
OpenAI CLIP Model Explained: An Engineer's Guide
Table of contents
Share blog post



Explore OpenAI's CLIP model, a breakthrough in multimodal AI that learns visual concepts from natural language. Discover how its dual-encoder architecture enables zero-shot image classification, text–image retrieval, and more, without the need for labeled training data.
Share blog post
Here’s a quick overview of the key information about CLIP.
- What is OpenAI’s CLIP?
CLIP (Contrastive Language-Image Pre-Training) is a neural network model that jointly trains an image encoder and a text encoder to produce a shared embedding space for images and text. Developed by OpenAI in 2021, it learns visual concepts from natural language descriptions instead of traditional labeled datasets.
- How does the CLIP model work?
CLIP consists of two parts: a vision model (e.g., ResNet or Vision Transformer) that encodes images, and a text model (Transformer) that encodes text. During training, it was shown pairs of images and captions and learned to match each image with its correct caption and not with others (a contrastive learning objective). As a result, CLIP can judge how well an image and a text description correspond by outputting a similarity score.
- What is CLIP used for?
CLIP is primarily used for zero-shot image classification and image–text retrieval. For example, without any task-specific training, CLIP can classify an image by picking which textual label (provided in natural language) best matches the image. It’s a foundation model for many multimodal tasks – you can search for images using text, filter or rank images by captions, or use CLIP’s embeddings in other models.
- What are the components of CLIP’s architecture?
CLIP has a dual-encoder architecture: a vision encoder (either a CNN like ResNet-50 or a Vision Transformer) and a text encoder (Transformer language model). Both encoders output feature vectors (image features and text features), which a linear layer projects into a common embedding space. The model was trained end-to-end on 400 million (image, text) pairs, aligning these two modalities.
- Why is CLIP important?
CLIP demonstrated that learning from natural language supervision at scale can produce extremely general and flexible vision models. It achieves impressive accuracy on certain tasks without needing explicit training on those tasks (closing the “zero-shot gap” in robustness), and has become a building block in many AI systems (from image search engines to generative AI pipelines). Its approach of jointly training on image-text data has influenced many subsequent research projects in multimodal AI.
OpenAI CLIP Guide: Zero-Shot Image Classification & Contrastive Learning
OpenAI’s CLIP (Contrastive Language–Image Pretraining) is a multimodal neural network that connects images and text in a shared embedding space.
Introduced in 2021, CLIP was a breakthrough in computer vision because it enables zero-shot image classification – the ability to categorize images into any user-specified label set without additional task-specific training.
Instead of training on a fixed set of classes, CLIP learns from web-scale data of image-text pairs, giving it a broad visual vocabulary and robust generalization. This guide unpacks how CLIP works, demonstrates zero-shot workflows, flags its biases and failure modes, and previews where multimodal AI is heading next.
- What is OpenAI’s CLIP: Architecture?
- How does the CLIP model work?
- Zero-shot image classification with CLIP
- Using CLIP in practice
- CLIP limitations
If you're training your own CLIP-style models, LightlyTrain offers a self-supervised learning pipeline that enables pretraining vision models on your unlabeled, domain-specific data, reducing the need for labeled datasets and improving performance on tasks like classification, detection, and segmentation.
What is OpenAI’s CLIP: Architecture
CLIP (Contrastive Language–Image Pre-training) is a neural network trained to link images and natural language. Unlike traditional vision models that require manually labeled datasets, CLIP learns from web-scale, noisy data and can recognize a vast array of visual concepts by leveraging descriptive text.
In essence, CLIP can be thought of as both an image encoder and a text encoder that share a common representation space. This section outlines CLIP’s origin and key features, why it matters for zero-shot learning, and how it compares to standard vision models.
Trained on Web-Scale Data
One of CLIP’s defining characteristics is the sheer scale and diversity of its training data. OpenAI researchers assembled a new dataset of approximately 400 million (image, text) pairs from the internet.
These pairs consist of images and their associated captions or descriptions (e.g., alt text). The data is web-scale in both size and variety: it spans a broad range of visual concepts and scenes, reflecting the richness (and noise) of internet content.
Crucially, this massive dataset was collected without explicit human labeling of classes – the supervision comes naturally from image captions. Training on such an uncurated corpus has two major benefits:
- Wide Visual Vocabulary: CLIP learns about a huge number of objects, styles, and concepts (far beyond the 1,000 classes of ImageNet). It effectively acquires knowledge of anything people talk about in images online. For instance, it can recognize a teapot or a toboggan even if those weren’t explicit categories in a traditional benchmark.
- Scalability: Because data is scraped from the web, it bypasses the need for labor-intensive labeling. It is easier to scale up natural language supervision than to collect millions of labeled images. This allowed OpenAI to train on two orders of magnitude more data than standard vision datasets.
However, web data is noisy and unfiltered.
CLIP had to learn robustly despite occasional mismatched image captions. The authors applied only minimal filtering and data cleaning, relying on scale to average out noise. This approach followed the success of NLP models (like GPT) that train on raw text at a massive scale.
Key Features
- Dual encoders. A Vision Transformer (ViT) or modified ResNet processes pixels, while a 12-layer Transformer tokenises text; both map to the same 512-D latent space.
- Prompt-based inference. Any class name becomes a prompt—e.g., “a photo of a fire truck”—so CLIP works zero-shot on new tasks.
- Cross-modal retrieval. Because image and text live in one space, you can search images with text or vice-versa without extra training.
Robustness to distribution shift. The web-scale corpus gives CLIP higher accuracy on corrupted or out-of-distribution photos than a supervised ResNet of similar baseline accuracy
Pro Tip: Want to see how contrastive objectives power other domains? Check our quick primer on self-supervised learning to understand why unlabeled data is your biggest asset.
Why It Matters — Zero-Shot Learning
The most notable aspect of CLIP is its zero-shot learning ability.
In zero-shot classification, a model is evaluated on categories it never explicitly saw during training – it must generalize using some form of description or context. Prior to CLIP, zero-shot vision was limited and far from competitive with fully supervised models (e.g., an earlier attempt in 2016 achieved only 11% accuracy on ImageNet, zero-shot). CLIP changed the game by demonstrating high-quality zero-shot performance at scale.
By not training on any specific benchmark, CLIP can be applied to any visual classification task by providing the category names. This is analogous to how GPT-3 can perform new NLP tasks given a prompt, without fine-tuning.
For example, if you have images of animals, you can ask CLIP to classify them as “cat”, “dog”, or “horse” simply by providing those words – no additional training needed. The ability to leverage natural language as flexible supervision is what unlocks this power
From an engineering perspective, zero-shot models like CLIP can reduce the need for collecting task-specific datasets and enable rapid prototyping of classifiers.
If you have a set of categories you care about, CLIP lets you try classifying images into those categories immediately by providing text descriptions – an extremely efficient workflow. For instance, “find images in this set that contain a blue car, a red car, or no car” can be done by prompting CLIP with those phrases.
Comparison to Standard Models
How does CLIP compare to the “standard” vision models that came before it? The table below contrasts CLIP with a typical convolutional network (ResNet), a Vision Transformer (ViT), as well as a couple of related multimodal models that followed CLIP (Google’s ALIGN and Salesforce’s BLIP-2):

CLIP represents a shift from training vision models with fixed labels to training on natural language descriptions, enabling flexible zero-shot capabilities. It differs from a ResNet or ViT in that it learns a joint language-vision space, meaning we can query the model with text.
Pro Tip: For more background on contrastive learning in vision, see our brief introduction to contrastive learning – CLIP is a prime example of how powerful contrastive methods can be found at this Lightly Blog.
How does the CLIP Model Work?
At its core, CLIP learns to bring images and their corresponding texts closer together in an embedding space, while pushing apart unrelated image-text pairs. It achieves this through a specific architecture and a contrastive learning framework.
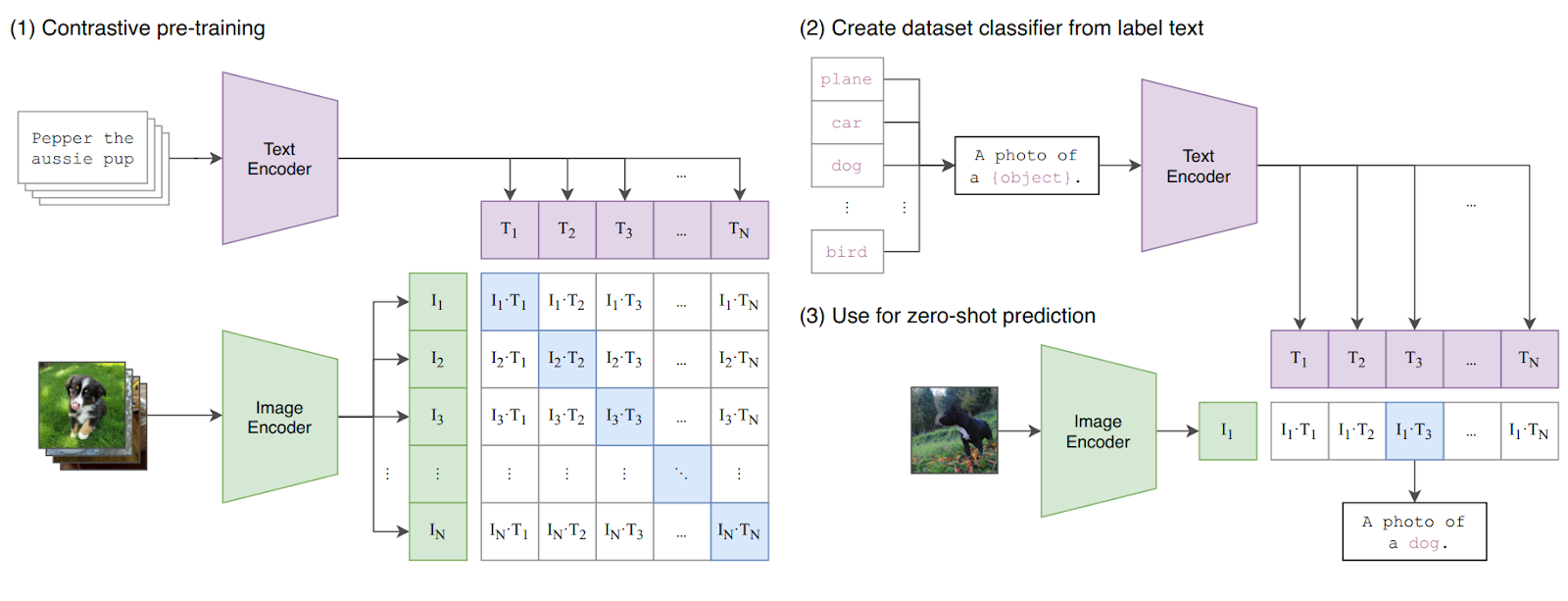
Architecture / Model Details
At its core, CLIP is a dual-encoder: a Vision Transformer (or widened ResNet) processes raw pixels while a 12-layer Transformer tokenises the caption; both project into the same 512-D latent space via learned linear heads.
The ViT backbone divides the image into 16 × 16 patches, flattens them, adds positional embeddings, and feeds the sequence to multi-head self-attention—exactly the recipe from the original ViT paper. OpenAI trained several capacity tiers: RN50, RN50x64, ViT-B/32, ViT-L/14; the largest (ViT-L/14) totals ≈ 428 M parameters and accepts 224 px or 336 px crops
After encoding, CLIP normalises both vectors and computes their dot product; a low-rank linear projection suffices—no cross-attention between modalities, keeping inference fast and modular
The Contrastive Learning
Training uses a symmetric, batch-global cross-entropy loss: for a batch of N image-text pairs, it builds an N × N similarity matrix; each correct match should dominate its row and column, all 2 × (N – 1) negatives should be suppressed. A learnable temperature parameter rescales logits (initialised to 0.07) to stabilise early gradients
Researchers later showed that a pair-wise sigmoid loss (SigLIP) can replace the softmax normalisation, enabling even larger batch sizes and boosting zero-shot ImageNet accuracy to 84.5 % on a ViT-B/16 encoder
Conceptually, contrastive learning forces the model to “pull together” semantically matching views while “pushing apart” everything else.
Pro Tip: If terms like positive/negative pairs or temperature scaling sound fuzzy, this short guide demystifies contrastive learning with diagrams and code snippets.
Language-Image Pre-Training
During CLIP’s pre-training, image augmentations were kept minimal; primarily, random resized cropping was used. Unlike some self-supervised vision methods that heavily augment images, CLIP didn’t require strong augmentation; the diversity in the data itself provided variety.
Training proceeds with the contrastive loss as described, typically with large batch sizes (to have many negatives). The model sees a wide variety of image-text pairs from different domains (artwork with descriptions, photographs with captions, screenshots with alt text, etc.), forcing it to develop rich, general features.
For example, CLIP implicitly learns to do OCR (reading text in images) because many images (like memes or screenshots) are paired with text that corresponds to embedded words. It learns about fine-grained categories (e.g., different bird species) if such distinctions appear in captions.
The result of this pre-training is a model that is not specialized to any one task, but rather learns to associate visual and linguistic concepts broadly. As a consequence, CLIP’s embeddings can be used for many tasks: zero-shot classification, as features for downstream models (by training a small classifier on them), for image search, and more.
In the words of the authors, “CLIP learns to perform a wide set of tasks during pre-training without explicit instructions.” This emergent capability is analogous to how large language models pick up various skills during language modeling.
To summarize, CLIP’s training process jointly trains two encoders to align images and texts. After training, the model itself is just these two encoders (plus their projection layers). There’s no fine-tuned classifier in the mix. So, how do we actually use CLIP to classify images? That’s where the idea of zero-shot inference comes in, which we’ll explore next.
Pre-training Your Own Vision Foundation with LightlyTrain
CLIP shows the power of self-supervised learning on 400 M generic image-text pairs. But what if you want a foundation model tuned to your domain—industrial parts, medical scans, or drone footage?
LightlyTrain lets you run the same contrastive pre-training loop on your unlabeled data in a few lines of code. Teams report double-digit mAP or top-1 gains versus ImageNet starts, even with tiny label budgets.
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo
Zero-Shot Image Classification with CLIP
Using CLIP for image classification is very different from using a standard classifier.
Instead of having a fixed set of output neurons or labels, CLIP lets us specify the labels at inference time in plain language. The overall flow is:
- Encode the candidate text labels into embeddings.
- Encode the image into an embedding.
- Compute similarity scores between the image embedding and each label embedding.
- Derive a prediction and probabilities from these similarities.
We’ll walk through each step in detail, then discuss an example on ImageNet, how to improve results with prompt engineering and ensembling, other zero-shot tasks like retrieval, and practical tips for using CLIP.
Turning Text Labels into Embeddings
CLIP’s text tower expects a short caption-like phrase, not a bare label. The community’s default template—
“a photo of a {label}”
—Works well for generic objects because it matches captions found on the web. For domain-specific tasks, you can tailor the wording (“a drawing of a {label}”, “a satellite photo of {label} terrain”, etc.). Each phrase is tokenised (77-token limit) and fed through the text Transformer, then projected to a unit-norm vector uₖ ∈ ℝᵈ.
💡 Prompt tips
- Add minimal context (“type of aircraft”, “food dish”) to disambiguate.
- Keep prompts ≤ 20 words; longer text rarely helps and risks truncation.
- If your labels include people or sensitive attributes, review for bias.
Embedding the Image
The image tower (ResNet-50, ViT-B/32, ViT-L/14, …) receives a 224 × 224 or 336 × 336 crop, normalised to ImageNet statistics. The final CLS token (ViT) or pooled feature (ResNet) is linearly projected and L2-normalised to give v ∈ ℝᵈ. Preprocessing is handled by off-the-shelf utilities; don’t reinvent it, or scores will drift.
It’s important that both the image and text embeddings are normalized (CLIP’s model does this internally). They lie on the unit hypersphere, meaning their cosine similarity can be computed by a dot product. At this point, we have an embedding for the image and embeddings for each candidate label.
Computing Similarity Scores
Because u and v live on the unit sphere, cosine similarity is just a dot-product:
sₖ = v·uₖ / τ
The learned temperature τ≈0.01 sharpens the logits. Computing the matrix dot-product over a batch amortises cost and supplies implicit hard negatives—a crucial ingredient in CLIP training and inference.
It’s worth noting that CLIP was trained with a temperature parameter that affects these scores. In practice, when using the model, the library will often incorporate the learned temperature by dividing the dot products by (which was found to be around 0.01–0.02 for CLIP models). This effectively scales the logits. But as a user, you typically don’t need to manually do this – using the model’s output is sufficient.
Prediction & Probabilities
Softmax over s yields a categorical distribution:
P(k|img) = exp(sₖ) / Σⱼ exp(sⱼ)
The highest-probability label is the prediction. Treat probabilities as relative confidence among supplied options; if the correct answer is absent, CLIP will still choose something and look confident.
To summarize the inference loop, here’s a pseudocode of zero-shot classification with CLIP using the HuggingFace transformers library:
# Pseudo-code for zero-shot image classification with CLIP (HuggingFace Transformers)
from PIL import Image
from transformers import CLIPProcessor, CLIPModel
# 1. Load a pre-trained CLIP model and its processor
model_name = "openai/clip-vit-base-patch32" # or "openai/clip-vit-large-patch14"
model = CLIPModel.from_pretrained(model_name)
processor = CLIPProcessor.from_pretrained(model_name)
# 2. Prepare your image and class labels
image = Image.open("my_image.jpg")
labels = ["cat", "dog", "horse"] # candidate classes
# 3. Construct prompt texts for each label (simple prompt engineering)
prompts = [f"a photo of a {label}" for label in labels]
# 4. Use the processor to tokenize text and preprocess the image for the model
inputs = processor(text=prompts, images=image, return_tensors="pt", padding=True)
# 5. Get CLIP model outputs (image and text embeddings, and similarity logits)
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # shape [1, len(labels)]
# 6. Compute probabilities by softmax
probs = logits_per_image.softmax(dim=1).cpu().numpy()[0]
# `probs[i]` is the probability for `labels[i]`
# 7. Identify the highest-probability label
pred_index = probs.argmax()
print(f"Predicted label: {labels[pred_index]} (confidence {probs[pred_index]:.2f})")Pro Tip: Embeddings aren’t just numbers—they’re the backbone of similarity search, active learning, and annotation queues. Dive into their practical uses in ML pipelines.
ImageNet Zero-Shot Example
ImageNet has 1,000 classes (e.g. “Persian cat”, “garbage truck”) and to apply CLIP zero-shot, one would take the official names of those classes (or better, a human-friendly version of them) and create prompts like “a photo of a Persian cat”, “a photo of a garbage truck”, etc. Then feed an ImageNet validation image and see which description CLIP thinks is most similar.
CLIP essentially matched the accuracy fully supervised model without having seen a single ImageNet label in training. This was the first time a zero-shot approach had reached that level of performance on ImageNet, marking a milestone in computer vision.
To get to 76%, the CLIP authors invested in prompt design (not just using the raw WordNet labels). For ImageNet, they actually engineered a set of 80 prompts per class and ensembled them, which gave a few extra percentage points. We’ll cover that technique next.
Nonetheless, even with a single simple prompt like “a photo of a {label}”, CLIP’s zero-shot ImageNet accuracy was around 63-70% for smaller models and ~75% for the largest model. These numbers were really interesting at the time for zero-shot vision.
Prompt Engineering
Since CLIP learned from noisy internet text, certain phrasings may match its training distribution better. For example, many image captions on the web might begin with “a photo of a …” or “an image of a …”. Including such context often helps the model understand you’re describing an object in an image.
OpenAI researchers found that crafting prompts improved accuracy on several datasets. A few general tips from their findings and subsequent research can be found in the table below.

Key Insights
- CLIP learned from internet captions - think like you're writing an image description
- Literal descriptions often work better than creative metaphors
- Test prompts on multiple examples, not just one
- Performance can vary significantly across different image domains
Ensembling Prompts
Prompt Ensembling uses multiple prompt variations per class instead of one. OpenAI used 80 different prompts per ImageNet class (like "a bad photo of a {label}", "a photo of many {label}") and averaged their embeddings. This boosted zero-shot accuracy by 3.5% with no inference cost, since text embeddings can be pre-computed and averaged offline.
The technique reduces prompt bias and stabilizes predictions by querying the model with the same concept in different ways. Even using just 2 prompts like "a photo of a {label}" and "the {label}" can help. Prompts must be semantically similar (represent the same class). Combined with prompt engineering, ensembling improved performance by ~5 points across datasets.
Beyond Classification – Retrieval
CLIP isn’t limited to predicting one of a set of given labels. Thanks to its symmetric design, you can also use it for image–text retrieval tasks. In retrieval, given a query (which could be an image or a text description), you want to find the best matching items from a database of the other modality.
- Image-to-Text (Caption Retrieval): Given an image, find the best matching caption from a text database. The image and all candidate texts are encoded, and then similarity scores determine the optimal match.
- Text-to-Image (Image Search): Query with natural language (e.g., "red sports car on racetrack") to find matching images in a database. This powers search engines with descriptive queries instead of keywords.
Because CLIP embeddings are comparable across modalities, any scenario where you need to match or rank images and text can leverage them. This includes tasks like finding which of several images best match a given text (or vice versa). It can also be extended to image-to-image retrieval by comparing image embeddings.
Practical Applications:
- Dataset search tools for curation workflows
- CLIP re-ranking for generative models (filtering DALL-E outputs)
- Zero-shot content moderation by flagging images similar to undesirable text prompts
- Image-to-image retrieval via embedding similarity
CLIP's broad visual-linguistic training handles abstract descriptions well, making it effective for matching high-level concepts. However, it inherits the same limitations as classification - potential bias issues and difficulty with fine details.
Examples of Zero-Shot Tasks
Beyond plain image classification and retrieval, CLIP’s zero-shot abilities extend to various tasks:
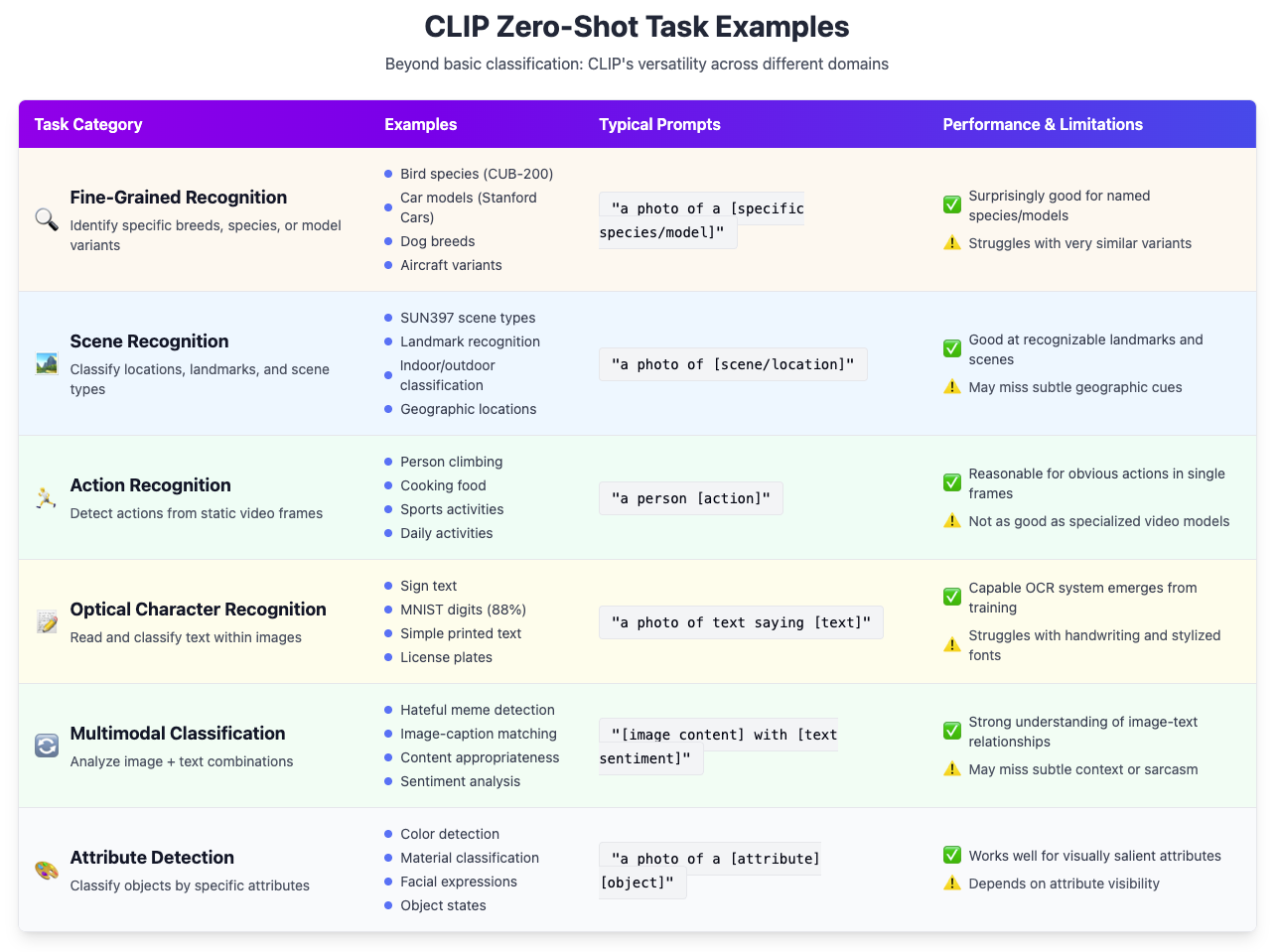
In many of these cases, CLIP’s performance might not surpass a dedicated model trained with task-specific data, but the fact that it can do it at all with zero training is valuable. It can serve as a quick baseline or a tool for data exploration.
To use CLIP effectively for a new zero-shot task, keep these tips in mind:
- Properly phrase the labels or descriptions for what you’re trying to detect.
Be aware of what CLIP might not know (e.g., very specialized medical terminology, or novel memes after 2021 might be out of its vocabulary). - If needed, you can extend CLIP’s knowledge by fine-tuning (we’ll discuss this in the Future Outlook section), but often zero-shot is a good starting point.
Using CLIP in Practice
CLIP is readily accessible through Hugging Face Transformers (CLIPModel/CLIPProcessor) or OpenAI's GitHub repository with clip.load("ViT-B/32"). Many libraries integrate CLIP for image search and classification applications.
Implementation pattern:
- Precompute embeddings for image databases and text labels
- Store embeddings (512-768 dimensions) in vector databases
- At runtime, compute new embeddings and perform a similarity search using cosine similarity
Model size considerations: ViT-L/14 (428M parameters) offers the best accuracy but requires significant compute. For production deployment, smaller models like ViT-B/32 (87M params) or CLIP ResNet-50 (102M params) provide faster inference while maintaining zero-shot capabilities.
Performance highlights:
- General recognition: Matches ResNet-50 on ImageNet zero-shot; superior transfer learning performance
- Robustness: Dramatically outperforms supervised models on distribution shifts (77.2% on challenging ImageNet-A)
- Rich embeddings: Outperformed EfficientNet-L2 on 20/26 transfer learning datasets
Known limitations:
- Fine-grained details: Struggles with subtle differences (bird species, aircraft variants)
- Counting/spatial reasoning: Cannot reliably distinguish object quantities or spatial relationships
- Abstract concepts: Limited to non-visual or contextual tasks
CLIP powers modern AI systems like DALL-E 2/3 for text-to-image generation and enables the LAION-5B dataset creation through similarity filtering.
What is CLIP Used For?
OpenAI initially released CLIP as a research model, and they provided some guidance on what it should (and shouldn’t) be used for. We’ll outline the primary intended uses, as well as use cases that are considered out-of-scope or not advisable.
Intended Use
According to OpenAI’s model card, CLIP is intended as a research tool for the AI community. The goal was to enable researchers to explore zero-shot learning in vision and to study the capabilities and limitations of large-scale multimodal models. In practical terms, the intended uses include:
- Zero-Shot Classification on images, as a way to test generalization. Researchers and developers can use CLIP to quickly try categorizing images into new classes without collecting new training data. This is useful for analyzing model robustness or doing proof-of-concept classifiers.
Multimodal Research: CLIP serves as a foundation for studying how images and text can be jointly learned. It has been used to analyze multimodal neurons (connections between visual features and language concepts) and as a backbone for newer models (like combining CLIP with other networks). - Feature Extraction: Many use CLIP as a generic image feature extractor. Because its embeddings are rich, you can use them as input to downstream models (for example, using CLIP embeddings in a Reinforcement Learning agent that sees images, or in robotics for perception).
- Dataset Exploration and Active Learning: Tools like Lightly (our platform) or others can use CLIP embeddings to visualize and cluster image datasets. This helps in understanding dataset content and selecting representative samples (see the importance of embeddings for how such embeddings aid data curation).

CLIP is a great research model, but it’s not a plug-and-play solution for every vision task in production. It should be treated as a component that needs careful evaluation, and in many cases, fine-tuning or additional layers to specialize or mitigate issues.
Limitations
CLIP comes with clear constraints you must account for before shipping it in production.
Not a Generative Model
CLIP only embeds and compares images and text; it cannot author captions, answer questions, or create pictures. For generation tasks, you still need a text-to-image or language model and can, at best, use CLIP to rank or filter their outputs.
Fixed Text Window
The text encoder trims everything beyond 77 tokens. Very long or multi-sentence prompts lose detail, and CLIP is single-turn—there is no dialog or follow-up conditioning. Keep prompts short, descriptive, and one-shot.
Domain Gaps
Trained on web photos, CLIP underperforms on data it rarely saw: x-rays, microscopy, thermal imagery, dense diagrams, handwritten digits, etc. Zero-shot accuracy can swing from super-human (STL-10) to unusable (tumour slides). Benchmark on your own corpus and be ready to fine-tune or add a lightweight downstream head.
Bias & Unsafe Associations
Web-scale data brings web-scale stereotypes. CLIP may link occupations to gender, pick slurs if they appear in the label set, or mis-label certain demographics (e.g., “criminal/animal” errors noted in the original paper). Never deploy it to classify people; for moderation or search, wrap it with bias filters and human review.
Adversarial Fragility
Because CLIP treats overlaid text as strong evidence, a simple sticker saying “iPod” on an apple can flip the prediction. Crafted pixel noise can do the same. If users can supply images, assume the model can be fooled and add defences (input sanitisation, ensemble checks, or robust training).
Computational Footprint
The flagship ViT-L/14 model (428 M params) needs several GB of GPU memory; inference on CPU is slow. Embedding large image stores requires TB-scale vector indices. For edge or high-throughput use cases, choose a smaller backbone, quantise, or distil—but expect some accuracy loss.
When CLIP falls short: fine-grained classes, counting, calibrated probabilities, legal/medical decisions, or any adversarial setting. Treat CLIP as a powerful but imperfect feature extractor—best used with task-specific data, safety layers, and clear performance envelopes.
Conclusion & Future Outlook
CLIP proved that pairing huge, noisy image-text corpora with a simple contrastive objective can match—and sometimes surpass—traditional supervised vision models. Subsequent efforts keep scaling the recipe: Google ALIGN (1.8 B pairs), OpenCLIP on LAION-5B, and Meta’s LiT/BASIC all push zero-shot ImageNet past 80 %.
Yet raw data is no longer enough. The next advancements will come from curated, diverse, bias-aware data selections—an area where intelligent curation platforms like Lightly can cut cost and error.
Architecturally, expect stronger backbones (ConvNeXt, ViT-H/14), pre-trained language towers, and hybrids that blend CLIP’s two-tower speed with one-tower cross-attention for richer grounding. New objectives—e.g., Sigmoid CLIP (SigLIP) or multi-task mixes with captioning loss—aim to capture multi-label and relational cues.
The frontier is fusion: models such as Flamingo or BLIP-2 bolt CLIP-style encoders to large language models, enabling dialogue, captioning, and VQA from a single checkpoint. Specialisation will happen via lightweight adapters, prompt-tuning, and human-feedback loops, letting teams tailor CLIP to medical, satellite, or multilingual domains without full retraining.
Open audits, bias-mitigating filters, and adversarial defences will be integral to “CLIP 2.0”. For practitioners, mastering these evolving tools means faster prototyping, broader reach, and more responsible multimodal AI.

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.


.png)
.png)


