
How We Reproduced DINOv2 (So You Don’t Have To): Technical Guide
Table of contents
Share blog post



We successfully reproduced DINOv2 within LightlyTrain, verifying its correctness and simplifying the process. You can now train DINOv2 models in a single command—no hassle, no guesswork, just reliable performance.
Share blog post
We integrated DINOv2 into LightlyTrain: it works, and we verified its correctness. It wasn’t all smooth sailing, but we pulled it off. Most importantly, we learned some lessons along the way.
You can now safely train your own DINOv2 model in a single command:
import lightly_train
if __name__ == "__main__":
lightly_train.train(
out="out/my_experiment",
data="my_data_dir",
model="dinov2_vit/vitb14_pretrain",
method="dinov2",
)
Introduction
DINOv2 is widely considered the state-of-the-art method to learn visual representations from images alone.
Although it has already celebrated its 2-year anniversary, it remains remarkably relevant today.
Companies are increasingly building Vision Foundation Models (VFMs) for their specialized domains.
Other practical applications have emerged, with DINOv2 at their core: data curation, depth estimation, and even as vision encoder in large multimodal models (LMMs). So yes, in a world where “VFM” is among the most common words, second only to the words “the” and “GenAI”, DINOv2 is still very much in the conversation today!
At Lightly, we help teams unlock the full potential of foundation models like DINOv2 by integrating them into practical training and data workflows:
- LightlyTrain: Pretrain and fine-tune DINOv2-based models on your own domain-specific data for tasks like segmentation, classification, or detection.
- LightlyOne: Use DINOv2 embeddings to intelligently curate the most diverse and informative samples for training.
Whether you're building a VFM or just leveraging one, Lightly makes it faster, smarter, and easier. Check out also LightlyTrain x DINOv2: Smarter Self-Supervised Pretraining, Faster for more information.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Why bother reproducing DINOv2?
You might be thinking:
"The repo is public, the pretrained models are a download away, so why even bother?"
Well, as the saying goes: an image is worth 16×16 words (or was it a thousand?).



You got the idea, right?
Running DINOv2 from the official repo isn’t exactly plug-and-play. It demands a decent amount of time, GPU firepower, and serious dino-riding skills. That’s where Lightly comes into play!
Just two months after DINOv2 was published on arXiv, it had already made its way onto our bucket list.
At the time, we were optimistic, maybe a little too optimistic, that we’d have it shipped in no time:
Little did we know, a few surprises were lurking around the corner.
As is often the case, priorities shifted, resources got shuffled, and it wasn’t until recently that we rolled up our sleeves and got to work integrating DINOv2 into our latest product: LightlyTrain.
Of bugs and engineers
The implementation process actually went quite smoothly, and before long, a “bug-free” version was ready for benchmarking.
-min.png)
That’s when the real fun began.
To put things in perspective, we first established baselines using the official DINOv2 implementation. Then, we set out to reproduce those results with our own implementation.
To enable rapid iteration, we used k-NN classification as our evaluation method. Our initial baseline was a ViT-S/16 model, pretrained for 50 epochs on ImageNet-1k.
(Un-)fortunately, it didn’t take 50 epochs to realize that something was off.
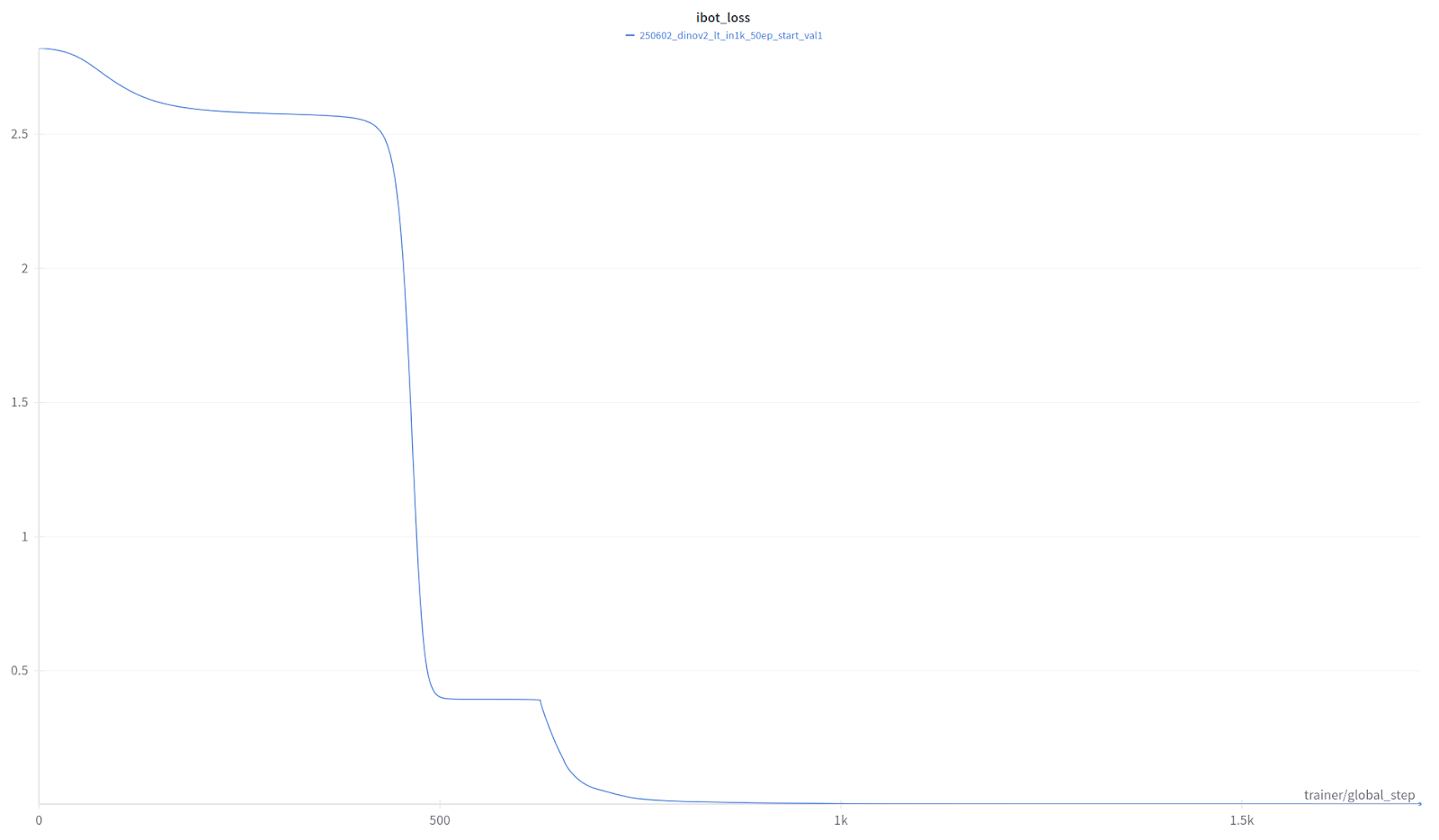
The iBOT loss collapsed to zero after just the first epoch. This loss encourages similarity between the representations of masked patches from the student and the corresponding unmasked patches from the teacher.
The fact that the loss dropped to zero so quickly meant that our ever-so-clever model had found a shortcut to minimize the loss without actually learning anything. In practice, this strongly pointed toward information leakage between masked and unmasked tokens/patches.
Unlike the DINO loss, iBOT’s loss is enforced between teacher and student representations of the same view, which makes it especially sensitive to this kind of leakage. So naturally, we dove back into the code to investigate that.

Thankfully, we didn’t have to go line by line.
Just a few well-placed breakpoints later, we found our second hint: the tokens entering the iBOT head didn’t all have the same norm, which was unexpected as the tokens are passed through a LayerNorm at the output of the ViT.
With that clue, we knew exactly where to look.
And there it was, obvious in hindsight, hiding in plain sight. A simple reshaping error was breaking the spatial structure of the representation, causing patch tokens to leak information from neighboring patches. That explained the odd behavior of the iBOT loss.
Moments later, the issue was fixed and a new training run was launched, only to discover that we were still falling short of the target accuracy by more than 6 percentage points…
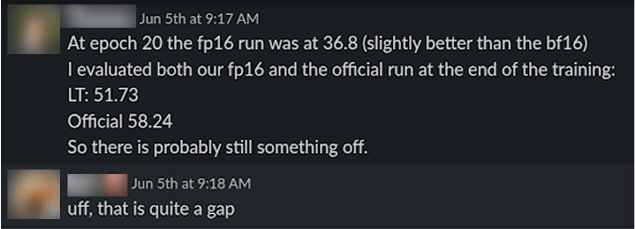
That’s when we turned our attention to the KoLeo loss, which encourages diversity in the image-level representations and plays a key role in DINOv2's performance.
It didn’t take long to spot the problem: we were mistakenly applying the loss after the projection head.
Rookie mistake.
But to be fair, when you're juggling eight local crops, two global crops, two models, and multiple representations before and after the projection head, the variable names stretch past formatting limits - and the code quickly turns into a bowl of spaghetti. Errors like this are easy to miss.
After uncovering a fair number of new bugs and enduring just as many unfruitful training runs, we decided it was time for a different approach.
Taming the DINO
Searching for bugs across the entire codebase is both painful and time-consuming, especially in machine learning, where models often appear to run correctly, but subtle errors only surface after a full training cycle.
Not to flex, but yes we got our hands on a bunch of B200. So we figured, why not let them do the debugging for us?
Our approach was simple. We stripped DINOv2 all the way down to DINO(v1) (up to masking), removing the following components:
- The iBOT loss
- The KoLeo loss
- Freezing of the last layer
We then validated each stage individually against the corresponding version from the official implementation, and only added components back once we had confirmed everything was working correctly in the simplified setup. This allowed us to isolate bugs more effectively and concentrate on a manageable subset of the code.
From that point onward, progress accelerated. The DINOv1 version worked out of the box, which allowed us to reintroduce the iBOT loss.
iBOT loss
It turned out that we were reusing the projection head from our DINOv1 implementation to avoid near-duplicate code. However, it differed from the official one in two subtle but important ways:
- The standard deviation used to initialize the linear layers was different.
- The feature normalization before the last layer used a larger epsilon in the official version, which is important for fp16 stability to avoid division by zero.
The devil is in the details. After aligning these differences, we were able to validate this stage!
What puzzled us was that these differences should have affected the DINOv1 stage too. After all, the DINO and iBOT projection heads are identical and typically share weights. The most likely explanation is that spatial tokens (especially the masked ones?) are more likely to have very small norms.
KoLeo loss
As mentioned above, we had already fixed this part of the code earlier and were able to reproduce the results directly.
Freezing of the last layer
The final step was to re-activate the freezing of the last layer during the first epoch.
The issue came from another legacy import from our DINOv1 implementation. Both DINOv1 and DINOv2 aim to keep the last layer frozen during the first epoch, but they implement it differently.
In DINOv1, the gradient for the last layer is explicitly set to None, which effectively removes it from the optimization step.
In DINOv2, the learning rate for the last layer is set to zero right before the optimizer step, which also prevents the weights from being updated.

Although they appear equivalent, they’re not.
Setting the gradient to None means the parameter is completely ignored, no update, no momentum, no tracking. Setting the learning rate to zero, on the other hand, still allows the optimizer to update its internal state for that parameter, which can lead to subtle differences in training dynamics later on.
Once that final change was made, we had successfully reproduced the full DINOv2 method.
Final DINOv2 test: The Results
As a final test, we reproduced the training of ViT-L/16 for 200 epochs on ImageNet-1K, aiming for the reported top-1 k-NN accuracy of 81.6%. Notably, we used a global batch size of 1024 instead of 2048.
Not going to lie, our knees were weak, arms were heavy throughout the entire run. But we made it: 81.9% accuracy!
The DINOv2 losses can be a bit off-putting, reading the curves sometimes feels like interpreting tea leaves. To make things easier, we’re sharing our loss curves as a reference for when you try the package on your own.
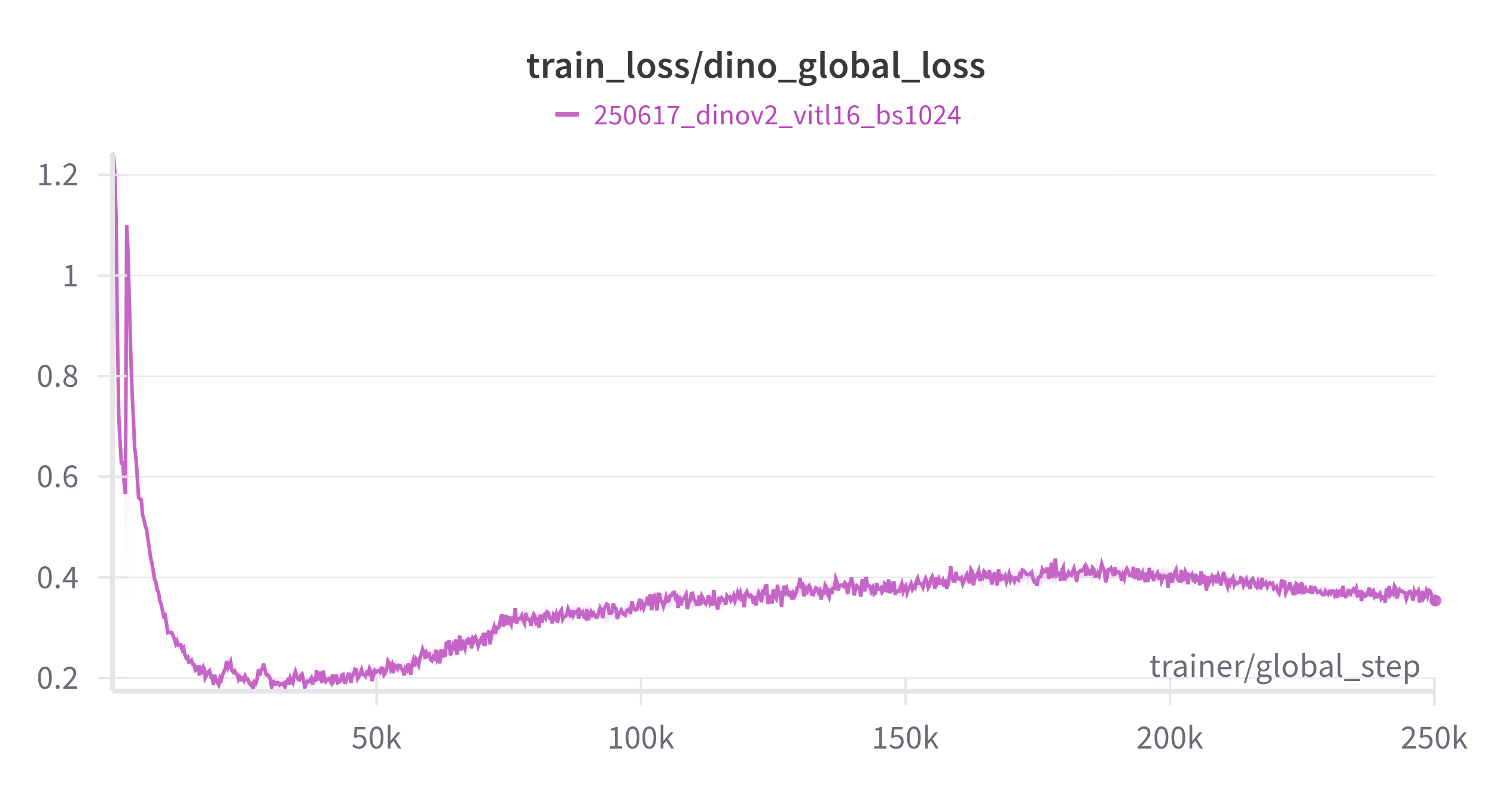
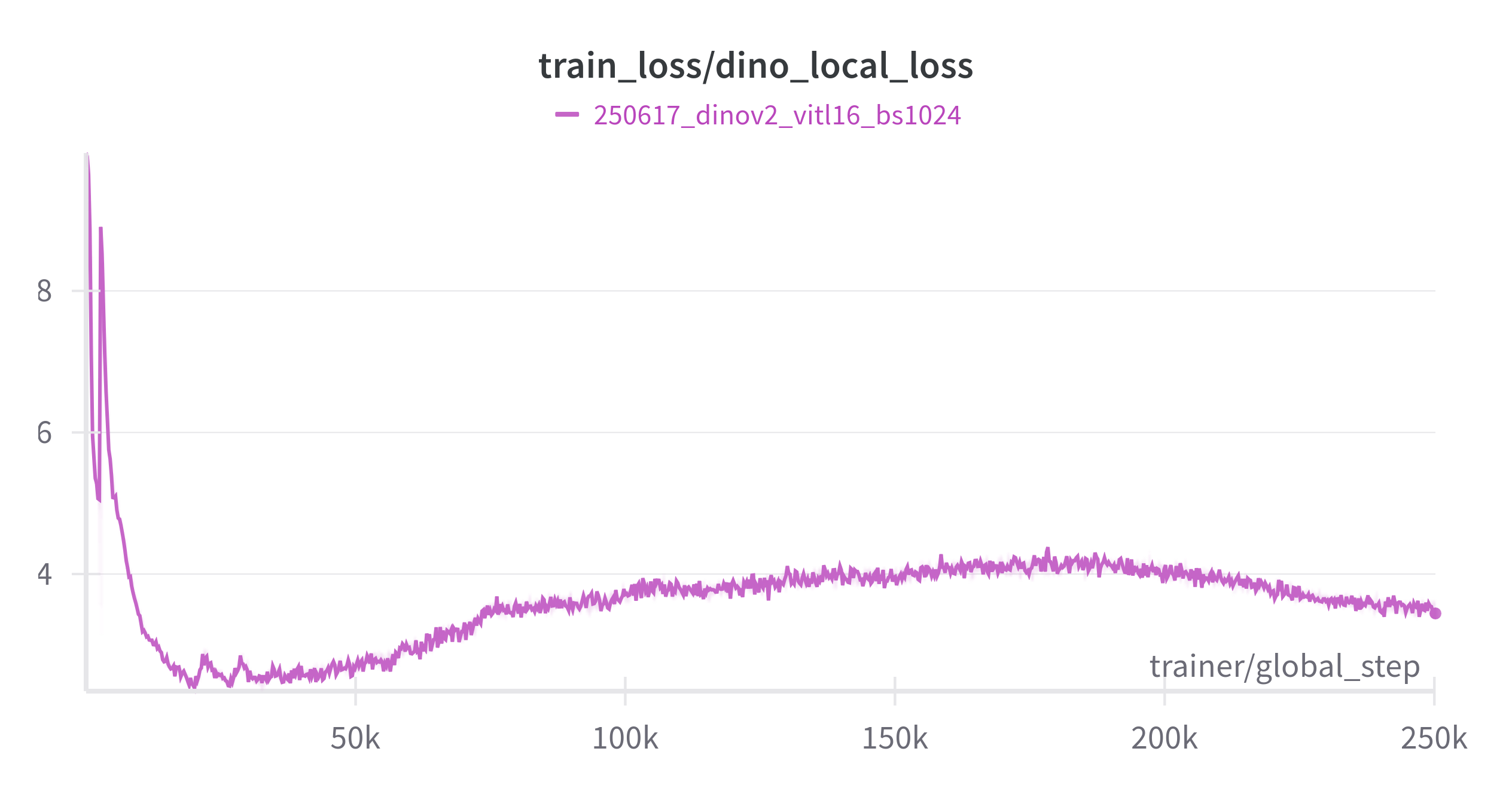
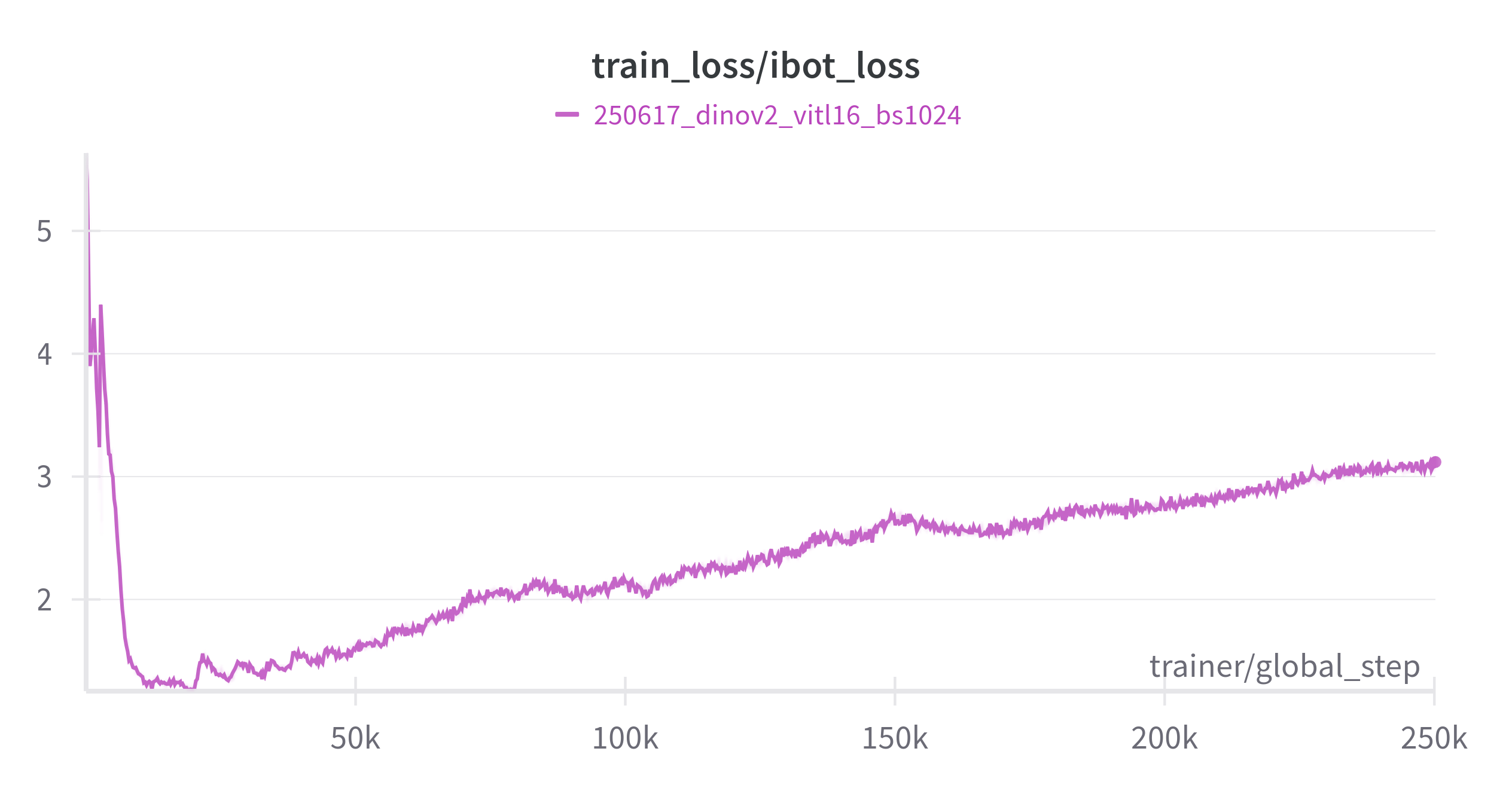
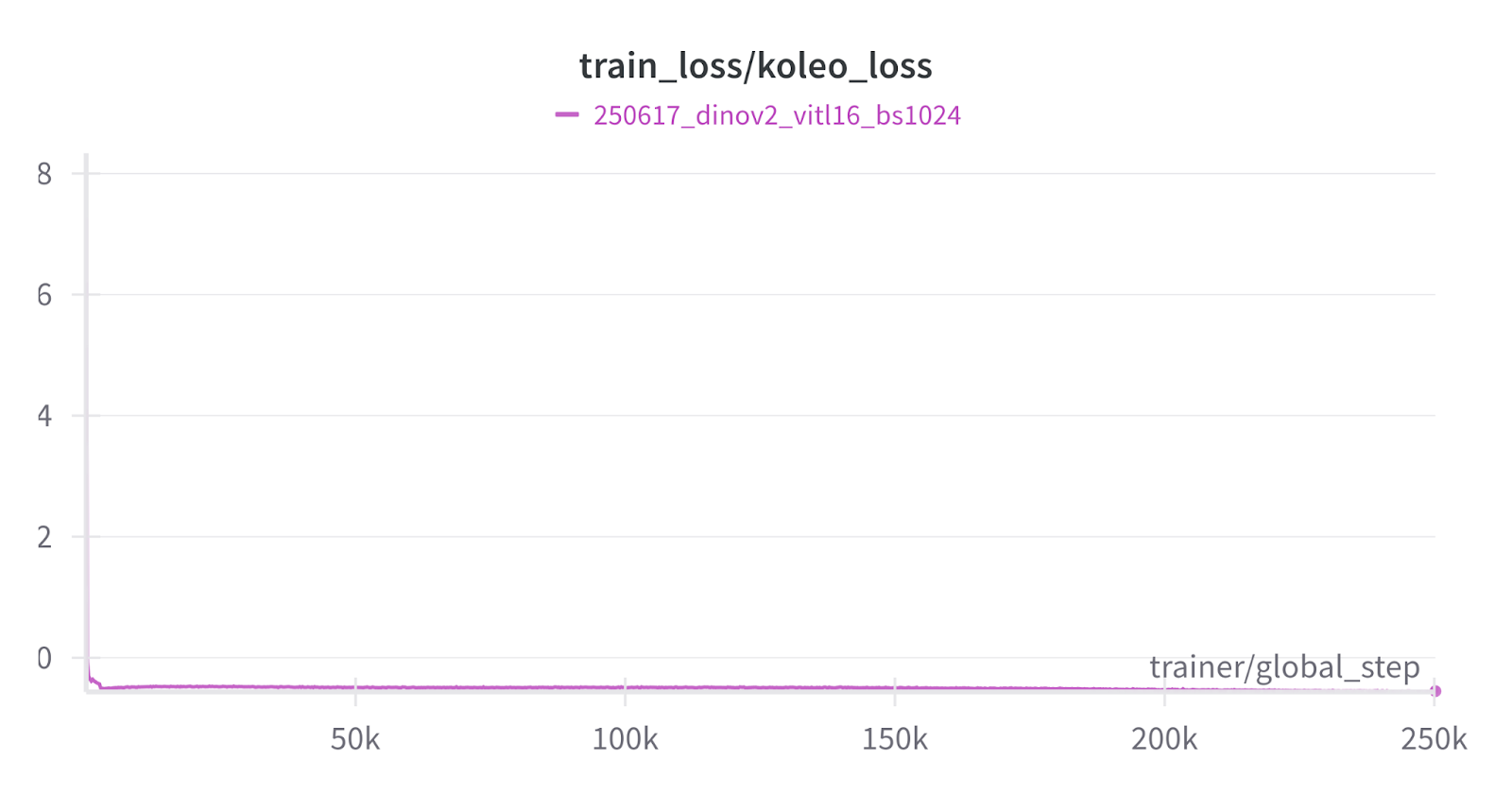
And that wraps up our journey: we’ve removed the pain points of training DINOv2 so you can reproduce results or fine-tune the model on your own data with confidence.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


