
Knowledge Distillation: Compressing Large Models into Efficient Learners
Table of contents
Share blog post



Knowledge distillation compresses large models into smaller ones by training a student to match a teacher’s outputs. It enables fast, lightweight deployment on limited hardware with minimal accuracy loss and supports vision, language, and multi-teacher use cases.
Share blog post
Here’s a quick overview of key information about Knowledge Distillation and its importance.
- What is knowledge distillation?
It’s a model compression technique where a large teacher model transfers its knowledge to a smaller student model. The student is trained to mimic the teacher’s outputs (often the teacher’s probability distribution across all classes, known as soft targets) so that the smaller model achieves similar performance to the large model.
- How does knowledge distillation work?
The teacher-student framework involves first training a complex teacher network (e.g. a deep neural network with many parameters). Then the student network is trained on the same task, but instead of learning only from ground-truth labels, it learns to match the teacher model’s predictions (soft probabilities over classes). A special distillation loss (e.g. Kullback–Leibler divergence between the teacher and student outputs) is used alongside the regular loss to align the student’s outputs with the teacher’s.
- Why use knowledge distillation?
Knowledge distillation enables taking a large, accurate model and producing a smaller model that is faster, lighter, and suitable for deployment on resource-constrained devices (like mobile phones or embedded systems) – all while retaining close to the original accuracy. It is a form of knowledge transfer or knowledge compression that allows deep learning models to be used in real-time applications and embedded AI without heavy compute costs.
- Where is it applied?
Originally applied in computer vision (e.g. image classification, recognition) and later in natural language processing, knowledge distillation is now common whenever we need to compress large and complex models. For example, big vision models or large language models can be distilled into smaller ones for faster inference. It’s useful in scenarios like deploying AI on smartphones, IoT devices, or leveraging an ensemble of models as a single compact model.
- Are there different types or techniques?
Yes. Knowledge distillation can be done in various ways: offline vs. online distillation (whether the teacher is fixed or co-trained), self-distillation (the model teaches itself via its own layers), and using multiple teacher models (an ensemble of teachers) or even cross-modal distillation (teacher and student on different data modalities). There are also different forms of “knowledge” that can be distilled – e.g. distilling final outputs (response-based), intermediate feature maps (feature-based), or relationships between examples (relation-based). We’ll explore all these in detail below.
Modern deep learning models often achieve state-of-the-art performance at the cost of massive computational resources, making them impractical for real-time or edge deployment.
Knowledge distillation addresses this by transferring the capabilities of large models into smaller, efficient ones without significant loss in accuracy.
In this article we’ll explore:
- What is Knowledge Distillation?
- How does Knowledge Distillation work?
- Types of Knowledge Distillation
- Knowledge Distillation Training Schemes
- Application of Knowledge Distillation in Computer Vision
- Benefits, Challenges and best practices
- Conclusion and Future Outlook
And if you're curious about hands-on experimentation with knowledge distillation in computer vision, consider exploring LightlyTrain.
It enables you to pretrain vision models like DINOv2 on your own unlabeled data using self-supervised learning.
What is Knowledge Distillation?
Knowledge distillation is a model compression and knowledge transfer mechanism in which a large model (teacher) transfers the “knowledge” it has learned to a smaller model (student). The core idea popularized by Hinton et al. (2015) is that a compact (or rather smaller) model can be trained to reproduce the behavior and performance of a more complex model.
In essence:
- The teacher model is a high-capacity (larger) network that has been trained on a large dataset and achieves high accuracy. It encapsulates rich knowledge about the data (learned representations, class relationships, etc.) and exhibits some form of general knowledge capabilities.
- The student model is a smaller, faster model (fewer model parameters, simpler architecture, therefore faster inference times) that we want to actually deploy. On its own, due to its limited capacity, it might not reach the accuracy of the teacher if trained conventionally.
- Knowledge distillation bridges this gap by training the student using information from the teacher. Instead of training the small model from scratch only on the original training data, the student is trained to mimic the outputs of the teacher model (this is the “distillation” process).
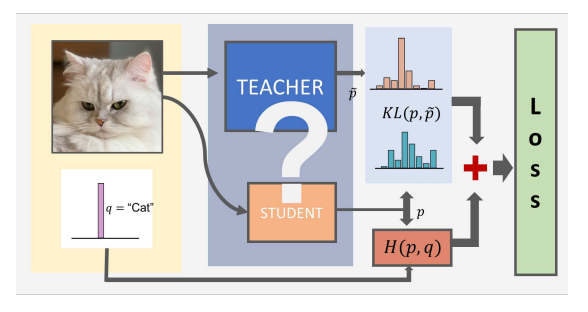
Key characteristics and goals:
- Model Compression: Knowledge distillation retains the accuracy of a larger model while drastically reducing the model’s size and complexity.
- Teacher–Student Framework: The process requires a pretrained teacher model and a student model. They might be the same type of model but can differ in size or even architecture.
- Mimicking Behavior: Rather than just learning from ground-truth labels, the student model learns to reproduce the teacher model’s output behavior – typically the teacher’s output probability distribution for each input sample.
- Soft Targets vs Hard Targets: In classical training, the model learns from hard labels (the one-hot correct class labels). In distillation however the teacher provides soft targets – instead of labels from the dataset we consider the predicted probabilities from the teacher model as labels. These soft targets contain extra information: they tell us not just the correct class, but how the teacher model relates the classes.
Preserving Performance: The goal is usually to have the student model’s accuracy approach (or sometimes even exceed) the teacher’s accuracy. A well-executed distillation can yield a model that’s far more efficient in terms of speed and memory, with only a minor drop in accuracy from the teacher model – if any.
💡Pro Tip: Before deciding whether to distill or fully retrain large models, our NVIDIA B200 vs H100 article provides practical insights into when newer GPUs can offset the need for aggressive compression.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
How Does Knowledge Distillation Work?
At a high level, the knowledge distillation training process involves two stages: (1) Training the teacher (if not already trained), and (2) Training the student with the teacher’s guidance. Let’s break down the typical workflow and core components:
1. Train the Teacher Model: First, you need a trained teacher model. This is often a large deep neural network (or an ensemble of models) that has high accuracy on the task. In many cases, the teacher is a pretrained model (possibly even a proprietary model or an ensemble used as a reference).
2. Obtain the Teacher’s Predictions (Soft Targets): For each example in the training set you run the input through the teacher model to get its output probabilities for each sample. These then become the soft targets or teacher’s probability distribution over classes. For example, if the task is image recognition with classes {cat, dog, rabbit}, the teacher might output [0.85, 0.10, 0.05] for a cat image.
3. Train the Student Model: The student model is then trained using a combination of:
3.1 Original Training Data & Labels: The student still learns from the true labels (hard targets) via a normal supervised loss (e.g. cross-entropy)
3.2 Teacher’s Soft Targets: In addition, the student learns from the teacher’s output distribution. We add a distillation loss term that measures how well the student’s output matches the teacher’s output for each training example. This loss encourages the student to reproduce the teacher’s probability distribution, not just get the correct output.
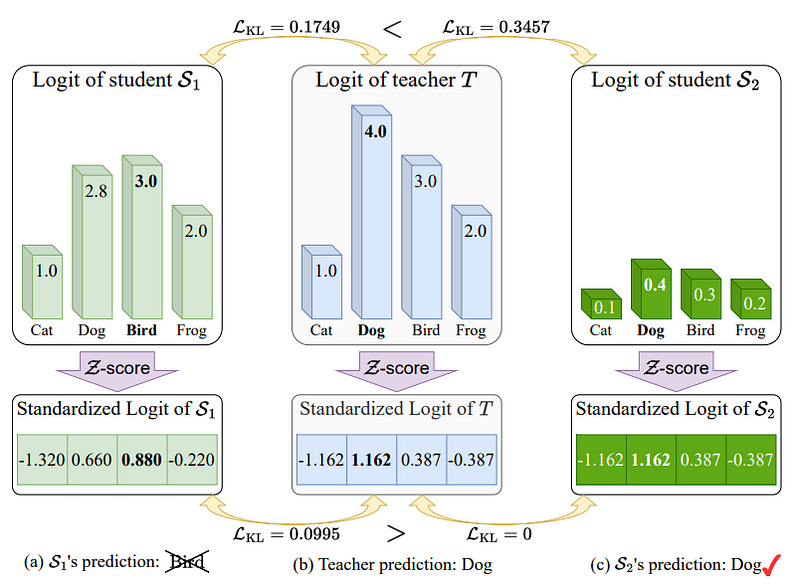
3.3 Temperature Scaling: A detail introduced by Hinton et al.(2015) is the use of a temperature (T) term to soften the probability distribution. By using a higher temperature in the softmax of the teacher and student, the probability distribution is smoothened (the highest probabilities are lowered and the smaller probabilities are raised). This emphasizes the relative probabilities of all classes. The student is trained to match these softened distributions. A higher temperature value puts more weight on matching the teacher’s full distribution (when T=1, it’s the normal softmax probabilities).
3.4 Loss Function: Typically, the total loss for training the student is a weighted sum of the distillation loss and the standard task loss (with hard labels). For example:
Loss = α (Distillation_Loss_KL) + (1−α) (Hard_Label_Loss)
where α is a weight (and sometimes the distillation loss itself includes 1/T² factor depending on formulation). This way, the student learns to balance mimicking the teacher by actually fitting to the true labels.
4. Result – The Distilled Student: After training, we get the distilled student model. It should ideally perform nearly as well as the teacher on the validation/test set. The student model is much smaller in size (fewer parameters, lighter architecture) and yields faster inference.
Why does this work?
Intuitively, the teacher’s soft targets provide richer information compared to just labels. The student doesn’t just learn what the correct answer is, but also how the teacher would "grade" each possible answer.
This helps the student model in two ways.
It provides additional training signals for the student model, especially for those samples where the teacher is very confident or where classes are confusing. It acts as a form of regularization. By mimicking a stronger model, the student’s learning is guided towards a solution that generalizes similarly to the teacher.
In practice, knowledge distillation has been shown to improve student model generalization and even achieve higher accuracy than training the small model on data alone. This distillation process is especially powerful when you have a very large teacher model and a significantly smaller student model.
💡Pro Tip: When compressing large detection models, our DETR guide provides a concrete example of the end-to-end architectures that are commonly used as teacher models.
Types of Knowledge Distillation
Not all knowledge from the teacher has to come from the final output probabilities. The three primary ways of transferring knowledge.
Response-Based Knowledge Distillation
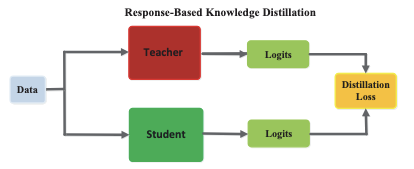
This technique focuses on the final output layer of the teacher model – essentially the teacher’s predicted probabilities. The student is trained to match these output responses of the teacher. This approach treats the teacher as a “black box” that provides answers, and the student learns to imitate those answers.
Feature-Based Knowledge Distillation
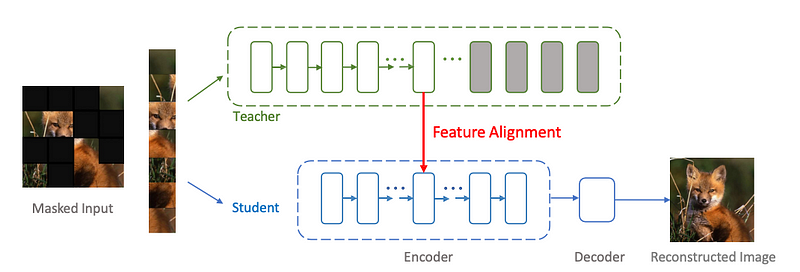
Instead of only looking at outputs, feature-based methods transfer knowledge from the intermediate layers (hidden layers) of the teacher to the student. The idea is that the teacher’s layers learn rich feature representations of the data. We can guide the student to learn similar feature maps in its own layers.
Typically, you choose certain layers of the teacher and student (e.g., each block or at corresponding depths) and add a loss term that penalizes the difference between the student’s feature activations and the teacher’s for the same input. This way the student not only matches outputs but also internal representations, which can lead to better learning of the task-specific features.
Relation-Based Knowledge Distillation
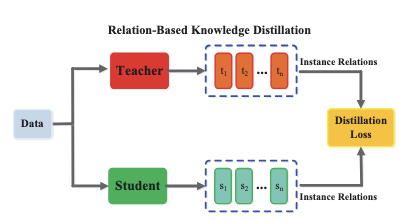
Relation-based methods go one step further by distilling the relationships between multiple activations or data samples from teacher to student. Instead of individual outputs or features, the knowledge here could be, for instance, the pairwise distances between examples in the teacher’s feature space, or the teacher’s attention maps capturing interactions between parts of an input.
Other forms include capturing structural knowledge: e.g., in a teacher Transformer model, which tokens attend to which (the attention matrix) can be seen as relational knowledge; a student Transformer can be trained to have similar attention patterns (this has been explored in NLP distillation).
Knowledge Distillation Training Schemes
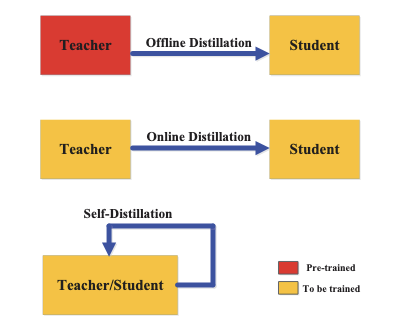
There are several ways to orchestrate the training of teacher and student models. The original approach by Hinton is often termed offline distillation, but other schemes like online and self-distillation have emerged.
💡Pro Tip: When deciding whether to pretrain or fine-tune a student model, our Pretraining vs. Fine-tuning article explains how the choice directly affects how much knowledge can be transferred during distillation.
Offline Distillation
Offline distillation means the teacher model is already trained on a task and then kept fixed (its model weights are frozen during student training). The student is trained using the static teacher’s knowledge. This requires having access to a good teacher model beforehand.
Online Distillation
In some cases, you might not have a pretrained teacher, or you want the teacher to adapt during training. Online distillation involves training the teacher and student simultaneously in a coupled manner. Sometimes two models (one large, one small) are trained together on the same task. The large one acts as a teacher for the small one on the fly — at each iteration or epoch, the big model’s current predictions teach the small student model.
Online distillation is useful if a strong teacher is not readily available or to avoid having to train a giant model first. For example, in scenarios of continual learning or streaming data, an online approach might continuously transfer knowledge from a slowly improving teacher into a small student for real-time use.
Applications of Knowledge Distillation in Computer Vision (and Beyond)
In computer vision, state-of-the-art machine learning models for tasks like image classification, object detection, and semantic segmentation are often extremely large.
Distillation allows us to compress these large vision models while keeping high performance. Some common scenarios:
- Image Classification: Distilling a high-accuracy classification model into a smaller network is very common. For example, distilling a large ResNet-152 or EfficientNet teacher into a smaller ResNet-50 or MobileNet student.
- Object Detection: Models like Faster R-CNN or YOLO in their top-performant versions can be heavy. Distillation is used to train a lightweight object detector (student) using a heavier detector or an ensemble as a teacher.
- Semantic Segmentation: Large segmentation models (which classify each pixel into a category) can be distilled into smaller models. The teacher might be a slow but accurate segmentation model that produces high-quality per-pixel class probability maps.
- Knowledge Distillation for Vision Transformers: Recently, transformer-based vision model are distilled into smaller transformers.
Pro Tip:To make transformer-based detectors more deployment-friendly, our DETR guide explains how end-to-end architectures can later be distilled into smaller, efficient student models.
Knowledge Distillation in NLP and Other Domains
- Natural Language Processing (NLP): Large language models (LLMs) and large NLP classifiers have benefited hugely from distillation. For example, DistilBERT is a famous distilled version of BERT (a large Transformer model for language) that is ~40% smaller and 60% faster while retaining about 97% of BERT’s performance on language understanding tasks. This was achieved by distilling BERT into a smaller 6-layer student model.
- Speech Recognition: KD has been applied to acoustic models and speech recognition networks to reduce their size.
- Model Ensembles: Another application: distilling an ensemble of many machine learning models into one. Instead of deploying 5 different models and averaging their outputs (which is slow), you can train a single student model to mimic the ensemble’s output.
Cross-Modal and Multi-Task Learning: As mentioned, KD is used in multi-modal systems (vision→ text, audio→ video, etc.) and also for multi-task scenarios (a teacher performing multiple tasks can teach a student to do the same, transferring holistic knowledge).
Benefits, Challenges, and Best Practices in Knowledge Distillation
Like any technique, knowledge distillation comes with its set of advantages, challenges, and tricks to get the best results. Here we outline some key points:
Benefits of Knowledge Distillation
Here are some key benefits:
- Reduction in Model Capacity: The obvious benefit – drastically reduce model size and inference latency while mostly preserving accuracy. This bridges the gap between research models and production deployment constraints.
- Regularization & Generalization: The student often generalizes better than a similarly sized model trained from scratch. The soft target training acts as a form of regularization or knowledge shaping. The teacher’s outputs can be thought of as providing a smoother error landscape for the student to learn from, rather than the sometimes harsh signal of one-hot labels.
- Knowledge Transfer: KD allows transfer learning in a broader sense: e.g., transferring knowledge from one architecture to another, one modality to another, or one domain to another (with caution). It’s a flexible paradigm – as long as you can get teacher predictions for an input, you can train a student on that input, even if the student’s model class is different.
Challenges and Limitations
Finally, here are some limitations of knowledge distillation.
- Student Capacity: The student model needs to have enough capacity to absorb the teacher’s knowledge. If the student model is too small relative to the complexity of the task, no amount of distillation will make it reach the teacher’s performance (you can’t pour a gallon into a cup).
- Choosing the Temperature and Loss Weights: Hyperparameters like the temperature (T) for softening distributions and the weight α between distillation loss and true label loss need tuning. The weight α controls how much emphasis on matching teacher vs fitting ground truth; if α is too high and the teacher model is not perfect, the student model might learn the teacher’s mistakes and ignore true labels. If α is too low, then you’re barely using the teacher’s signal.
- Availability of a Good Teacher: You need a well-trained teacher model. In scenarios where training a big model is just not feasible, distillation might seem less applicable (though online distillation tries to address that by training one on the fly).
- Data Domain Shift: If the distribution of data on which you want to deploy the student is different from the teacher’s training data, then the teacher’s knowledge might not fully apply. The selection of the training data for distillation is important: ideally it’s the same data or at least covers the domain well.
- Additional Training Overhead: Distillation is an extra training step. You essentially train two models (teacher then the student) which can be time-consuming. There is also overhead in generating teacher predictions for all training data.
💡Pro Tip: DETR models can be expensive to deploy. Our Knowledge Distillation article shows how DETR-style detectors can be compressed into smaller models while preserving most of their performance.
Best Practices for Effective Distillation
Below are some guidelines that will help you run distillation in the most effective way possible:
- Train or choose the best teacher you can: The student model can only be as good as the teacher model in most cases (there are rare cases of student surpassing teacher due to regularization, but generally). So ensure the teacher model is high quality on the task.
- Use intermediate layer distillation when applicable: Don’t limit to just final outputs if you have a network-based model. Adding one or two feature-based losses can significantly help the student learn important representations.
- Tune hyper parameters (temperature T and loss weighting): There’s no one-size-fits-all. Try a few values of T (e.g. 1, 2, 4, 8) and see which makes the student perform best on validation. Adjust the weight of distillation loss – if the student is not learning enough from the teacher model, increase it; if it’s over-mimicking and not fitting true labels, decrease it.
- Consider data augmentation or additional data: The more data you have for distillation, the better. Since the teacher model can label unlabeled data (with soft targets), you are not limited to the original training set. You can use knowledge distillation with unlabeled data – this is like a semi-supervised learning approach.
Conclusion and Future Outlook
Knowledge distillation has become a cornerstone technique in modern deep learning engineering, enabling the deployment of large and complex models in scenarios with limited resources by transferring knowledge to compact models. We’ve seen how the teacher-student framework compresses models, the various types of knowledge that can be distilled (outputs, features, relationships), and the many schemes and extensions that make KD a versatile tool.
Looking forward, research in knowledge distillation continues to expand:
- The rise of enormous foundation models (in vision and language) means distillation will be even more critical to democratize these models.
- New distillation algorithms are being explored, including better ways to distill knowledge across modalities and tasks, and even distilling reasoning or chain-of-thought in models.
In summary, knowledge distillation stands as a powerful knowledge transfer mechanism in machine learning – one that continues to evolve. By applying the techniques and best practices outlined in this article, you can leverage KD to build smaller, efficient deep learning models that maintain the prowess of their larger counterparts.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


