
Top Computer Vision Tools, Libraries & Frameworks in 2026
Table of contents
Share blog post



A practical guide to the best computer vision tools in 2026, covering deep learning frameworks (PyTorch, TensorFlow, OpenCV), annotation platforms (CVAT, Labelbox, V7), curation tools (LightlyStudio, FiftyOne), pretraining frameworks (LightlyTrain), end-to-end platforms (Roboflow, Encord, Supervisely), and MLOps solutions (W&B, ClearML, MLflow). Includes a quick comparison table and guidance on how to choose the right stack for your ML project.
Share blog post
The computer vision tooling landscape in 2026 spans six key categories — libraries, annotation, curation, pretraining, end-to-end platforms, and MLOps. Most production teams combine two or three complementary tools to cover the full pipeline from data to deployment.
- Foundational frameworks: OpenCV remains the standard for image processing, while PyTorch and TensorFlow dominate deep learning model development. Keras and Detectron2 sit on top for rapid prototyping and state-of-the-art object detection.
- Data annotation: CVAT (open-source, now with SAM 3 and YOLO11 auto-annotation), Labelbox, SuperAnnotate, V7, and Label Studio lead the space — with AI-assisted labeling now standard.
- Data curation: LightlyStudio (curation-first, embedding-based selection with built-in labeling) and FiftyOne (dataset visualization and model evaluation) help teams prioritize quality over quantity and cut annotation costs.
- Pretraining & fine-tuning: LightlyTrain enables self-supervised pretraining on unlabeled domain data, supporting YOLO, RT-DETR, DINOv3, and more — closing the gap between generic ImageNet weights and production performance.
- End-to-end platforms: Roboflow (developer-friendly, YOLO-centric), Encord (enterprise, physical AI, multimodal), and Supervisely (modular, app ecosystem) cover the full workflow.
- MLOps & experiment tracking: Weights & Biases leads with GenAI observability via W&B Weave; ClearML and MLflow offer strong open-source alternatives.
- How to choose: Start with a deep learning framework, add OpenCV, then layer in annotation, curation, and MLOps tools based on team size, data volume, deployment target, and privacy requirements (GDPR, HIPAA, EU AI Act).
Computer vision (CV) tools span a wide spectrum — from foundational deep learning frameworks like TensorFlow and PyTorch, to open-source libraries like OpenCV, to specialized platforms for data annotation, dataset curation, and model deployment. Computer vision enables machines to interpret, understand, and extract insights from visual data such as images and videos, powering applications like autonomous vehicles, facial recognition, and medical diagnostics. Machine learning engineers and CV developers today have access to a rapidly evolving ecosystem of tools that cover every stage of the pipeline.
Choosing the right combination of computer vision tools can significantly impact the efficiency, scalability, and accuracy of your machine learning models — whether you’re building object detection systems, image classification pipelines, image segmentation workflows, or real-time computer vision applications. AI models, including pre-trained, fine-tuned, and custom models, are central to modern computer vision applications and can be adapted for tasks like defect detection, medical imaging, and marketing automation. Since 2025, production CV stacks have moved toward stronger AI-assisted annotation, curation-first dataset workflows, and increasing use of deep learning and foundation model features in training and labeling pipelines, making it crucial to choose the right computer vision system for deployment—whether cloud, edge, or mobile.
This guide covers the full stack of CV tools across six key categories, highlighting the process of building computer vision models using both no-code platforms and traditional frameworks such as OpenCV, TensorFlow, PyTorch, and Detectron2:
- Computer Vision Libraries & Frameworks – Foundational open-source libraries and deep learning frameworks for building vision systems.
- Data Annotation & Labeling Tools for Building Computer Vision Models – Tools for creating labeled datasets (images/videos) for model training and validation.
- Data Curation & Dataset Management Tools – Tools for selecting high-value data, eliminating redundancy, and managing dataset versions.
- Model Pretraining, Fine-tuning & Model Training Frameworks – For building domain-specific vision models using unlabeled data.
- End-to-End Vision Platforms – Integrated platforms covering the full workflow from data ingestion to deployment.
- Experiment Tracking & MLOps Tools – Platforms to manage experiments, models, and collaboration in CV projects.
No-code computer vision tools allow users to build and deploy AI models without writing code, democratizing access to computer vision technology for non-technical users.
We’ve researched and evaluated the most popular computer vision tools, and highlighted those that experienced machine learning and computer vision engineers should know about. Vision-language models are also emerging, enabling systems to understand both images and text for enterprise applications such as insurance claims and product search. Let’s begin.
Quick Overview
This guide is written for machine learning engineers and compute20r vision practitioners who are building or scaling real-world computer vision systems. Whether you're working on object detection, image classification, medical imaging, autonomous vehicles, or quality control pipelines — and whether you're a solo engineer or part of a large team — the tools reviewed here cover the full spectrum of needs across libraries, frameworks, annotation, curation, model training, and deployment.
Let's now dive into it.
1. Computer Vision: Libraries & Frameworks
Before selecting annotation platforms or MLOps tools, most computer vision engineers need a foundational library or deep learning framework for building and training vision models. The process of building computer vision models can involve both no-code platforms and traditional code-based approaches, utilizing popular libraries such as OpenCV, TensorFlow, PyTorch, and Detectron2. These open-source tools form the backbone of the modern computer vision stack — handling everything from image processing and feature detection to training deep learning models and deploying them to production.
AI models—including pre-trained, fine-tuned, and custom models—play a crucial role in enhancing computer vision applications across industries, enabling tasks like defect detection, medical imaging, and marketing automation.
MATLAB is a programming platform that includes a computer vision toolbox, offering a variety of functions and algorithms specifically designed for developing computer vision solutions.
CUDA, developed by NVIDIA, is a parallel computing platform and API that leverages GPU processing power to accelerate computation-heavy tasks in computer vision and real-time AI inference.
OpenVINO provides open visual inference tools that enable the development of applications for object detection, face recognition, and other computer vision tasks, optimizing neural networks for Intel hardware.
- OpenCV: OpenCV is considered one of the most mature and widely used open-source computer vision libraries available. It supports multiple programming languages including C++, Python, Java, and MATLAB, and is compatible with Windows, Linux, and macOS.
1. OpenCV
Overview: OpenCV (Open Source Computer Vision Library) is the most widely used open-source computer vision library in the world. OpenCV is considered one of the most mature and widely used open-source computer vision libraries available. Originally developed by Intel, it provides over 2,500 optimized algorithms for real-time image processing, object detection, feature detection, camera calibration, and video analysis. It is the standard starting point for any computer vision developer and integrates with deep learning frameworks like TensorFlow and PyTorch.
Key Features:
- Over 2,500 algorithms for real-time image processing, object recognition, object identification, image recognition, and video analysis
- Supports multiple programming languages including C++, Python, Java, and MATLAB, and is compatible with Windows, Linux, and macOS
- Cross-platform: Windows, Linux, macOS, Android, and iOS
- GPU acceleration via CUDA integration
- Seamless integration with deep learning frameworks for pre/post-processing pipelines
- Active community support and extensive documentation
- Supports bounding box drawing, image segmentation masks, and visualization of model outputs
Weaknesses:
- Steep learning curve for beginners approaching complex tasks
- Limited native support for training deep learning models (better suited for inference and image processing)
Pricing: Free and open source (BSD license).

2. TensorFlow
Overview: TensorFlow is Google’s open-source deep learning framework and one of the most popular platforms for building and deploying computer vision models at scale. Its ecosystem includes the TensorFlow Object Detection API and KerasCV, both of which simplify computer vision tasks like image classification, object detection, and image segmentation. TensorFlow is well suited for production-ready vision applications and supports deployment across CPUs, GPUs, and edge devices. You can deploy a computer vision system across cloud, edge, and mobile environments for optimal performance.
Key Features:
- TensorFlow Object Detection API for training and deploying object detection models
- KerasCV for high-level computer vision model building
- TensorFlow Lite for deploying computer vision models on edge devices and mobile
- TensorFlow Lite is a lightweight implementation of TensorFlow designed for on-device machine learning with edge devices
- TensorBoard for experiment visualization and model performance tracking
- Support for large-scale distributed training
- Large community, extensive documentation, and tutorials
- Scalable for both research and enterprise-grade computer vision systems
Weaknesses:
- Higher learning curve compared to PyTorch for research and prototyping
- Debugging can be more complex than in eager execution frameworks
Pricing: Free and open source (Apache 2.0 license).

3. PyTorch
Overview: PyTorch, developed by Meta's AI research group, is a dynamic deep learning framework that has become the dominant choice for computer vision research and increasingly for production systems as well. Its dynamic computation graph offers greater flexibility when building custom deep learning models. TorchVision extends PyTorch specifically for computer vision, providing pretrained models, standard datasets, and image transformation utilities. PyTorch is also the foundation for many state-of-the-art computer vision tools including Detectron2 and SAM.
Key Features:
- Dynamic computation graph for flexible model building and easy debugging
- TorchVision: pretrained models for image classification, object detection, and segmentation
- Strong support for Vision Transformers (ViTs), CNNs, and custom model architectures
- Large research community and rapid adoption of state-of-the-art deep learning models
- GPU support and distributed training capabilities
- Integrates with tools like Detectron2, LightlyTrain, and Hugging Face
Weaknesses:
- Historically less optimized for production deployment compared to TensorFlow (gap has narrowed significantly)
- Larger model serialization and serving ecosystem requires additional tooling (TorchServe, ONNX export)
Pricing: Free and open source.
4. Keras
Overview: Keras is a high-level deep learning API built on top of TensorFlow, designed to simplify building and training neural networks for computer vision and other tasks. It provides a user-friendly, modular interface for assembling deep learning models quickly — making it particularly accessible for engineers new to deep learning, while remaining powerful enough for production use. Keras is included with TensorFlow 2.x and is widely used for image classification, object detection prototyping, and image segmentation workflows.
Key Features:
- Simple, readable API for building deep learning models rapidly
- Seamless integration with TensorFlow's full ecosystem
- Supports CNNs, ResNets, Vision Transformers, and other computer vision architectures
- Pre-built layers, loss functions, and optimizers for standard computer vision tasks
- Strong community support with over 400,000 individual users
- KerasCV extension for advanced computer vision pipelines
Weaknesses:
- Less flexible than raw TensorFlow or PyTorch for highly custom model architectures
- Abstracts away lower-level details that advanced researchers sometimes need access to
Pricing: Free and open source (included with TensorFlow).

5. Detectron2
Overview: Detectron2 is Meta AI Research's open-source deep learning platform for object detection and image segmentation, built on PyTorch. It is designed for both researchers testing novel machine learning models and developers deploying computer vision solutions at scale. Detectron2 supports a wide range of state-of-the-art architectures including Mask R-CNN, Faster R-CNN, and Panoptic FPN, making it a go-to framework for object detection and instance segmentation tasks.
Key Features:
- Supports Mask R-CNN, Faster R-CNN, RetinaNet, and Panoptic FPN architectures
- Modular design for easy customization and extension
- Strong performance on object detection and instance segmentation benchmarks
- Integrates with PyTorch and the broader Meta AI research ecosystem
- Actively maintained with support for the latest deep learning research
Weaknesses:
- Primarily optimized for Linux with GPU support; less straightforward on Windows
- Requires solid PyTorch knowledge; not beginner-friendly
Pricing: Free and open source (Apache 2.0 license).
2. Data Annotation & Labeling Tools for Building Computer Vision Models
High-quality labeled data is the fuel for supervised computer vision. Data annotation tools help machine learning engineers and labeling teams prepare datasets by annotating images or videos for tasks like object detection (bounding boxes), image segmentation (masks/polygons), image classification, and more. CVAT (Computer Vision Annotation Tool) is a powerful web-based tool for annotating images and videos, originally developed by Intel. Some annotation tools also support optical character recognition (OCR) for text extraction tasks.
In recent years, these tools have evolved significantly with AI-assisted labeling powered by foundation models like SAM 3 and YOLO11, collaborative workflows, and tighter integration with machine learning pipelines.
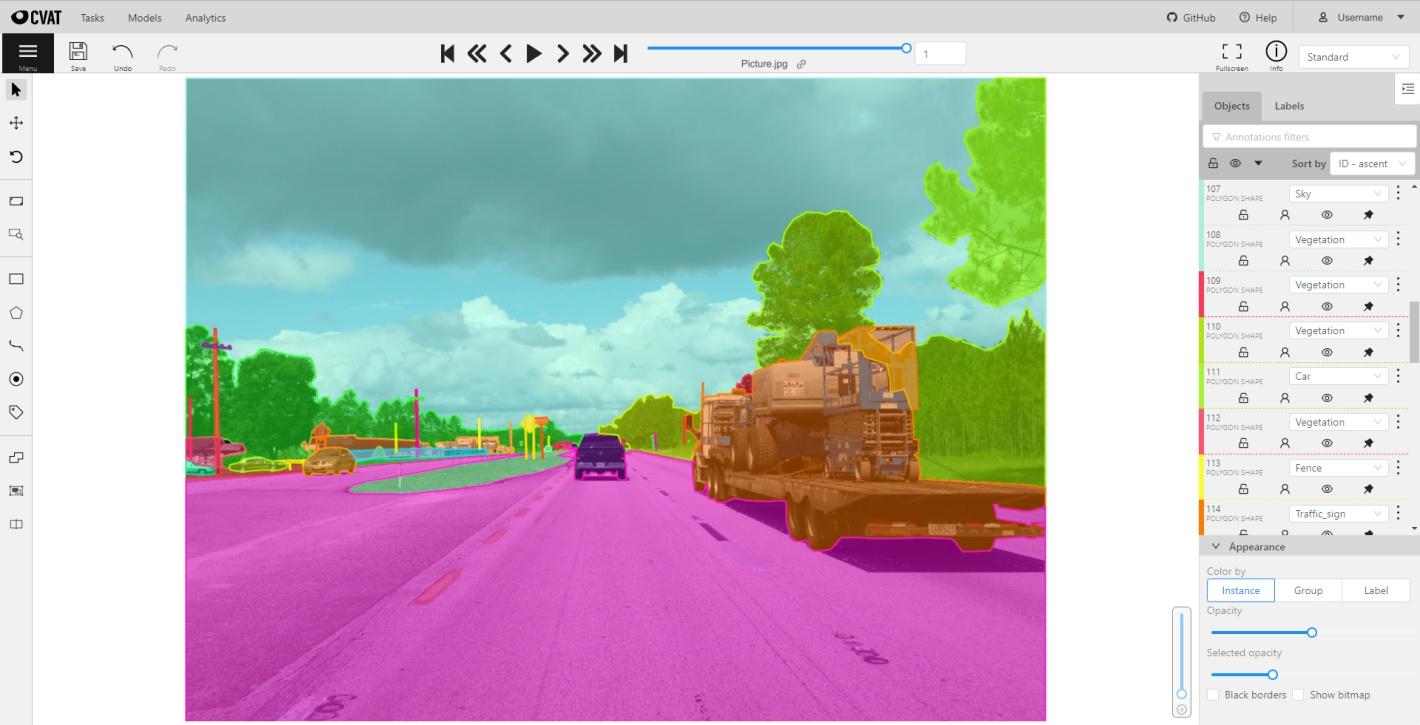
1. CVAT (Computer Vision Annotation Tool)
Overview: CVAT is an open-source annotation platform originally developed by Intel and now maintained by CVAT.ai as an independent company. Trusted by over 200,000 developers worldwide, it is popular in industry and academia due to its flexibility, active community, and the fact that it is free and open source.
What's new (2025–2026):
- SAM 3 integration (November 2025): interactive segmentation for images and video with fewer clicks
- Ultralytics YOLO auto-annotation (October 2025): fully automatic annotation using YOLOv5, YOLOv8, and YOLO11 via the CVAT AI agent
- 3D point cloud improvements: double-click to auto-center camera, standardized zoom, improved control point stability
- Analytics suite expansion: project-level analytics with Summary, Annotations, and Activity tabs
- Compliance: GDPR, CCPA, and EU AI Act compliant
Key Features:
- Image, video (with interpolation), and 3D point cloud annotation
- Object detection annotation with bounding boxes, polygons, keypoints, and masks
- Automatic and semi-automatic annotation with support for custom deep learning model integration
- REST API for CI/CD pipeline automation
- Available as self-hosted Community edition, managed SaaS (Online), or Enterprise
Weaknesses:
- Self-hosted version requires infrastructure maintenance
- UI has a learning curve, particularly for new users or complex annotation schemas
- Performance can degrade on very large or high-resolution datasets
Pricing: Free and open source (Community edition). CVAT Online offers a free tier; paid Solo ($33/month), Team ($66/month+), and Enterprise (~$12,000/year+) plans available.
2. Labelbox
Overview: Labelbox is a cloud-based annotation platform with a user-friendly interface and strong collaboration features. It supports images, videos, text, and geospatial data, making it well suited for enterprise machine learning teams building large-scale training datasets for object detection, image classification, and segmentation.
Key Features:
- AI-assisted labeling and active learning workflows (loop model predictions for review)
- Strong project management tools: review workflows, issue tracking, and integration with professional annotators
- Python SDK and API for seamless machine learning pipeline integration
- Integrations with AWS, GCP, and Azure
Weaknesses:
- Interface can become complex for advanced settings or very large ontologies
- Cloud-only storage may not be suitable if data privacy regulations prevent uploading images to third-party servers
Pricing: Free tier available; enterprise plans offer advanced features and support.

3. SuperAnnotate
Overview: SuperAnnotate is a collaborative annotation platform with a strong focus on quality control and automation. It supports bounding boxes, polygons, keypoints, and LiDAR data for object detection, image segmentation, and pose estimation workflows, with an optional managed workforce for hybrid labeling.
Key Features:
- Auto-annotation using machine learning models
- Built-in feedback loop for annotators to improve accuracy
- User-friendly interface with robust project management and QA tools
- Optional managed labeling workforce for capacity scaling
Weaknesses:
- Auto-segmentation can be less accurate on low-resolution or visually complex images
- Primarily suited to enterprise teams; pricing may be steep for smaller projects
Pricing: Free trial available; subscription plans for teams and enterprises.
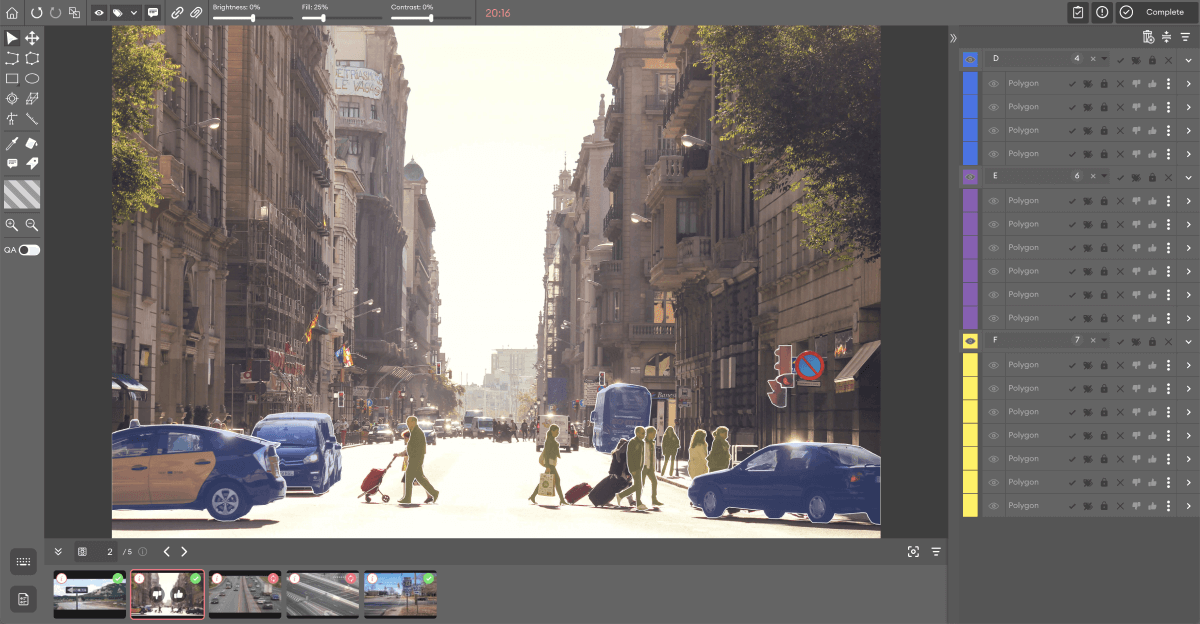
4. V7 (formerly V7 Darwin)
Overview: V7 is a powerful annotation platform with AI-assisted annotation for faster labeling. It is particularly strong for object detection and image segmentation tasks, with automated interpolation for video annotation and high-speed one-click segmentation powered by neural networks.
Key Features:
- Auto-Annotate: one-click object segmentation using neural networks
- Strong support for object detection workflows with bounding box annotation
- Workflow support for annotation review and quality assurance (QA)
- Python SDK and REST API for easy integration with cloud storage
Weaknesses:
- Limited flexibility in file handling — files must follow a provided dataset structure
- Web interface can occasionally be sluggish on very large datasets
Pricing: Contact V7 for pricing; enterprise features available.
5. Label Studio
Overview: Label Studio is a free and open source data labeling platform designed for flexible annotation workflows. It supports image classification, bounding boxes for object detection, polygons, keypoints, and segmentation masks — all from a browser-based interface. Label Studio is an essential tool for machine learning teams creating high-quality training datasets for supervised deep learning models.
Key Features:
- Supports image classification, object detection (bounding boxes), image segmentation, and keypoint annotation
- Browser-based interface with no installation required for the hosted version
- Integrates with machine learning pipelines for active learning and model-assisted labeling
- Supports a wide range of data types: images, video, audio, text, and time series
- Active community and strong documentation
Weaknesses:
- Enterprise features like RBAC, SSO, and advanced workflow automation require the paid tier
- Less polished UI compared to purpose-built enterprise annotation tools
Pricing: Free and open source (community version). Label Studio Enterprise available with paid plans.
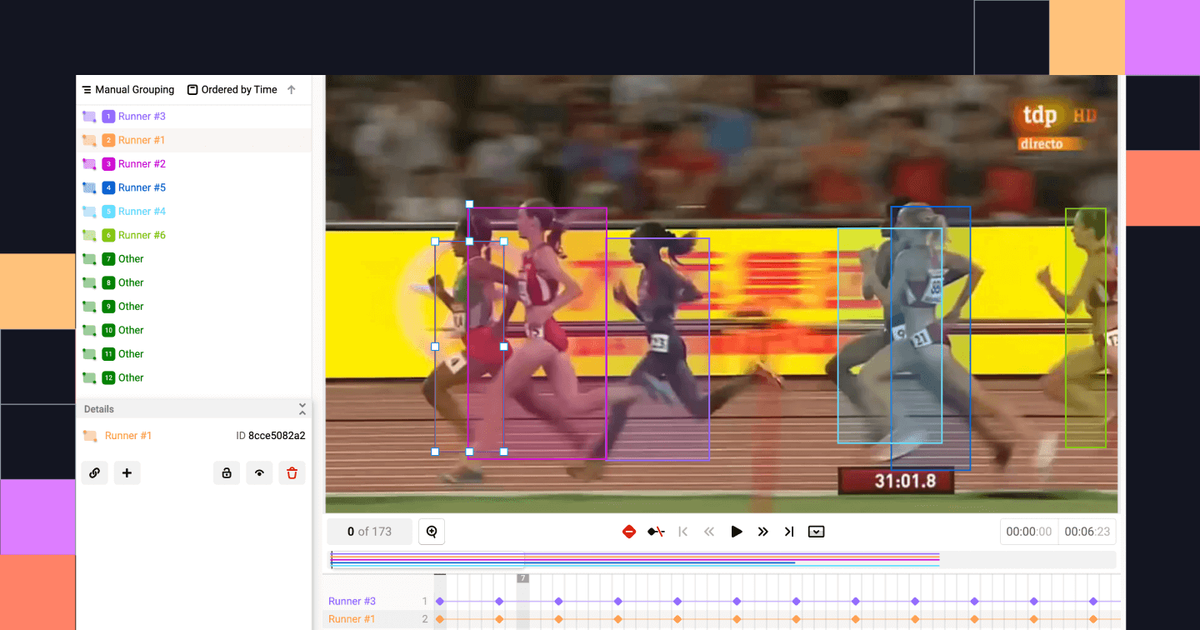
3. Data Curation & Dataset Management Tools
Curating high-quality datasets is essential for maximizing machine learning model performance. Data curation tools help machine learning teams select the most valuable data, identify mislabeled samples, and manage dataset versions. These tools prioritize quality over quantity, reducing annotation costs while improving model accuracy.
1. LightlyStudio
Overview: LightlyStudio is Lightly's curation and dataset management product, with built-in labeling for image and video workflows, plus on-prem deployment and enterprise controls. It is an essential tool for teams that want curation, selection, and annotation in one environment — removing the need to move data between separate tools.
LightlyStudio is built around a curation-first philosophy: before labeling anything, you understand your data. It uses self-supervised embeddings to cluster and explore datasets, surface edge cases, detect near-duplicates, and select the most informative samples for labeling.
Key Features:
- Unified curation and labeling: curate and annotate images and videos in a single platform
- Embedding-based data selection: uses self-supervised embeddings to ensure diverse, representative dataset coverage
- Active learning: identifies uncertain or high-value samples for efficient, targeted labeling
- Built-in annotation and QA: label and review images and videos directly within the platform
- Dataset version control and management: track changes, manage versions, and maintain data lineage across experiments
- High performance at scale: near-instant interactions on large datasets, powered by a DuckDB backend
- Python-first SDK: pip-installable, designed for integration into existing machine learning pipelines
- Flexible deployment: on-prem, hybrid, or cloud; enterprise deployment options available
- Open-source core: source-available and free to use locally
Weaknesses:
- Currently centered on image and video workflows; other modalities on the roadmap
- Built-in annotation tooling may not match the depth of dedicated labeling platforms for very high-volume operations
- Hosted cloud collaboration features are still maturing
Pricing: Free to use locally (open-source core). Enterprise cloud and on-prem plans available with custom pricing.
2. FiftyOne
Overview: FiftyOne is a free and open source dataset visualization and exploration tool for computer vision. It provides an interactive interface for analyzing datasets, filtering data, and comparing model predictions. With over 3 million installs and adoption across hundreds of Fortune 500 companies, it is a widely trusted companion tool for machine learning engineers.
What's new (2025–2026):
- Auto-Labeling Panel (December 2025): select and configure a model for label generation, generate labels using an orchestrator, then review and selectively approve results — all in-app
- Scenario Analysis in the Model Evaluation panel: deep-dive into model behavior across specific conditions
- Built-in annotation tools for 2D and 3D directly in the app
- Near-duplicate removal: automatically surface and remove duplicate or near-duplicate images for cleaner training datasets
Key Features:
- Dataset Visualization App: interactive UI for browsing, filtering, and analyzing datasets at scale
- Model evaluation: computes evaluation metrics, confusion matrices, and per-class analysis for object detection and image classification models
- Embeddings and similarity: nearest-neighbor searches to find related or anomalous images
- Dataset version control through integrations with tools like DVC
- Integration with COCO, VOC, YOLO, and other machine learning formats; integrates with CVAT and other annotation tools
Weaknesses:
- Built-in annotation is better suited to QA and correction than high-volume production labeling
- Free version requires local or server-based setup; no fully managed cloud option out of the box
Pricing: Free and open source. FiftyOne Enterprise available with paid collaboration features, managed hosting, RBAC, and advanced workflow automation.

4. Model Pretraining & Fine-tuning Frameworks
One of the most significant shifts in production computer vision since 2025 is the growing adoption of domain-specific pretraining. Generic ImageNet-pretrained weights are often a poor starting point for specialized industrial, medical, or autonomous driving tasks. The tools in this category make it practical for teams to train models efficiently on their own domain data — including through no-code model training options that emphasize ease of use and accessibility for beginners. Many no-code tools can handle small datasets effectively, often using techniques like transfer learning, making them suitable for rapid deployment in industrial or business applications — even without labels or deep learning expertise in self-supervised learning.
1. LightlyTrain
Overview: LightlyTrain is a framework for self-supervised pretraining, fine-tuning, distillation, and autolabeling on domain-specific visual data. It bridges the gap between generic pre-trained models and the domain-specific reality of production computer vision systems — essential tool that lets teams build stronger deep learning models using their own unlabeled data.
Key Features:
- No labels required: pretrain on your own unlabeled data using self-supervised learning (SSL) and knowledge distillation
- Wide architecture support: YOLO, RT-DETR, DINOv3, and more
- Supports object detection pretraining for architectures including YOLO, RT-DETR, and Faster R-CNN
- Autolabeling: generate pseudo-labels using DINOv2/DINOv3 pre-trained models to boost performance of smaller downstream computer vision models
- All-in-one deep learning workflow: pretraining → distillation → fine-tuning in one framework
- Smaller and faster custom models: PicoDet models for low-power embedded devices, with ONNX and TensorRT FP16 export support
- Fully on-premise: scales to millions of images; data stays in your infrastructure
- LightlyStudio integration: visualize annotations and predictions from LightlyTrain directly in LightlyStudio
Weaknesses:
- Some machine learning background is needed to configure the best pretraining setup for a specific domain
- Primarily optimized for visual data; not designed for NLP or audio tasks
Licensing: Free community license for students, researchers, and early-stage startups. AGPL-3.0 for open-source use. Commercial license available for production and proprietary workflows.
5. End-to-End Computer Vision Platforms
For larger projects or organizations, an integrated end-to-end platform can accelerate development by providing unified computer vision tools for the entire workflow — from data ingestion to training and deployment — with minimal stitching between stages. Viso Suite is an end-to-end computer vision platform that includes over 15 products for building, deploying, and monitoring computer vision applications. Modern end-to-end platforms increasingly integrate vision-language models, enabling multimodal AI systems that can understand both images and text for enterprise use cases.
1. Roboflow
Overview: Roboflow is a developer-friendly computer vision platform that streamlines dataset creation, labeling, model training, and deployment, serving over one million developers. It is particularly popular for object detection projects using the YOLO family of models, and supports one-click training with popular deep learning architectures.
What's new (2025–2026):
- Roboflow Instant: zero-shot auto-labeling using SAM and CLIP — no manual annotation needed before model training
- Workflows AI Assistant: natural language processing interface for building computer vision inference workflows
- YOLOv12 training and API deployment support
- Qwen2.5-VL integration for vision-language multimodal tasks
- Dataset health check: catches class imbalances and annotation errors before training begins
Key Features:
- Dataset management: supports 40+ annotation formats and automatic conversion tools
- Auto-annotation: uses pre-trained deep learning models to assist with labeling for object detection and image segmentation
- One-click model training: training on cloud or local machines with popular architectures (YOLO family, RT-DETR, and more)
- Deployment options: hosted API for inference or edge deployment for on-device computer vision models
- Developer integrations: Python API, notebooks, and compatibility with TensorFlow and PyTorch
- Roboflow Universe: large open-source dataset ecosystem for community sharing and reuse
Weaknesses:
- May require external customization for ultra-specific use cases
- Not optimized for large-scale research experiments compared to dedicated machine learning frameworks
- Costs scale quickly at high training and inference volumes
Pricing: Free tier for small-scale and public projects. Paid plans (Basic, Growth, Enterprise) for private data, larger datasets, and dedicated compute.

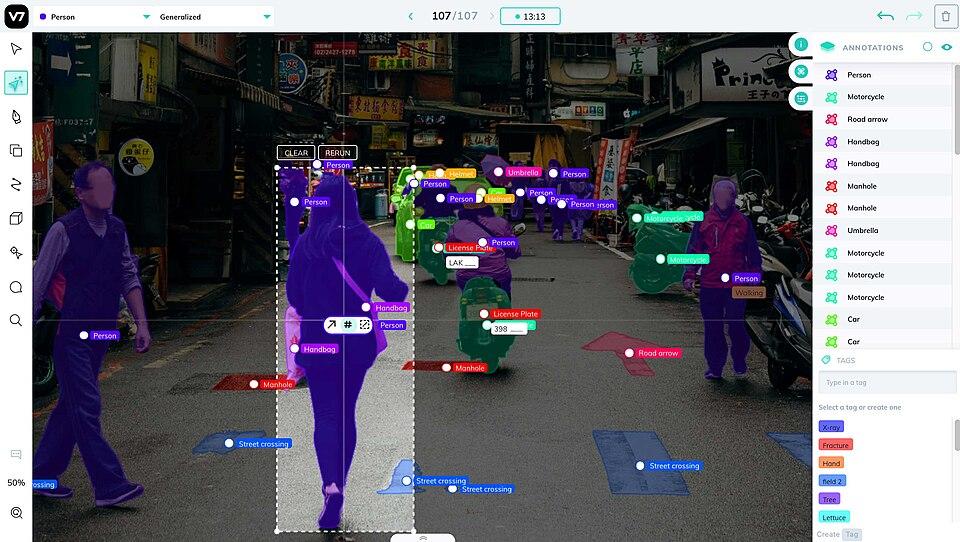
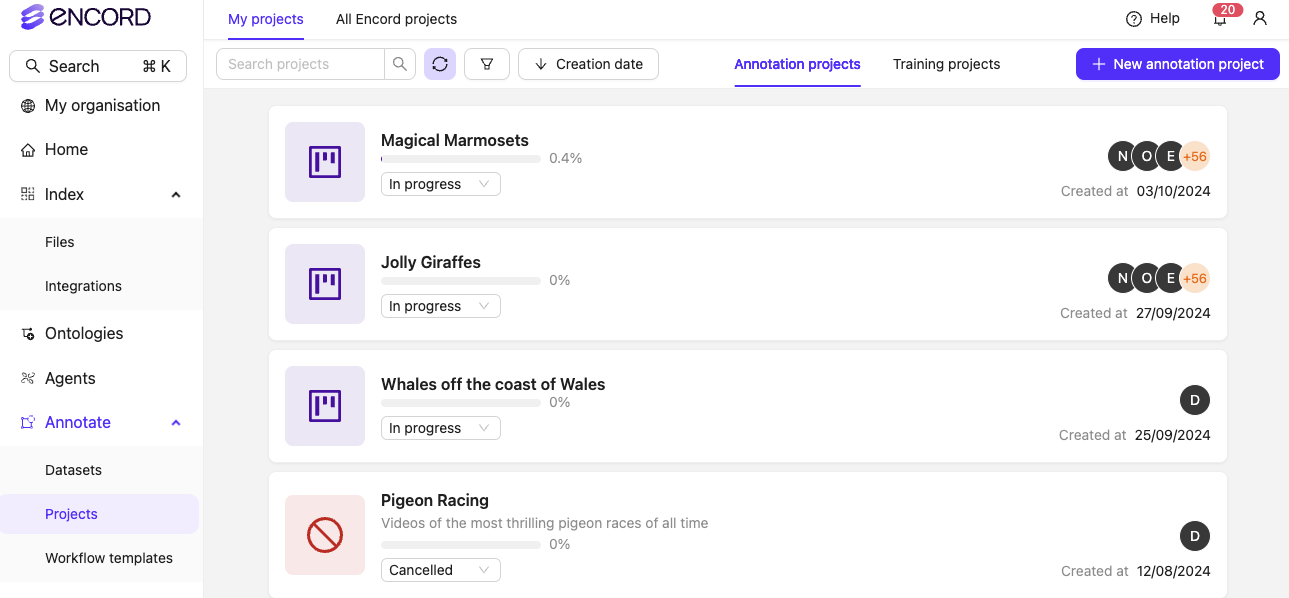
2. Encord
Overview: Encord is an enterprise-grade AI data platform designed for complex, multi-modal computer vision projects. It has raised $110M in total funding and counts Toyota, Skydio, and Maxar among its 300+ enterprise customers. In mid-2025, Encord launched a unified Physical AI suite purpose-built for robotics, autonomous vehicles, and ADAS development.
What's new (2025–2026):
- Physical AI suite (June 2025): unified platform for ingesting raw sensor data (LiDAR, radar, camera, MCAP), annotating 3D and multi-sensor scenes, and surfacing edge cases
- SAM 3 integration (Early Access): label all object instances simultaneously using text prompts or one-click class selection
- Data Groups (Beta): organize files into groups for multi-tile and multi-modal annotation workflows
- Series C funding (December 2025), bringing total raised to $110M
Key Features:
- Supports images, videos, audio, text, DICOM, LiDAR, and radar with diverse annotation types for object detection and segmentation
- AI-assisted labeling: SAM auto-segmentation, object tracking, interpolation, and single-shot scene labeling
- Customizable workflows with multi-stage review, QA, and team collaboration tools
- Active learning and model evaluation integrated into the annotation pipeline
- API and Python SDK for seamless machine learning pipeline integration
Weaknesses:
- Can experience latency with very large datasets or slower internet connections
- Enterprise pricing may not be accessible for smaller teams
Pricing: Contact Encord for pricing; enterprise and on-prem deployment options available.
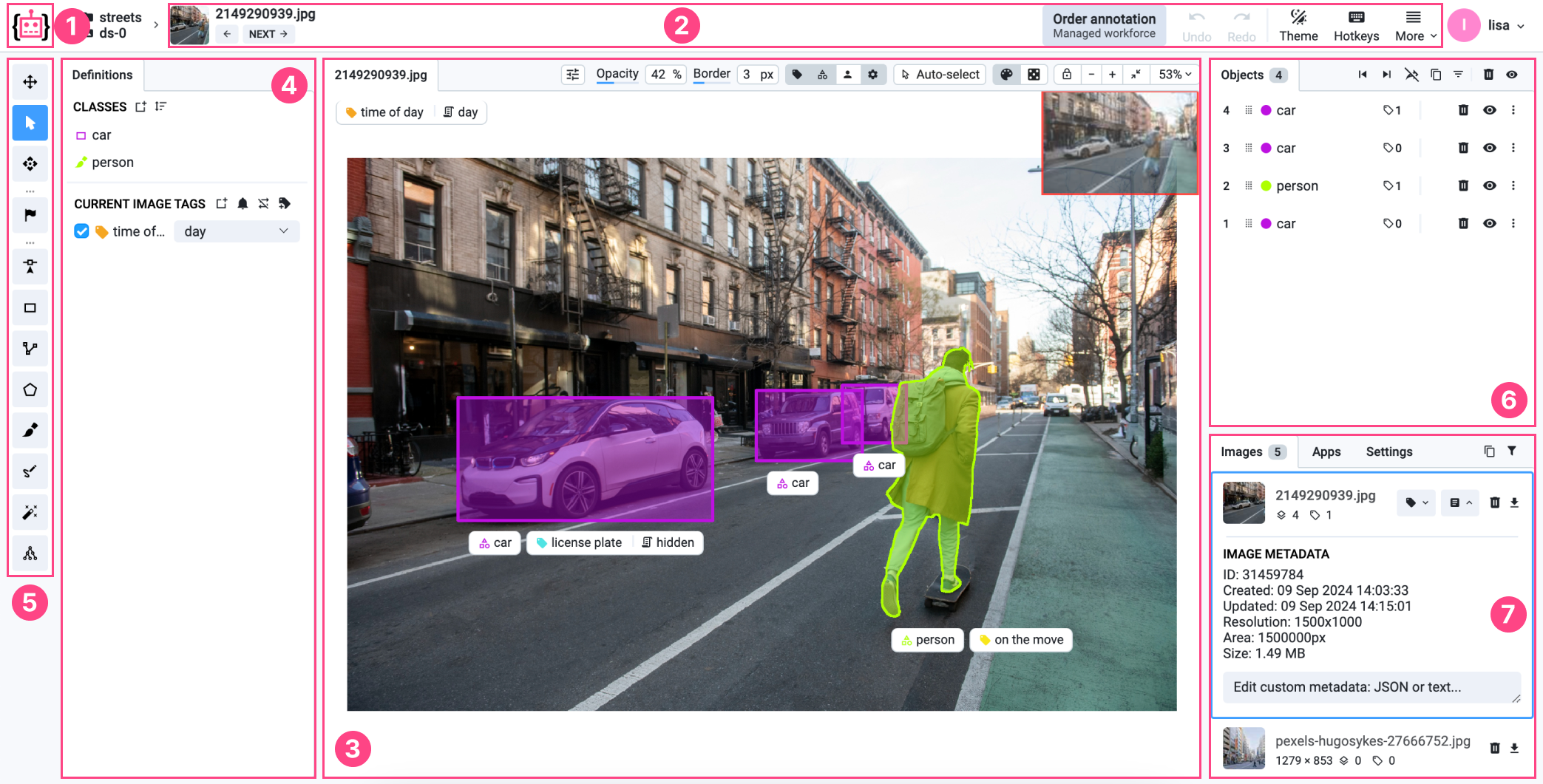
3. Supervisely
Overview: Supervisely is a comprehensive computer vision development platform designed as an "operating system" for AI projects. It supports data labeling, deep learning model training, experiment tracking, and deployment, with an emphasis on modular customization through its app ecosystem.
Key Features:
- Advanced annotation suite: supports images, video, 3D point clouds, and medical imagery (DICOM), with AI-assisted labeling for object detection and image segmentation
- Data curation and management: version-controlled datasets with analytics, quality assurance workflows, and role-based team collaboration
- Model training and evaluation: built-in training for popular deep learning architectures, error analysis, and comparison tools
- App ecosystem and customization: extend functionality with Python-based plugins for automation and custom computer vision workflows
- Deployment and integration: model serving, inference API, and enterprise-grade security with on-prem deployment options
Weaknesses:
- Primarily geared toward enterprise teams; may be overkill for small-scale projects
- High customization potential means a learning curve for new users
Pricing: Free community edition (self-hosted, limited features). Pro and Enterprise plans with cloud hosting and full feature access (custom pricing).
6. Experiment Tracking & MLOps Tools
Developing computer vision models is an iterative machine learning process that produces a large number of experiments, models, and metrics. Experiment tracking and MLOps tools help manage this complexity by logging results, organizing model versions, and facilitating model deployment pipelines. Most deep learning frameworks integrate with these tools out of the box.
1. Weights & Biases (W&B)
Overview: Weights & Biases is the most widely used AI developer platform for machine learning experiment tracking, model management, and — since 2025 — GenAI observability. It provides lightweight integration (just a few lines of code) to log metrics, loss curves, system metrics, model artifacts, and more from your deep learning training runs.
What's new (2025–2026):
- W&B Weave: a dedicated toolkit for building, evaluating, and monitoring GenAI applications and LLM agents
- Agent pre-training and monitoring: full support for pre-training, post-training, evaluation, and safeguarding of AI agents in production
- NVIDIA integrations: W&B Weave integrates with NVIDIA's NeMo Agent Toolkit, NeMo Microservices, BioNeMo, and Isaac Lab for robotics (announced at GTC 2026)
- iOS app: monitor training runs and experiment metrics from mobile
- Compliance: ISO/IEC 27001:2022, SOC 2, and HIPAA certified
Key Features:
- Experiment tracking dashboards: auto-logs metrics, hyperparameters, and system info for easy comparison across computer vision model training runs
- Artifact and model management: versioning for datasets, model checkpoints, and training lineage
- Collaboration and reports: interactive reports, team tagging, and alerts
- Hyperparameter tuning: built-in Sweeps feature for automated hyperparameter optimization
- Model performance monitoring over time with GitHub integration for reproducibility
Weaknesses:
- SaaS-based, meaning sensitive data is stored in the cloud (on-prem version available for enterprises)
- Can feel heavyweight for small experiments or individual contributors
Pricing: Free tier for individuals and academics. Paid Pro and Enterprise plans available.

2. ClearML
Overview: ClearML is a free and open source MLOps platform for experiment tracking, dataset management, and pipeline orchestration. It offers flexibility through self-hosting while automating machine learning workflows for computer vision teams.
Key Features:
- Experiment tracking: auto-logs metrics, hyperparameters, git commits, and system environments for deep learning training runs
- Dataset management and version control: track changes to training data alongside model experiments
- Pipeline orchestration: automates workflows, scheduling tasks on compute clusters
- Scalability and teamwork: role-based access, team collaboration, and cost-effective self-hosting
- Extensibility: open-source with REST API and Python SDK for customization
Weaknesses:
- UI is less polished than W&B for metrics visualization
- Requires infrastructure setup for self-hosting, though a hosted version is available
Pricing: Free and open source version. Enterprise plan with priority support and hosted SaaS option available (pricing on request).
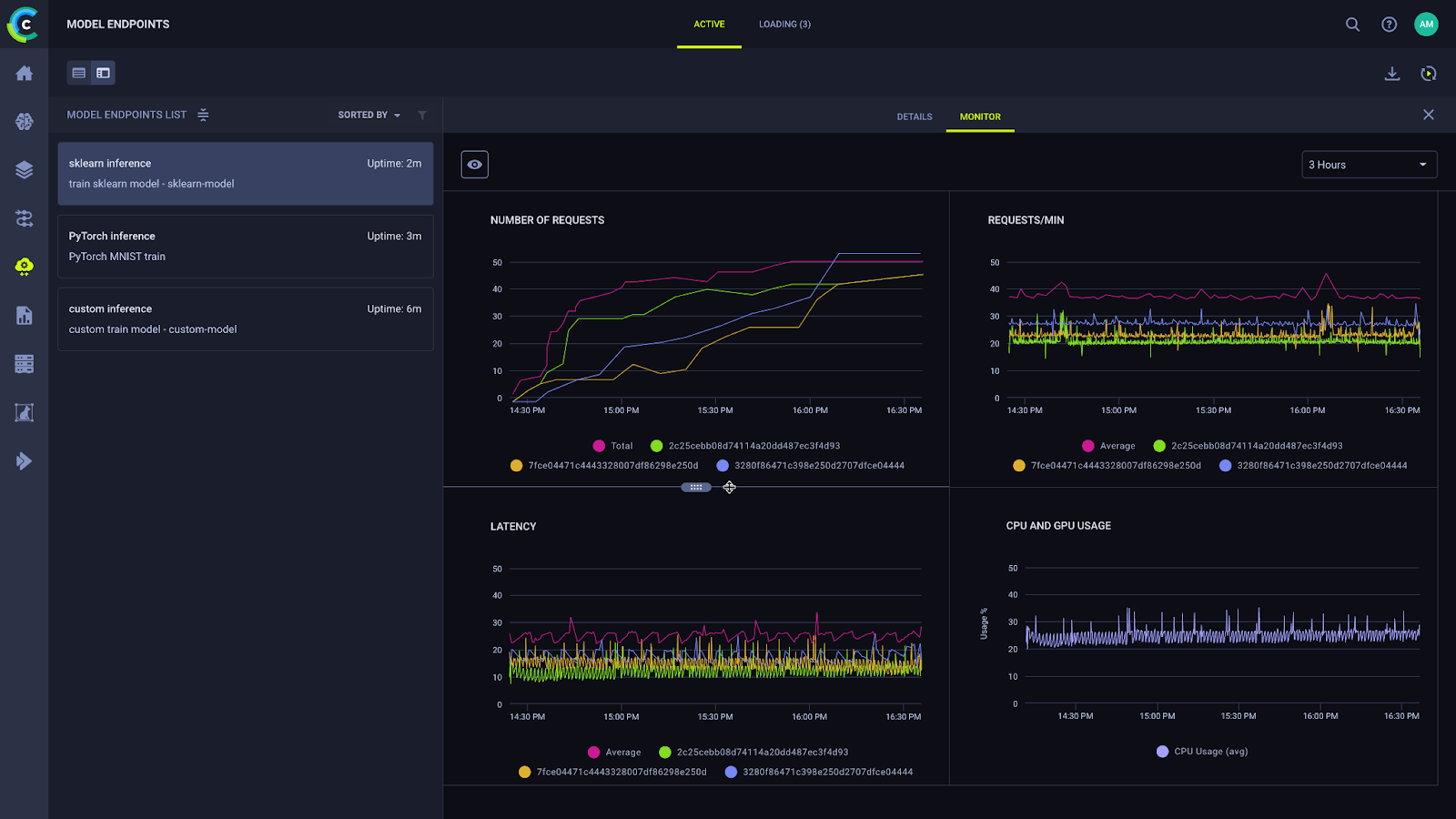
3. MLflow
Overview: MLflow is a free and open source platform developed by Databricks for experiment tracking, model registry, and deployment, widely adopted across the machine learning community for managing the deep learning lifecycle in computer vision projects.
Key Features:
- Experiment tracking: logs parameters, metrics, and artifacts, supporting Python, R, and CLI
- Model registry: centralized model versioning with staging and CI/CD triggers
- Model packaging: standardized format for deploying computer vision models across environments
- Integration with cloud and Databricks: native support for cloud machine learning services and Databricks
Weaknesses:
- UI is basic compared to W&B
- No built-in hyperparameter tuning or pipeline orchestration (needs tools like Airflow or Prefect)
Pricing: Free and open source with self-hosting options. Available as a managed service via Databricks and cloud providers (pricing varies).

How to Choose the Right Computer Vision Tools for Your Machine Learning Project
With so many computer vision solutions available, finding the right ones can feel overwhelming. Here's a 3-step process to help you clarify your needs.
1. Start with libraries and frameworks, then add platforms
Start by distinguishing between libraries/frameworks and platforms. If you need to build custom deep learning models from scratch, start with a framework like PyTorch or TensorFlow, and use OpenCV for image processing and pre/post-processing pipelines. If you need to annotate data, manage datasets, or deploy computer vision models without writing low-level code, the annotation and end-to-end platforms in this guide are more appropriate.
Most production computer vision teams use both — a deep learning framework for model development, and one or two specialized platforms for data management and MLOps.
If you have large volumes of unlabeled data and want to reduce annotation costs, start with curation-first tooling like LightlyStudio — selecting only the most informative samples before labeling can dramatically reduce cost and improve model performance. If domain performance is a bottleneck, LightlyTrain offers a path to stronger custom models using your own unlabeled data.
2. Consider integration with your workflow
Audit your current computer vision tools stack.
If you're heavily using PyTorch or TensorFlow, tools with Python SDKs (Labelbox, FiftyOne, Lightly, W&B, etc.) will fit more naturally. If your organization is already on AWS, Azure, or GCP, cloud-native tools will minimize friction. Ensure your chosen computer vision tools can import and export in the formats you use (COCO JSON, YOLO TXT, TFRecord, etc.).
3. Check for data privacy and compliance
If you're working with sensitive data (medical images, proprietary product images, etc.), consider where your data will reside. Tools like OpenCV, CVAT, LightlyStudio, and Supervisely (self-hosted) keep data on-prem, while cloud services will require uploading data. Some cloud platforms allow choosing data residency or offer on-prem versions. Make sure the tool aligns with your organization's policies and any applicable regulations (GDPR, HIPAA, EU AI Act, etc.).
Frequently Asked Questions
What are the best computer vision tools for ML engineers in 2026?
The best computer vision tools depend on your use case. For foundational deep learning model development, PyTorch and TensorFlow are the leading frameworks, with OpenCV as the standard library for image processing. For data annotation, CVAT, Labelbox, and V7 are widely used. For dataset curation, LightlyStudio and FiftyOne are popular choices among machine learning engineers. For end-to-end computer vision workflows, Roboflow, Encord, and Supervisely offer integrated platforms covering annotation through deployment.
Which computer vision tools are free and open source?
Several strong computer vision tools are free and open source, including OpenCV, TensorFlow, PyTorch, Keras, Detectron2, CVAT, Label Studio, FiftyOne, LightlyStudio (local), ClearML, and MLflow. These tools cover the full stack from deep learning frameworks and image processing libraries to annotation, dataset visualization, MLOps, and experiment tracking.
What is object detection and which tools support it?
Object detection is a computer vision task where a deep learning model identifies and localizes objects within an image using bounding boxes. Most tools in this guide support object detection workflows. For model development, TensorFlow's Object Detection API, PyTorch with Detectron2, and OpenCV all support object detection pipelines. For annotation, CVAT, Roboflow, V7, and Labelbox offer strong native support. For pretraining object detection models on domain-specific data, LightlyTrain supports architectures including YOLO, RT-DETR, and Faster R-CNN.
What is the difference between a computer vision library and a computer vision platform?
A computer vision library or framework (like OpenCV, TensorFlow, or PyTorch) provides the low-level building blocks for writing custom deep learning models and image processing pipelines. A computer vision platform (like Roboflow, Encord, or Supervisely) provides a higher-level interface for the full workflow — annotation, dataset management, model training, and deployment — without requiring you to write everything from scratch. Most production computer vision teams use both.
What is the difference between data annotation and data curation?
Data annotation involves labeling images or videos with bounding boxes, polygons, or keypoints so machine learning models can learn from them. Data curation involves selecting the most valuable and diverse samples from a larger dataset before annotation — reducing cost and improving model performance. Tools like LightlyStudio and FiftyOne specialize in curation, while CVAT, Labelbox, and V7 focus on annotation.
How do I choose the right computer vision tools for my project?
Start by defining your computer vision tasks — object detection, image classification, image segmentation, or video analysis. Then consider your team size, data volume, deployment environment, and data privacy requirements. Choose a deep learning framework (PyTorch or TensorFlow) as your foundation, add OpenCV for image processing, then layer in annotation, curation, and MLOps tools based on your pipeline needs. Most production computer vision teams use two to three complementary tools.
Conclusion
The computer vision tooling landscape in 2026 is more capable and more interconnected than at any point before. Deep learning has fundamentally changed what computer vision systems can achieve, and the tools in this guide reflect that shift. Whether you're building industrial vision systems, medical imaging pipelines, or autonomous vehicle perception stacks, the right combination of libraries, frameworks, and platforms determines how fast and how well you can ship.
The dominant trend is convergence: curation, labeling, pretraining, and deployment are collapsing into tighter, more integrated workflows. Meanwhile, foundational libraries like OpenCV remain indispensable for real-time image processing, and deep learning frameworks like PyTorch and TensorFlow continue to drive state-of-the-art computer vision model performance.
Selecting the right tools depends on your task complexity, dataset scale, annotation requirements, deployment environment, and data governance constraints. Most production computer vision teams use two or three complementary tools. There is no single right answer — but the options in this guide represent the strongest available choices as of April 2026.
If you've used a tool that significantly improved your computer vision pipeline, let us know — we'll keep this guide updated with the best options.
Computer Vision Applications
Computer vision applications are transforming industries by enabling machines to interpret and understand visual data with unprecedented accuracy. Powered by advances in deep learning models and sophisticated vision tools, computer vision technology is now at the core of solutions ranging from image classification and object detection to facial recognition and automated visual inspection. These applications leverage the latest computer vision algorithms and model training techniques to solve complex real-world problems, making processes faster, more reliable, and scalable. Whether it’s automating quality control in manufacturing, enhancing security through facial recognition, or enabling new forms of human-computer interaction, computer vision applications are driving innovation across sectors and redefining what’s possible with digital images and video.
Autonomous Vehicles
Autonomous vehicles are among the most advanced and high-stakes computer vision applications today. These vehicles depend on a suite of computer vision tasks—including object detection, image segmentation, and scene understanding—to safely navigate complex environments. By processing visual inputs from cameras and other sensors, deep learning models can identify obstacles, interpret traffic signs, and anticipate the actions of pedestrians and other vehicles. The use of pre-trained models and neural network optimization ensures that these systems can operate in real time, adapting to new scenarios and improving safety. Cutting-edge computer vision algorithms, combined with robust deep learning frameworks, enable autonomous vehicles to make split-second decisions, bringing us closer to fully self-driving transportation.
Visual Inspection
Visual inspection is a critical application of computer vision in sectors such as manufacturing, quality control, and medical imaging. Here, computer vision models are trained to analyze digital images for defects, anomalies, or specific features, automating what was once a manual and error-prone process. Techniques like instance segmentation and object recognition allow for precise identification and classification of objects within images, ensuring high standards in quality control and diagnostics. The seamless integration of computer vision technology with existing tools and industrial machinery enables real-time, automated visual inspection, reducing costs and improving accuracy across a wide range of applications—from detecting flaws in assembly lines to analyzing medical scans for early disease detection.
Edge Devices: How Computer Vision Enables Machines to See
Edge devices, including smart cameras, autonomous robots, and IoT sensors, are increasingly leveraging computer vision to process visual data directly on-device. By running optimized computer vision algorithms and custom models locally, these devices can perform real-time object detection, pose estimation, and facial recognition without relying on cloud connectivity. This approach reduces latency, enhances privacy, and enables responsive computer vision applications in environments with limited bandwidth or strict security requirements. Advanced object detection techniques and the development of lightweight, efficient models have expanded the capabilities of edge devices, making them ideal for applications such as augmented reality, surveillance, smart home automation, and industrial monitoring. Effective access management and strong community support are essential for deploying and maintaining these systems, ensuring secure and reliable operation at the edge.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


