
Effective Domain Adaptation Techniques for Improved Model Performance
Table of contents
Share blog post



Domain adaptation helps models trained on one dataset perform well on another with a different distribution. By learning domain-invariant features through reweighting, feature alignment, or fine-tuning, models generalize better across domains.
Share blog post
Here is what you need to know about domain adaptation.
What is domain adaptation?
Domain adaptation is a technique (a specific form of transfer learning) that lets a model trained on a source domain perform well on a target domain with a different data distribution.
The goal is to learn domain-invariant features, allowing inputs from both domains to be handled similarly. This enables accurate predictions even when the target domain has little or no labeled
How is domain adaptation related to transfer learning?
Domain adaptation is a subset of transfer learning. Transfer learning spans moving knowledge across tasks or domains. In contrast, domain adaptation focuses on the same task with different data distributions, usually with limited or no target labels.
All domain adaptation is a form of transfer learning. However, not all transfer learning is domain adaptation.
What techniques are used for domain adaptation?
There are several domain adaptation techniques used to learn domain-invariant features and reduce the divergence between source and target distributions.
Major approaches include:
- Instance reweighting: Reweight source samples to match target distribution.
- Feature alignment: Minimize source–target discrepancy (e.g., MMD, CORAL, adversarial feature alignment).
- Parameter/fine-tuning: Share or adapt layers; freeze backbone, fine-tune heads or adapters using limited target data.
Generative approaches: Translate or augment data across domains (e.g., GAN-based style transfer) to reduce the gap.
We face challenges in machine learning (ML) when data changes between training and real-world use. Models expect the data they see in the real world to be similar to the data they were trained on.
When there's a mismatch, a problem known as domain shift occurs, and the model's performance degrades.
Domain adaptation provides a solution. It involves adjusting a model in one setting so it can adapt and perform well in another.
In this guide, we will walk you through:
- What is domain adaptation, and why do we need it
- What techniques are used for domain adaptation
- Common domain adaptation techniques and approaches
- Applications of domain adaptation in practice
- How Lightly can help with domain adaptation
Domain adaptation demands high-quality data. Lightly provides tools to help teams bridge domain gaps and improve model performance:
- LightlyOne helps you find the most relevant and diverse samples from both your source and target domains. This makes your models more accurate and better at generalizing across different environments.
- LightlyTrain lets you pretrain and fine-tune models using self-supervised learning. This builds stronger domain-invariant features, so you don’t have to rely as much on large labeled datasets from the target domain.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
What is Domain Adaptation?
Domain adaptation is a machine learning technique to improve a model’s performance on a target domain by using knowledge from a related source domain.
The source domain is the dataset on which the model is originally trained with labeled data. The target domain is the new dataset where we want to apply the model.
Domain adaptation assumes that the tasks or categories are the same, such as both domains involving the classification of the same object categories. However, the data distributions differ, such as in pixels or features.
For example, a source domain of well-lit outdoor photos and a target domain of dim indoor photos share the same labels like “car” or “person” but have different lighting distributions.
Let's define core concepts in more detail for a better understanding of the domain adaptation:
- Source Domain: The original domain (dataset) on which the model is trained. It is defined by a specific data distribution and has a sufficient amount of labeled data for training.
- Target Domain: The new domain (dataset) where the model will be deployed. The target domain often has a different data distribution and typically has very limited or no labeled data available.
- Domain Shift (Domain Gap): Any systematic difference between the source and target data distributions. This could be differences in image style, background, sensor type, language usage, etc.
- Domain-Invariant Features: Representations or feature patterns that are shared across both domains. The model can operate effectively in both domains by learning features that do not encode domain-specific quirks.
💡Pro tip: When adapting models across domains, our Vector Indexes and Image Retrieval using LightlySSL article illustrates how retrieval workflows can surface the most relevant cross-domain samples.
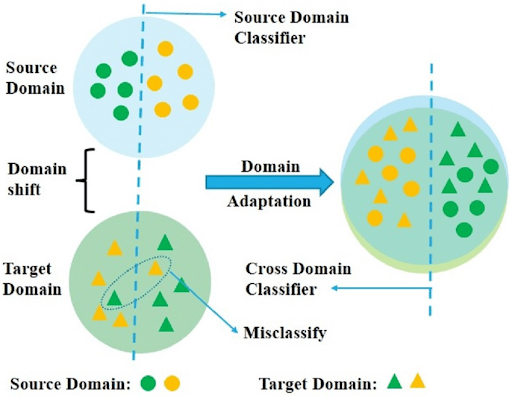
The Domain Shift Problem: Why Do We Need Domain Adaptation?
Modern deep learning models excel when training and test data come from the same distribution, but in real-world deployment, they often do not. A model trained on one domain can degrade badly if the deployment domain’s data shifts even slightly.
For instance, a photo classifier trained on bright daylight images may mislabel the same scenes taken at dusk or under different cameras.
This domain gap means that without adaptation, each new domain would force us to collect and annotate new data or retrain the model, which is costly.
Domain adaptation is necessary to address the practical challenges posed by this gap. Key reasons include:
- Limited Labeled Data in Target Domain: Collecting and labeling new data for every new deployment scenario is often impractical or expensive. As in the medical imaging field, new equipment or patient populations can create shifts. However, manually labeling new scans is time-consuming. Domain adaptation allows us to reuse existing labeled datasets to build a model to perform well on a new domain with few or no labels.
Pro tip: Looking for high-quality labeled data or domain-specific curation? Check out Lightly’s Training Data Services or our list of 5 Best Data Annotation Companies in 2025 [Services & Pricing Comparison].
- To Prevent Performance Degradation Across Domains: Even when the task remains the same, differences such as sensor noise, lighting, language, or demographics can alter the data distribution. A model can confidently misclassify under these changes. For example, a natural language processing (NLP) classifier trained on American English text may perform poorly on British English text due to differences in word usage. Instead of retraining from scratch on British English, domain adaptation learns to handle that shift.
- Reusing Models to Save Time and Compute: Large deep learning models are expensive to train from scratch, often requiring weeks of GPU time. Reusing and adapting an existing model saves considerable compute and energy. Instead of discarding a well-trained model, domain adaptation allows us to reuse and fine-tune it for new domains.
- To Build More Robust and Generalizable Models: We improve models' robustness by specifically training them to handle domain shift. A well-adapted model will be less brittle when faced with unseen target samples or slightly different environments. In the long run, this leads to models that generalize better across contexts.
Domain Adaptation vs. Transfer Learning vs. Domain Generalization
Domain adaptation is closely related to transfer learning and domain generalization, but each has a distinct focus in machine learning contexts.
Transfer learning reuses knowledge from one domain or task to improve performance in another. This can involve various tasks, such as using ImageNet-trained weights for medical image classification.
Domain adaptation, on the other hand, assumes the task and label space are the same and focuses on handling differences in data distribution.
%2C%20its%20various%20types%2C%20and%20domain%20adaptation%20(2).png)
Domain generalization trains a model that performs well on unknown, unseen domains without requiring any further adaptation. That typically involves training on multiple source domains so that the model learns invariant features that generalize across domains.
In contrast, domain adaptation assumes you have access to (possibly unlabeled) data from the target domain during training, and that you adapt the model to that domain.

The table below summarizes the key distinctions between these three fields.
Types of Domain Adaptation
Domain adaptation problems vary depending on the available data and the differences between the source and target domains. Correctly identifying the type of problem you are facing is the first step in choosing the right solution.
Availability of Target Labels
Domain adaptation problems are often classified based on the availability of labeled data in the target domain.
1. Supervised Domain Adaptation
Supervised adaptation is ideal if the target domain has fully labeled data. But it is rarely seen in practice due to the high cost of labeling.
If plenty of target labels are available, standard supervised learning techniques can often solve the problem. These include approaches like fine-tuning a pre-trained model from the source domain using the target data.
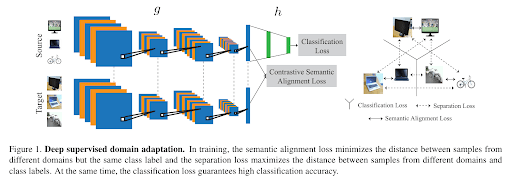
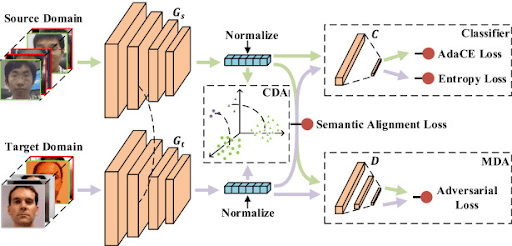
Supervised domain adaptation can be achieved through various methods. One such method is detailed in a paper that introduces a classification and contrastive semantic alignment (CCSA) loss.
In this method, a deep learning model maps input images into a shared embedding space and then performs classification. Within this embedding space, the CCSA loss is used to:
- Minimize the distance between samples from different domains that share the same label, and
- Maximize the distance between samples from different classes, regardless of their domain.
This joint optimization helps align domain features while preserving clear class separation.
2. Semi-Supervised Domain Adaptation (SSDA)
SSDA is a go-to option for problems where the target domain has only a small amount of labeled data but a larger pool of unlabeled data.
It combines supervised and unsupervised learning. This allows you to train a model directly on the few labeled target samples. At the same time, it uses a large set of unlabeled target data alongside the labeled source data.
Practically, the model aligns feature distributions between the source and target domains by minimizing unsupervised alignment losses. These may include adversarial losses, entropy minimization, or discrepancy-based objectives.
These losses encourage the model to produce similar feature representations for source and target images, even when the target samples lack labels.

Here, the feature extractor (G) learns shared representations from labeled source data, a few labeled target examples, and a large pool of unlabeled target samples. It projects all inputs into a common feature space, where the classifier (C) predicts class probabilities.
Training alternates between supervised and unsupervised steps, using classification loss on labeled examples and alignment or entropy-based loss on unlabeled ones.
This process ensures that the feature extractor produces domain-invariant embeddings and allows the model to perform reliably in the target domain even with minimal labeled data.
3. Weakly-Supervised Domain Adaptation (WSDA)
In WSDA, the target domain contains labels, but they are weak or imprecise. For example, in a segmentation task, you might have image-level tags such as "this image contains a car", instead of precise pixel-level masks.
Weak labels are easier to collect than full annotations and can still provide valuable supervisory signals or guidance to constrain the adaptation process.
Pro Tip: Check our list of 12 Best Data Annotation Tools for Computer Vision (Free & Paid).
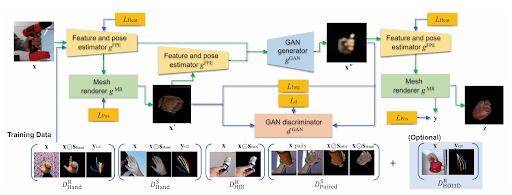
Consider the task of 3D hand pose estimation under Hand-Object Interaction (HOI) settings. In such cases, obtaining full 3D annotations is difficult due to occlusions and the high cost of labeling.
This paper introduces a novel Weakly Supervised Domain Adaptation method to adapt a model trained on hand-only data (with 3D labels) to the HOI domain (without 3D labels).
The approach uses 2D object segmentation masks from the target domain as weak supervision. These masks guide the model in distinguishing between hands and objects during the adaptation process.
The framework combines a GAN-based image-to-image translation model with a 3D mesh reconstruction model to transform HOI images into a “hand-only” appearance. The adaptation aligns the domains by teaching the network to predict accurate 3D hand poses even in occluded, object-interaction scenarios.
Although the HOI data lacks full 3D labels, the weak 2D masks provide sufficient structural cues to effectively bridge the gap between the hand-only and HOI domains.
4. Unsupervised Domain Adaptation (UDA)
Unsupervised domain adaptation is another good option for problems where the target domain has no labels.
UDA methods rely entirely on aligning the source and target distributions using only unlabeled target samples. Techniques include aligning features, adversarial training, and reconstruction, all without target labels.
Feature Space and Input Modalities
Feature space and input modality classification depend on the nature of the data in the source and target domains. The domains may share the same input features, or they may differ in structure and modality.
Homogeneous Domain Adaptation
The source and target domains have the same feature space and input structure. For example, adapting between two RGB image datasets, or between two text corpora of the same language.
In this case, we can directly compare features (pixels, vectors) between domains. Although the distributions of these features differ, the features themselves are directly comparable.
Heterogeneous Domain Adaptation
Heterogeneous domain adaptation deals with cases where the source and target domains have different feature spaces or even varying modalities.
For example, the source could be text data and the target images (or vice versa), or one domain could be RGB images and the other multispectral images.
Since inputs differ, adaptation requires learning a common latent space where data from both domains can be meaningfully compared and aligned.

Here, we have two distinct domains, the source domain (French sentences) and the target domain (Spanish sentences). Each domain has its own features and distributions. Directly aligning them isn’t possible because they exist in different feature spaces.
To overcome this, the model projects both domains into a common representation space using a latent embedding or neural mapping to capture shared semantics.
Through domain adaptation, the system minimizes the gap between the representations. This makes the features from both domains more homogeneous and comparable.
The adapted representations from both domains (shown as triangles in the bottom section of the image) align closely in the same feature space by the end of the process.
This alignment enables the model to transfer knowledge from labeled data in the source domain to improve predictions in the target domain, even though their original data types differ.
Label Space Overlap
The relationship between the sets of classes in the source and target domains defines another critical set of categories. Applying a method that assumes the wrong label space relationship can result in significant performance drops.
6. Closed-Set Domain Adaptation
The source and target domains have identical label sets (they cover the same classes). The goal is to adapt a classifier to shared categories when only the domain (data distribution) changes, with all classes present in both source and target.
7. Partial Domain Adaptation (PDA)
In partial domain adaptation, the target label space is a subset of the source label space. For example, a source dataset contains 10 classes, but the target dataset includes only 5 of them.
When adaptation is performed using this method, source-only classes are detected and disregarded. It prevents irrelevant source categories from confusing the model during adaptation to a smaller target label set.

8. Open-Set Domain Adaptation
Open-set domain adaptation (OSDA) is used when the target domain contains some classes that were not present in the source domain.
In simpler terms, the model encounters new, unknown categories during testing that it never saw during training.

The model must correctly classify the known classes shared with the source while also identifying and rejecting instances of the new, unknown classes.
It is crucial for building safe and reliable systems that can recognize when they encounter something they were not trained on.

In the diagram, on the left, you can see the labeled source domain, where all training samples belong to known classes. The unlabeled target domain, however, includes both known and unknown classes (highlighted in red).
A feature extractor, a pretrained CNN, transforms both source and target images into numerical feature representations. The system then passes these features through a decoder and a softmax classifier to predict class probabilities.
A special gradient reversal mechanism helps the model separate known and unknown features. It encourages the model to minimize the classification loss for known classes while maximizing uncertainty for unknown ones.
As a result, the model learns to classify familiar samples correctly and flag unfamiliar samples as belonging to an additional “unknown” class.
9. Universal Domain Adaptation
Universal domain adaptation is a general case that covers both partial and open-set situations. Neither the source nor target label sets are assumed to be subsets of the other.
Both the source and target domains can have their own private classes, as well as some common classes.
Universal domain adaptation methods aim to detect the classes shared by the source and target domains and adapt to them. They also reject samples from each domain’s private classes as “unknown.”
Number of Domains
The number of source or target domains involved can also define adaptation problems.
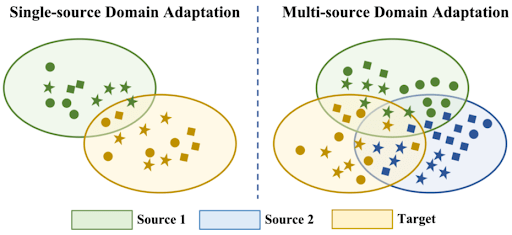
10. Single-Source vs. Multi-Source Domain Adaptation
The classic setup involves a single source and a single target domain. However, in many cases, we have multiple labeled source domains available for training.
A multi-source domain adaptation algorithm can use all diverse source data jointly to build a more powerful model for the target domain.
Mixing all source data can be counterproductive if the sources differ significantly. However, specialized techniques are necessary to effectively weigh and combine knowledge from each source.
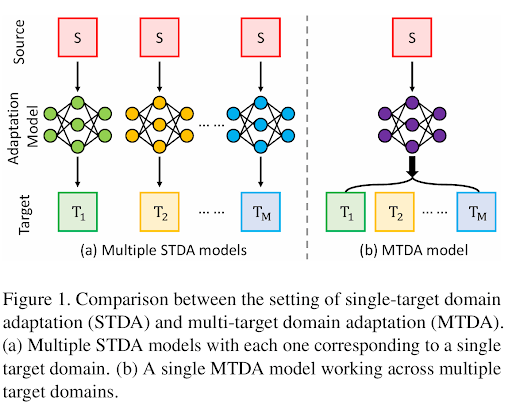
11. Multi-Target Domain Adaptation
Multi-target domain adaptation (MTDA) allows a single model to function across multiple, distinct target domains simultaneously. It differs from single-target adaptation, which only aligns a source domain with a single target.
MTDA learned a generalized representation that bridges multiple domain shifts by disentangling domain-specific features or dynamically adjusting model parameters. This paper introduces a framework, Collaborative Consistency Learning (CCL), to address this challenge.
The main idea behind CCL is collaboration among multiple expert models. Each expert model is trained on one specific target domain, allowing it to specialize in that domain’s unique features and patterns.
However, instead of treating these experts independently, CCL encourages them to collaborate by sharing information and aligning their predictions through consistency constraints.
%20framework%20for%20MTDA%20in%20semantic%20segmentation.png)
During training:
- Each target domain has its own domain-specific expert network that learns features suited to that particular environment.
- These expert models then collaborate by exchanging knowledge and ensuring that when they make predictions on shared or overlapping data, their outputs remain semantically aligned in the feature space.
- Once these expert models achieve consistency, their collective knowledge is distilled into a single student model.
- The student model learns to integrate the representations of all expert models into one unified network and combine both domain-invariant (shared) and domain-specific (unique) features.
Adaptation Stages
The magnitude of the domain gap can influence the adaptation strategy.
12. One-Step vs. Multi-Step Adaptation
Sometimes, a large domain gap can be bridged by introducing intermediate domains.
The model is adapted progressively along a path of domains. It moves from the source to an intermediate domain, and finally to the target domain. At each step, it solves a series of easier adaptation problems with smaller domain gaps.
For example, to adapt a model from highly stylized art images to medical scans, one might first go through an intermediate domain in two steps instead of jumping directly.
Common Domain Adaptation Techniques and Approaches
Many techniques have been developed to address the domain shift problem.
These methods typically seek features that are consistent across domains, focusing on task-relevant information while ignoring domain differences.
Below are some of the most common and effective approaches.
1. Instance-Based Reweighting (Data Distribution Alignment)
These methods adjust or reweight source samples to make their distribution more closely match the target distribution.
One common strategy is to assign importance weights to each source instance. This is often done by comparing the feature distributions of the source and target datasets. Once the weights are calculated, the model is trained on the reweighted source data.
The goal is to give more weight to source examples that resemble the target and reduce the influence of those that don't.
Instance reweighting is simple and interpretable, but it requires some overlap between source and target data distributions to work well. If the overlap is small or the feature mapping is very complex, reweighting alone might fail.
2. Feature Alignment via Statistic Matching
A large class of domain adaptation techniques explicitly aligns the statistical properties of the source and target data distributions within a shared feature space.
The model is encouraged to produce similar feature representations for inputs from both domains by minimizing a chosen distance metric between the distributions.
Common choices for the statistical metric include:
- Maximum Mean Discrepancy (MMD): A non-parametric metric to measure the distance between the mean embeddings of the source and target feature distributions in a high-dimensional space known as a Reproducing Kernel Hilbert Space (RKHS). Minimizing the MMD loss during training pulls the two distributions closer together and promotes domain invariance.
- Correlation Alignment (CORAL): CORAL aligns the second-order statistics of the feature distributions. It minimizes the difference between the covariance matrices of the source and target features, often through a linear transformation.
- Other Distances: Other metrics like the Wasserstein distance, which is based on optimal transport theory and contrastive domain discrepancy, are also used to measure and minimize the gap between distributions.
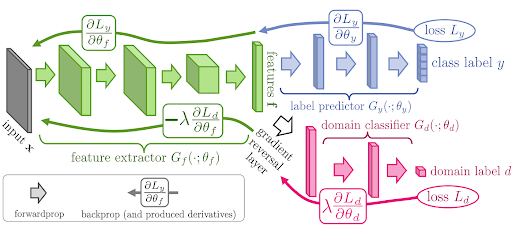
3. Adversarial Feature Learning (Domain-Adversarial Training)
Inspired by Generative Adversarial Networks (GANs), adversarial DA methods insert a domain classifier into the network and train it adversarially with the feature extractor.
- A feature extractor (part of the main model) that learns to map input data from both domains into a common feature space.
- A domain classifier (or discriminator) that is trained to distinguish whether a given feature vector came from the source or the target domain.
The feature extractor is trained to perform well on the main task, like classification using source labels, but also to fool the domain classifier.
It's forced to learn representations that are common to both domains by trying to generate features that the discriminator cannot reliably classify by domain.
While highly effective, this adversarial training process can be unstable and requires careful balancing of the learning rates and loss weights to ensure stability.
4. Reconstruction-Based Alignment (Autoencoder Auxiliary Tasks)
Another idea to align domains is to use an autoencoder or reconstruction objective as an auxiliary task on one or both domains.
The model's feature extractor acts as the encoder, and a separate decoder network is added. The model is then trained to perform two tasks simultaneously:
- Supervised classification on labeled source data.
- Unsupervised reconstruction of unlabeled target images.
This reconstruction loss encourages the feature extractor to preserve low-level information from the input. It helps create transferable features that are less prone to overfitting on source-specific artifacts.
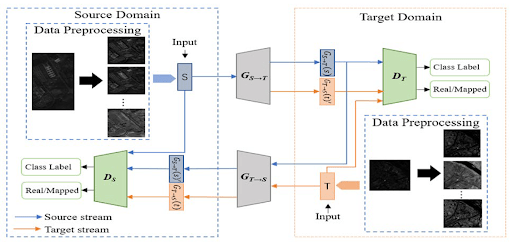
5. Generative Pixel-Level Adaptation (Domain Mapping with GANs)
Instead of aligning features, one can adapt at the pixel level by transforming source images to look like target images. This approach uses image-to-image translation generative adversarial networks, such as CycleGAN and StarGAN.
For instance, CycleGAN-based Domain Adaptation (also known as CyCADA) establishes two distinct mappings. One from the source to the target style and another from the target back to the source style.
This process incorporates a cycle-consistency constraint to preserve the original content.
After this training, every source image is “translated” into the target domain style. Next, the original source labels are used to train the task model on these adapted images.
This approach directly addresses low-level appearance gaps (lighting, color, texture) by altering the input images. It can help computer vision tasks where the styles differ, like synthetic-to-real driving scenes.
However, GANs are known to be difficult to train. The translation process can distort object shapes and adds the additional complexity of generating images as part of the pipeline.
6. Ensemble-Based and Self-Ensembling Methods
Ensemble methods use multiple models or ensembles to improve adaptation. If you have multiple source domains, train a separate model for each source domain, then average their predictions on the target domain. This can sometimes capture complementary knowledge and reduce variance.
Other approaches use self-ensembling or mean teacher models, where one model’s weights are an exponential moving average of another’s. Consistency losses encourage the teacher and student to agree on target samples.
Ensemble methods can improve robustness, but at the cost of more computation and more complex inference. Combining outputs from different models can also be a non-trivial task.
7. Semi-Supervised Adaptation Techniques
When a few labeled examples are available in the target domain, semi-supervised domain adaptation methods can incorporate those labels directly.
They combine the standard supervised loss on these few labeled target samples with an unsupervised domain-adaptation loss (e.g., MMD or an adversarial loss) on the remaining unlabeled target data.
It enables the model to use the valuable, albeit limited, information from the target labels to guide the adaptation process more effectively.
Pro tip: Make sure to also check out our Engineer's Guide to Self-Supervised Learning.
8. Self-Training and Pseudo-Labeling
Self-training and pseudo-labeling are iterative learning strategies used in unsupervised domain adaptation to improve model performance on unlabeled target data.
The idea is to let the model teach itself by gradually generating and refining its own labels for new data.
The process works as follows:
- Train a model on the labeled source data.
- Use this model to make predictions on the unlabeled target data.
- Select the predictions that exceed a certain confidence threshold and treat them as "pseudo-labels."
- Retrain or fine-tune the model on a combined dataset of the original source data and the pseudo-labeled target data. This can sharpen the decision boundaries on the target.
The primary risk of this approach is that if the initial model is inaccurate, it can generate incorrect pseudo-labels, thereby reinforcing errors.
9. Source Free Domain Adaptation (SFDA)
In the SFDA case, you do not have access to the source data at the time of adaptation. Instead, you only have a pretrained source model and unlabeled target data, and SFDA methods attempt to adapt the model without any source samples.
For example, one approach involves keeping the source classifier fixed while updating batch normalization statistics on the target data or employing self-supervised losses on the target.
This is challenging since the model must adapt blindly to where the source data lies.
However, it is increasingly important in practice when sharing raw source data is not allowed. Such methods trade off some performance for practicality.
The table below summarizes these approaches with their key ideas, whether they require labeled target data, and their pros and cons:
Applications of Domain Adaptation in Practice
Domain adaptation is essential for deploying machine learning models across various real-world applications, where data variability is common.
Here are some notable applications:
Computer Vision (Synthetic to Real)
In vision tasks, it is common to have easily generated synthetic data, such as simulation- or graphics-generated data, with perfect labels. However, the model must ultimately work on real images.
For instance, autonomous-driving datasets from simulators can be abundant and well-annotated. However, real-world driving images differ in texture and lighting.
Domain adaptation, especially pixel-level GAN methods, is often used to make synthetic images look real. It also aligns features so that models trained on synthetic data perform well on real camera images. This synthetic-to-real adaptation saves immense annotation effort.
Object Detection and Video Surveillance
Object detectors trained on one camera setup or environment may perform poorly when deployed in another (e.g., different angle, resolution, lighting). In video surveillance, cameras vary in quality and viewpoint.
Domain adaptation can address this by aligning feature representations or translating images to match the new conditions.
For example, if a car detector is trained on clear sunny data, adaptation techniques (like feature alignment or image translation) can improve performance on foggy night footage. Similarly, surveillance systems often adapt across different locations (indoor vs outdoor or different cities).
Pro tip: Working with YOLO models? Read YOLO Object Detection Explained: Models, Tools, Use Cases.
Medical Imaging
Medical image analysis is well-known for domain shifts. MRI or CT scans from different hospitals, scanners, or patient populations can have varying characteristics (contrast, noise, resolution).
A segmentation model trained on data from Hospital A might fail on Hospital B’s scans. Domain adaptation allows the use of a model across sites.
For example, it's possible to adapt a tumor-detection model trained on MRIs from one device to another without needing to collect a completely new labeled dataset.
This is extremely valuable because expert labeling in medicine is costly. Domain adaptation can reduce the need for new annotations by transferring knowledge across different medical imaging domains.
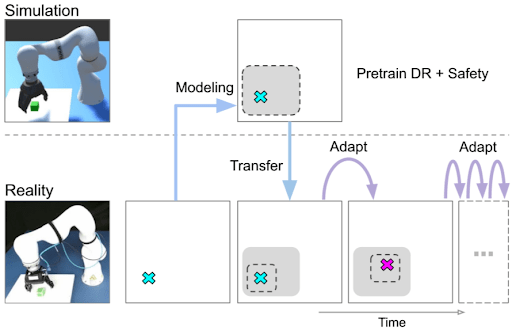
Robotics and Reinforcement Learning
In robotics, it is often much safer and cheaper to train policies in simulation before deploying on a real robot. Yet, the real environment differs from the simulator.
Domain adaptation helps transfer learned policies from simulation to the real world. This includes adapting vision-based manipulation policies to work on a physical robot’s camera feed.
Techniques include domain randomization during training and feature layer alignment to make the learned policy robust to the sim-to-real gap. This sim-to-real adaptation is crucial for using reinforcement learning in physical systems.
Cross-Domain Sentiment Analysis (NLP Example)
Outside of vision, domain adaptation is used in natural language processing.
A typical example is adapting a sentiment classifier trained on movie reviews (long, formal text) to work on social media posts like tweets (short, slangy text). The language distribution shifts considerably, but the task (sentiment polarity) is similar.
Domain adaptation techniques can help a sentiment model generalize from reviews to tweets. These include aligning feature representations of words or using adversarial language models. This avoids the need to label thousands of tweets when a labeled review dataset already exists.
How Lightly AI Can Help with Domain Adaptation
The core challenge of domain adaptation is a data problem. A domain gap arises from differences in data distributions, and the most effective solutions are often data-centric.
Overcoming the domain shift problem requires a deep understanding of both your source and target datasets. This is where a robust data curation platform like Lightly AI becomes essential.
LightlyTrain
LightlyTrain enables self-supervised pretraining on your own unlabeled images. You can learn rich domain-specific feature representations before any adaptation by pretraining a model on target-domain images or mixed source and target.
After pretraining, you fine-tune the model on whatever labeled target data you have. The result is a model that already understands your domain’s style and thus requires less adaptation.
This can dramatically reduce the amount of labeled data needed, since the feature extractor has already been tuned on the target domain distribution.
LightlyOne
LightlyOne helps you select the most valuable data points to label from your pool, using active learning strategies. It can identify which target-domain samples would most improve model performance if labeled.
For example, after an initial adaptation pass, there may be regions where the model is uncertain about the target data. LightlyOne can highlight similar unlabeled target samples for annotation.
It ensures that your labeled set covers the target distribution efficiently by focusing labeling effort on the most impactful target examples.
Conclusion
Domain adaptation makes machine learning practical and effective in real-world applications. It addresses the unavoidable domain shift problem, where a model trained in one context fails in another.
Engineers can bridge the gap between source and target domains by understanding the different types of adaptation problems and the array of available techniques.
The most successful strategies are data-centric, focusing on managing data distributions at the core of the challenge.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


