
Lightly's Data Curation Approach
Table of contents
Share blog post



This overview is intended to help everyone understand how LightlyOne works behind the scenes and how it can be used for your data curation workflow.
Share blog post
Here is some key information on what LightlyOne is and how it works.
What problem does LightlyOne solve?
Labeling vision data is expensive and inefficient. LightlyOne helps ML teams curate large unlabeled datasets, select only the most valuable samples, and improve model performance with fewer labels.
How does LightlyOne understand unlabeled data?
It creates embeddings - compact vector representations of images. These embeddings make it possible to visualize, compare, and cluster datasets, helping identify patterns, outliers, and diversity.
What can embeddings be used for?
- Diversification: Select semantically diverse samples to reduce labeling effort.
- Visualization: Use PCA, TSNE, or UMAP to see clusters (e.g., day vs. night).
- Similarity search: Find duplicates or outliers quickly.
How does LightlyOne ensure embedding quality?
Instead of relying on fixed supervised models like ResNet-50, it leverages self-supervised learning (SSL). SSL creates embeddings tailored to semantically meaningful groupings (e.g., “vehicles” instead of separate “car wheel,” “car mirror”).
What role does Active Learning play?
- With predictions (uncertainty sampling): Pick images where the model is least confident.
- Without predictions (diversity sampling): Pick a diverse set of unlabeled images when no model exists yet.
- Combined (CORAL method): Selects low-confidence samples that are also diverse, balancing both approaches.
How does this improve ML models?
By continuously curating datasets, teams can:
- Ensure correct labels
- Add data where the model struggles
- Improve robustness and fairness of trained models
Is it scalable?
Yes. LightlyOne is built to handle millions of images or thousands of videos, optimized for performance and easy integration into ML workflows.
This overview is intended to help everyone understand how LightlyOne works behind the scenes and how it can be used for your data curation workflow.
LightlyOne is a data curation solution with a focus on vision data. ML teams across the globe use LightlyOne to understand their data and intelligently select samples to be annotated and used in training their ML models.
Let me walk you through the LightlyOne approach of data curation!
Understanding Unlabeled Data
When we do large-scale data curation we often start with unlabeled data. Unfortunately, we oftentimes have no prior information about the data — the data is essentially a black box. Many ML engineers at this point will simply open a file browser and scroll through the images to get an understanding of the dataset.
Embeddings
A better approach is to make use of what we, at Lightly, call embeddings. Embeddings are vector representations of data. For example, an image consisting of millions of pixels can be represented as a sequence of numbers forming a vector. However, these such high-dimensional vectors have many practical disadvantages. The clue is that this vector can have a very low dimension. We typically derive embeddings by feeding the input data through a model and taking the output of the last layer before the classification head. For example, the popular ResNet-50 model would yield a 2048-dimensional vector for each input image. We compressed the content of an image from millions of pixels down to 2048 numbers.

LightlyOne offers a variety of features to make use of embeddings for data curation:
- Diversification: Use similarity between embeddings to select a semantically diverse set of images and reduce the burden on your labeling team.
- Visualization: Plot the dataset in two dimensions using PCA, TSNE, or UMAP to understand your data at first sight.
- Similarity Search: Find similar images or clear outliers in your dataset based on similarity and density measures.
Be careful though, not all embeddings are equally useful! For example, the ResNet-50 we just mentioned has a 2048-dimensional vector. Large embedding vectors result in more storage and compute overhead. Additionally, they suffer from the “curse of dimensionality” problem.
To work around these problems we can make use of the fact that the 2048-dimensional embedding data oftentimes lies on a low-dimensional manifold and can therefore be properly represented in a lower-dimensional space. Think of an A4 paper that you slightly bend to form a C shape. In the local neighborhood of two points on the paper, you could say that the euclidean distance is very accurate. However, if you look at two tips of the C shape they are actually closer in the absolute distance (as you don’t measure along with the bent paper but across the gap). The same holds true for embeddings. Therefore, if we work with high-dimensional embeddings, a simple metric like the pairwise distance can become very noisy and unreliable.
At Lightly we use low-dimensional embeddings (32 to 128 dimensions) to avoid the aforementioned problems.
Quality of the Embeddings
Another problem we often face is the quality of the embeddings. Let’s use the ResNet-50 embeddings example again: As we use the last layer before the linear classification layer the representations are already very well clustered. ImageNet has 1'000 classes. In order to achieve a high classification accuracy, the representations need to be pretty well separable by the linear layer. Using a pre-trained model has the advantage that we already have good clustering. However, the clustering might not be the way we actually want it.
In ImageNet, for example, we have separate classes for “car mirror”, “car wheel”, “cab”, “fire truck” and “garbage truck”. But what if we don’t want these classes to be separate but rather close to each other?
Maybe we just want one group of “vehicles” instead?
What we actually need is a way to create embeddings that connect semantically similar images to each other in an adaptive way. Ideally, we could train a model for just that. And ideally, this model would not require any labels.
The good news is that we can solve this problem, too. LightlyOne makes use of the latest advances in self-supervised learning to generate high-quality embeddings.
Self-Supervised Learning
With self-supervised learning, we can train models on data without using any labels. Learn more about the advantages of self-supervised learning here.
At Lightly we believe that leveraging self-supervised learning is crucial to creating high-quality embeddings of your data. On one hand, we can tweak the way the data will be clustered and represented using this approach. On the other hand, we have a way to always create embeddings even when no labels or models are available. In fact, we believe so much in this new research area that we released our own framework for self-supervised learning and made it fully open-source.

Improving the Model by Improving the Data
One of the main goals for investing in data curations is to improve the performance of the machine learning model. The great thing is that we can iteratively improve the quality of the training dataset and thereby continuously deliver better models.
- Make sure our model learns from correct labels
- Focus on selecting the data in a better way using methods such as active learning
Active Learning with Predictions
A popular approach to updating a training dataset is to use the trained model and its predictions on unlabeled data. With every prediction, we also get a probability attached to it. The probability can also be seen as the confidence of the model to make a correct prediction. If the confidence is high we likely have a correct prediction. If the confidence is low the model is not sure about its own prediction. We don’t need to rely on the confidence alone. We can also sample new images based on the predicted class.
Using model predictions for selecting new data for labeling is called Active Learning and is its own research field.
Here is a great paper on using active learning for object detection:
But how do we pick data using active learning if we don’t have a model at hand?
Active Learning without Predictions
Even if we don’t have predictions of a model there are techniques we can use. We can, for example, use embeddings to select a set of very diverse images. This approach is commonly used as diverse images can help to train more robust models.
The different areas of active learning are nicely summarized in the right column in the following illustration:
- Uncertainty Sampling is using model predictions
- Diversity Sampling can’t rely on any predictions (as the model does not know that it does not know)

Combining the Active Learning Approaches
Recent research papers started combining uncertainty and diversity sampling. The combination overcomes several limitations of the individual methods. For example, just using model uncertainty could result in oversampling a particular group of images. Including the diversity, aspect can ensure that we select data where the model has low confidence but at the same time the data is different from each other.
At Lightly we generalized and scaled that framework across different tasks with our Coral method. Coral stands for Corset and Active Learning.
Putting it all together
LightlyOne combines everything we just discussed before.
- We use embeddings obtained from self-supervised learning models to understand large-scale unlabeled datasets.
- We additionally can use existing model predictions and the latest active learning algorithms to select the most valuable batch of new data for labeling and training your models.
- All algorithms have been designed to scale to millions of images or thousands of videos. We optimized our code to the instruction level to squeeze out all the performance for you so you don’t have to worry about it.
- Our UI allows you to oversee the data you have and all the processes. It integrates with other tools and lets you collaborate across data operations and machine learning teams.
Interested in giving LightlyOne a try? Try it out for free!
Igor, co-founder
Lightly.ai
See Lightly in Action
Curate and label data, fine-tune foundation models — all in one platform.
Book a Demo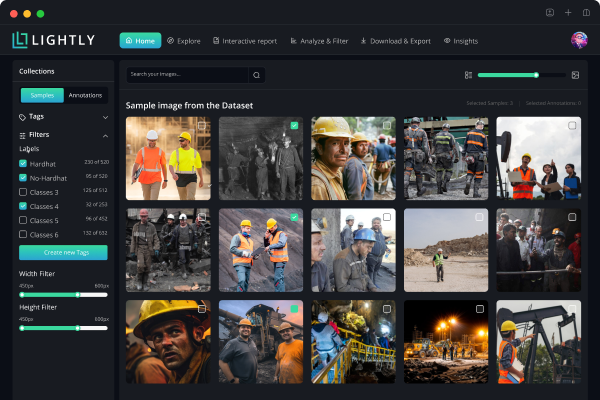

Stay ahead in computer vision
Get exclusive insights, tips, and updates from the Lightly.ai team.

.png)
.png)
.png)


