefined locations across the image in a single pass.

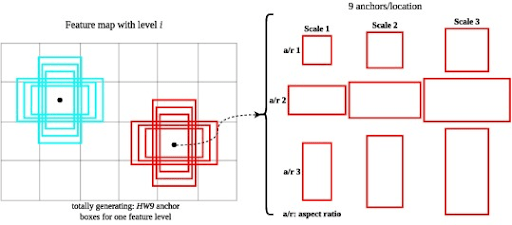
Besides this difference, almost all models, including two-stage and single-stage, use anchor boxes as reference bounding boxes at each feature map location.
Anchors are predefined boxes of various sizes and different aspect ratios (tall, wide, square) tiled across the image.
Instead of predicting a bounding box from scratch, the model predicts offsets from these anchor boxes. It learns to take a default anchor box and adjust its position and size to fit tightly around a real object.
For each proposed region or anchor, the model’s head then performs object classification and bounding box regression.
- Classification: It calculates class probabilities, indicating the likelihood the box contains each object class, like 85% person, 10% car, 5% background.
- Bounding Box Regression: It predicts four adjustment (offsets) values to refine the anchor box into an accurate bounding box that fits tightly around the detected object.
💡Pro Tip: If you're choosing a detection workflow, our Lightly vs. Ultralytics comparison shows how the two approaches differ in practice.
Finalizing the Detections
After prediction, the model has a huge list of potential detections, many of which are duplicates pointing to the same object. To clean this up, we can use filtering and non-maximum suppression (NMS).
NMS discards all boxes with a low confidence score. Then, for the remaining boxes, it finds the one with the highest score and removes any other nearby boxes that have a high overlap (Intersection over Union) with it.
The model repeats the process until only the best, non-overlapping boxes are left.
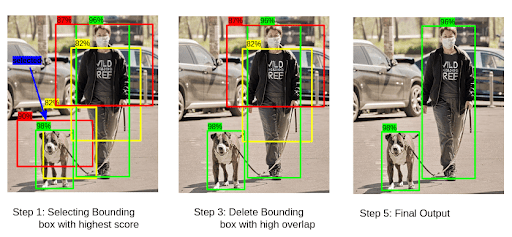
Finally, the output is the original image annotated with the refined bounding boxes, class labels, and confidence scores for each detected object.

Traditional Object Detection Methods vs. Deep Learning
Before deep learning was popular, people used traditional computer vision techniques to detect objects.
Traditional methods involved hand-crafted features. Experts designed algorithms like SIFT (Scale-Invariant Feature Transform) or HOG (Histogram of Oriented Gradients) to turn images into data that computers can understand (pixels into a feature).
Then, a machine learning model, like a Support Vector Machine (SVM), was trained on these features to determine if an object was present in the image.

Deep learning techniques take a step further by letting computers learn features automatically.
A CNN can find the best features for a task directly from training data. This means there’s no need for people to manually create the features.
Because of this, the models become more accurate, stronger, and better at recognizing new, unseen images.

Here is a comparison of the two approaches:
One-Stage vs. Two-Stage Object Detectors
Deep learning models for object detection are mainly classified into two types: single-stage and two-stage detectors.
Two-stage detectors first use a region proposal network (RPN) to scan the image and generate a sparse set of candidate regions (proposals) where objects are likely to exist.
Then it takes each of these proposals, crops them from the image, and feeds them into a separate network for final classification and bounding box refinement.
Moreover, the sequential process prioritizes accuracy as the model focuses on a few high-probability option regions, but it is computationally intensive and slow. Popular two-stage detectors include R-CNN, Faster R-CNN, Mask R-CNN, and the latest model, G-RCNN.
On the other hand, single-stage detectors treat the entire detection problem as a single task. These models skip the region proposal step and predict classification scores and bounding box coordinates in parallel for every object in the image.
It is simpler and much faster, but it isn't as accurate as its two-stage counterparts. The most prominent single-stage detectors include YOLO (You Only Look Once), Single Shot MultiBox Detector (SSD), and RetinaNet.

Here is a table summarizing the key differences between single-stage and two-stage detectors.
Notable Object Detection Algorithms and Models
Now that we understand the types of detectors, let's take a detailed look at some of the top object detection models. First, we will discuss the single-stage detection algorithms.
One-Stage Object Detectors
The one-stage model includes the following:
YOLO (You Only Look Once) Family
YOLOv1 introduced the idea of dividing the image into a grid and predicting two boxes per grid cell, each with a class label and confidence.
Since then, the YOLO series has gone through several versions. Each new version has improvements in design and algorithms. The upgrades have made models faster, more efficient, and better overall.

Major improvements observed in the YOLOv5 release (proposed by Glenn Jocher). It uses CSPDarknet as its backbone, a version of the original Darknet architecture that includes Cross-Stage Partial connections by splitting feature maps into separate paths.
Moreover, YOLOv5 uses the Spatial Pyramid Pooling Fast (SPPF) module for multiscale input feature representation. It also implements augmentations like Mosaic, copy-paste, random affine, MixUp, HSV, and horizontal flip.

Next, YOLOv8 brings further evolution in the YOLO series with five scaled versions for image classification, pose estimation, and instance segmentation alongside object detection.
YOLOv8 uses a backbone similar to YOLOv5, with modifications in the CSPLayer (the C2f module). It combines high-level features with contextual information to improve detection accuracy.

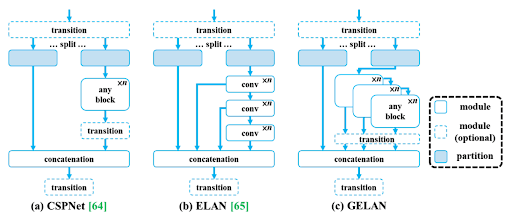
YOLOv9 introduced architectural advancements like Programmable Gradient Information (PGI) and GELAN to help the model learn better and faster.
PGI dynamically adjusts the gradient information during training to optimize learning efficiency, while GELAN improves parameter utilization and reduces the amount of computation required.
YOLOv10 advanced the pipeline further by removing the need for NMS via a dual-assignment training strategy, which helps reduce inference latency. It uses Path Aggregation Network (PAN) layers for effective multiscale feature fusion in the neck.
The One-to-Many Head produces multiple predictions during training for better learning, while the One-to-One Head generates a single prediction during inference.

Next, YOLO11 builds upon the YOLOv8 and introduces the Cross-Stage Partial with Self-Attention (C2PSA) module.
It also replaces the C2f block with C3k2, a custom implementation of the CSP Bottleneck that uses two convolutions, unlike YOLOv8’s use of one large convolution.

The latest YOLO series model is YOLOv12, which introduces an attention-centric design that greatly improves speed and accuracy. It uses Area Attention (A2) to maintain a large receptive field while reducing computational complexity without losing accuracy.

Also, YOLOv12 features Residual Efficient Layer Aggregation Networks (R-ELAN) that enhance training stability and convergence through block-level residual design and optimized feature aggregation.

SSD (Single Shot MultiBox Detector)
SSD (proposed in 2016) is another influential one-stage model. Its main contribution was using multiple feature maps from different layers of the backbone network to make predictions.
Predictions from higher-resolution maps detect small objects, while those from lower-resolution maps handle larger objects.

RetinaNet
RetinaNet uses a feature pyramid network on top of a backbone to detect objects at different scales and aspect ratios.
It addressed a key problem holding back single stage detectors, an extreme class imbalance. During training, the vast majority of anchor boxes are easy negatives (background).
RetinaNet introduces a new loss, the Focal Loss, that dynamically down-weights the loss assigned to well-classified examples. It forces the model to focus on learning hard-to-classify objects.

Two-Stage Object Detectors (RCNN Family)
The two-stage architecture models include the following:
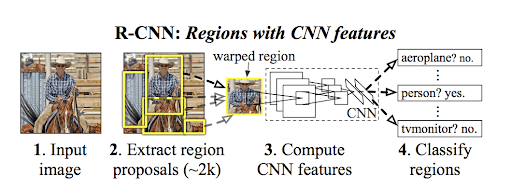
R-CNN (Region-Based Convolutional Neural Network)
The RCNN (proposed by Ross Girshick) was one of the earliest successful deep learning methods for object detection.
It produces a set of region proposals using an external algorithm (selective search), then applies a pre-trained CNN to each proposal to extract features. Lastly, it classifies each proposal with a support vector machine (SVM).
Fast-RCNN (Fast Region-Based Convolutional Neural Network)
The Fast R-CNN (proposed by Ross Girshick in 2015) improved on R-CNN by passing the entire image to the CNN just once to generate a feature map. Then, it uses region of interest pooling to extract fixed-length feature vectors for each region proposal.
These feature vectors are then input into a fully connected layer set that performs object classification and bounding box regression.

Faster-RCNN (Faster Region-Based Convolutional Neural Network)
Faster R-CNN ( proposed by Shaoqing Ren in 2015) replaces the slow selective search with a region proposal network (RPN).
The RPN first generates region proposals directly from the CNN to find areas of the image that likely contain objects.
Then it shares convolutional layers with the object detection network, which allows it to be trained end-to-end with the rest of the network.

Mask R-CNN
Mask R-CNN (2017) builds on Faster R-CNN by adding a parallel branch that outputs a segmentation mask for each detected object.
It starts by extracting key features with a deep neural network and identifies potential object regions with a region proposal network that suggests likely areas. Then, it refines these areas with detailed segmentation masks that outline each object's shape.

Transformer-Based Detectors
Transformers, a model architecture originally proposed for language tasks, like translating sentences. Now they have made considerable progress in computer vision, notably in detecting objects.
Detection transformers use self-attention mechanisms to weigh the importance of different parts of an image, which helps them build global relationships between pixels.
DEtection TRansformer or DETR variants are more recent pioneering models that employ transformers for detection tasks.
DETR treats object detection as a direct set prediction problem. It consists of a convolutional backbone followed by an encoder-decoder Transformer, which can be trained end-to-end for object detection.
It greatly simplifies much of the complexity of models like Faster-R-CNN and Mask-R-CNN, which use things like region proposals, non-maximum suppression, and anchor generation.

Letter research brings more DETR variants, such as RT-DETR and RT-DETRv2.
RT-DETR (Real-Time DEtection Transformer) is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy.
But RT-DETRv2 improves RT-DETR by adding selective multi-scale feature extraction and enhanced training methods like dynamic data augmentation and scale-adaptive hyperparameters.
These updates increase flexibility and practicality while keeping real-time performance.

Comparison of Top Models
Choosing an object detection model often involves a trade-off between accuracy and speed. But it’s important to note that the algorithm choice also depends on the use case, since different algorithms excel at different tasks.
The accuracy is typically evaluated by mean Average Precision (mAP) on the Microsoft COCO dataset (a higher mAP is better). While speed is measured in Frames Per Second (FPS), a higher FPS means faster, real-time performance.
Here’s a quick comparison of a few SOTA (state of the art) models on the COCO benchmark and their typical speeds:
- Faster R-CNN: Offers reliable performance with approximately 41 mAP on COCO and runs at about 5 FPS on a GPU.
- YOLO11: It achieves 54.7 mAP at roughly 11.3 ms per image on a T4 GPU.
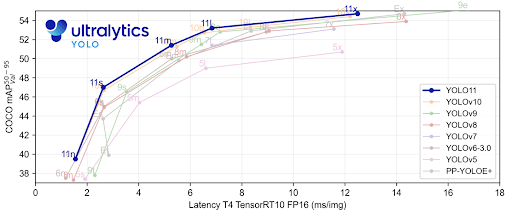
- YOLOv12: It achieves 55.2 mAP (COCO) at roughly 11.79 ms per image on a T4 GPU.

- DETR (2020): It achieves around 42 AP. With the ResNet-50 backbone, it runs at ~28 FPS, though at the cost of longer training and a complex architecture.
- RT-DETR-R101: It hits 54.3 AP at 74 FPS, outpacing many CNN-based detectors.

Training Data and Techniques for Object Detection
The model architecture is only half the story. The quality of the training data and the techniques used during training are just as critical for achieving high detection performance.
💡Pro Tip: When deciding how much labeled data you need versus what can be learned from unlabeled examples, our Supervised vs Unsupervised Learning article provides a clear comparison of these learning paradigms.
Annotated Training Data
The foundation of any supervised object detection model is a large, quality dataset. It consists of thousands of images where every object of interest is manually labeled with a bounding box and a class label.
Popular public datasets that you can explore to get the annotated data include COCO, Pascal VOC (visual object classes), and Open Images.
You can also explore different platforms like Kaggle or Huggingface to get the labelled data for training of your detection model.

Additionally, consider Lightly AI data services for high-quality labeled datasets tailored to your use case. We deliver domain-specific, human-in-the-loop labeled data that is perfect for pretraining, fine-tuning, or evaluation.
We combine unlabeled, synthetic data and human feedback to reduce labeling overhead and raise dataset quality. This hybrid approach helps teams build stronger object detection pipelines with less manual effort.
💡Pro tip: To reduce annotation effort in detection pipelines, our The Practitioner Guide to Active Learning in Machine Learning article explains how strategic sample selection accelerates model improvement.
Data Augmentation
We use data augmentation to avoid teaching the model to memorize the training data and to help it work well with new, unseen data.
It creates new training images by modifying the original images, such as flipping, rotating, resizing, cropping, or changing colors. More advanced techniques, like mosaic augmentation, combine several images into one.

Transfer Learning (Pretrained Backbones)
Training a large object detection model from the beginning takes more computing power and needs a large set of training images.
Instead, we usually use transfer learning to start with a pretrained image recognition model (like one trained on ImageNet) and use it to recognize common visual features as a starting point.
Since a pretrained model already understands general visual patterns, you only need to make small adjustments by training it further on your smaller, specific dataset.

Active Learning for Object Detection
Labeling data can be costly and time-consuming. Active learning helps reduce these costs by focusing on the most uncertain or informative unlabeled data points.
It sends only those data points to people to label, which helps the model learn better with fewer labels.
You can use the Lightly platform to do active learning at scale. LightlyOne processes raw, unlabeled image data and selects the most informative samples for labeling, which mitigates dataset bias.

Evaluation Metrics and Detection Performance
It is always important to discuss which evaluation metrics to use to understand the model's performance on holdout sets before production.
Here are a few key metrics we can use to evaluate the object detection models.
- Intersection over Union (IoU) or Jaccard Index: It measures the overlap between a predicted bounding box and a ground-truth bounding box. It is calculated as the area of the intersection divided by the area of the union.

- Precision: It quantifies the accuracy of a model's positive predictions (correct). Specifically, it answers the question, Of all the predictions made by the model, what fraction was correct?
- Recall: It measures the ability of a model to find all relevant objects within an image and address the question, Of all the actual objects in the picture, what fraction did the model find?

- Average Precision (AP): It is the area under the Precision-Recall curve, which summarizes the model's performance across all confidence thresholds (IoU thresholds) for a single object class.
- Mean Average Precision (mAP): If there are multiple object classes, we take the AP for each class and then average them to get mAP. This gives an overall single number for the detector’s performance across all classes.
Sometimes additional metrics are used depending on the application, such as Precision at a Fixed Recall, which evaluates accuracy for high-stakes tasks by measuring precision at a required recall level (like finding 99% of all obstacles).
Similarly, Mean IoU of Detections measures the average tightness of the model's correct bounding boxes by averaging the IoU score for all true positive detections.
Another metric is FPS (frames per second), which measures the model's processing speed by indicating the number of images it can analyze per second.

Applications of Object Detection
Object detection has many applications in our day-to-day lives. In this section, we will cover some of the most common object detection systems across industries.
Autonomous Vehicles (ADAS)
Self-driving cars and advanced driver assistance systems (ADAS) use object detectors to see and understand their surroundings using cameras and sensors. They can spot other vehicles, people, road signs, and obstacles.
For example, a system can find a pedestrian's location and predict which way they might move to avoid accidents. Autonomous vehicles equipped with LIDAR use 3D object detection, which applies cuboids around objects.

Security and Surveillance
Security systems use object detection to monitor persons or objects of interest automatically through cameras. It can detect intruders, abandoned bags, or unusual activity in restricted areas.
For example, in London, local councils have set up AI-enhanced CCTV networks that can identify suspicious behavior like loitering or aggressive actions and alert operators right away.

Medical Imaging
The object detection methods assist doctors in locating and highlighting abnormalities in medical imaging scans like X-rays, CTs, and MRIs. For example, it can perform tumor detection, lesions, or other pathologies, which help with early diagnosis.

Retail and Manufacturing
In retail stores, object detection helps with things like automatic checkout and keeping track of inventory.
For instance, Amazon Go stores use cameras with object detectors to see what products customers pick up and track their selections without needing cashiers.

In manufacturing, it is used to identify defective parts on assembly lines by detecting problems in real-time.

Aerial and Satellite Imaging
Object detection analyzes pictures from drones or satellites to find things like buildings, cars, or crops. In farming, it helps spot plant diseases or count animals from above. For disaster response, it finds broken buildings in satellite images to help relief teams.

Document Analysis
Beyond natural images, object detection applies to documents. It detects and locates text regions, tables, or signatures in scanned papers. This helps automate data extraction for tasks such as invoice processing or form recognition.

Challenges in Object Detection
Even though object detection has improved a lot, there are still many problems that researchers are working on to make the models better and more accurate.
Here are some major challenges and their solution:
Small and Dense Object Detection
Detecting tiny objects or those in crowded scenes with high object density remains difficult. Small objects often occupy a few pixels in the input image, which leads to information loss during downsampling in CNNs.
In dense scenes, like a crowd of people or a crate of apples, objects overlap greatly. This makes it difficult for a model to tell where one object ends and another begins, often resulting in merged or missed bounding boxes.
Solution
Use multi-scale feature extraction via feature pyramid networks that combine high-resolution shallow layers for small objects with deeper semantic layers for context.
Deformable convolutions adjust the network samples' features to better focus on clusters of objects.
A small object detection survey emphasizes hybrid methods like attention-guided upsampling, which improves small object detection accuracy by 10-15% on the COCO dataset.

Occlusion and Viewpoint Changes
When part of an object is partially occluded (hidden), like a person hiding behind a car, the model can only see some of its features. This can confuse the detector and cause it to miss the object or identify it incorrectly.
Also, objects viewed from odd angles, such as a car from directly above, can look different from the examples in the training data, which leads to poor detection performance.
Solution
Use context-aware models that understand the global scene via graph neural networks or part-whole hierarchies, where detectors predict occluded parts based on visible cues.
For viewpoints, rotation-invariant convolutions or data augmentation with synthetic rotations help.

Class Imbalance and Rare Objects
In real-world data, some objects are much more frequent than others. For example, a traffic monitoring dataset might have thousands of pictures of cars but only a few dozen pictures of bicycles.
Because of this, a model trained on this data will be good at recognizing cars but not so good at recognizing bicycles, which are rare.
This bias toward the most common class is a critical issue in applications like manufacturing defect detection, where defects are naturally very rare.
Solution
Use long-tail recognition with meta-learning, where models learn to adapt to few-shot rare objects. It improves mAP on imbalanced benchmarks like LVIS by 12-18%.
Synthetic data generation via generative adversarial networks (GANs) creates diverse, rare samples, but note that realism remains a challenge to avoid domain gaps.
Active Learning and Data-Centric AI
As datasets expand, it becomes crucial to decide which data to label or use to minimize annotation costs. Random sampling often includes redundant images, which waste resources.
Solution
Use an active learning technique, where the model itself points out the most confusing unlabeled data samples, which are then prioritized for human labeling.
Ethical and Bias Concerns
If the training data is biased, the model will be biased too. This is because the model's fairness depends on the quality of the data it learns from.
For example, if the dataset mostly shows people of one ethnicity, the model might not work well for people of other ethnicities.
Solution
Mitigations include diverse datasets, bias audits with metrics like demographic parity, and debiasing techniques during training.
LightlyTrain: Supercharging Object Detection with Your Own Data
Training effective object detection models starts with training on data that prepares the model for your specific use case. LightlyTrain makes that easy.
It uses a self-supervised approach to pretrain the model on unlabeled data and adapt it to your domain before fine-tuning. This lets the model learn relevant features, so it performs better with less labeled data.
The LightlyTrain supports various models like YOLOv12, RT-DETR, RF-DETR, and custom architectures. Below, we provide the minimum scripts for pretraining using ultralytics/yolov12s as an example:
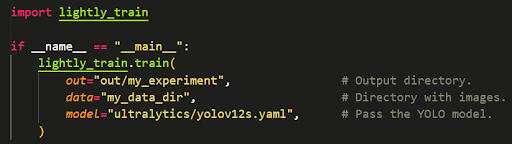
Or alternatively, pass a YOLOv12 model instance directly:

- LightlyTrain GitHub: https://github.com/lightly-ai/lightly-train
- LightlyTrain Documentation: https://docs.lightly.ai/train/stable/index.html
Conclusion
Object detection teaches machines to see and understand the world around them. It is used in many practical applications, such as security systems, by identifying objects in an image and their corresponding locations.
However, issues like detecting small objects and biases in data still pose challenges. As an ML engineer, you can build strong detectors by starting with the right tools and data curation and achieve high performance with ease.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


