LightlyTrain 0.13.0: Expanded LTDETR with Tiny DINOv3 Object Detection Models
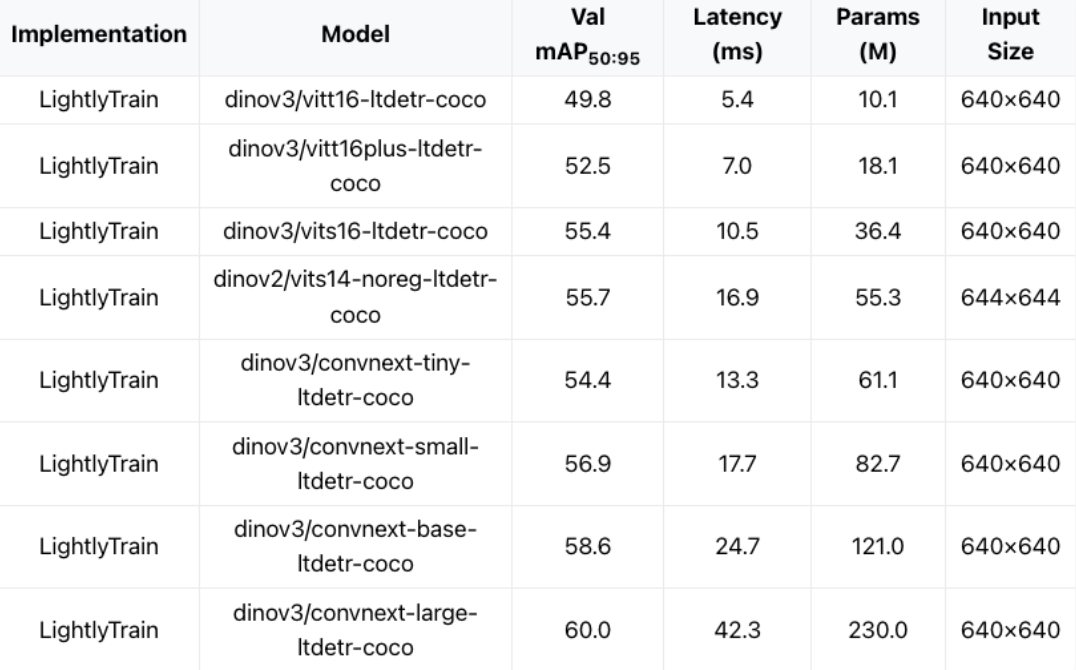
LightlyTrain 0.13.0 introduces tiny LTDETR object detection models distilled from DINOv3. With as few as 10M parameters, sub-10ms latency, and strong COCO performance, they enable fast training and real-time deployment on edge devices.
Get Started with Lightly
Talk to Lightly’s computer vision team about your use case.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
LightlyTrain 0.13.0 expands the LTDETR family with two new tiny object detection models. This release brings high-quality detection to setups where size, latency, and ease of use matter most. These models are designed for fast experimentation, simple fine-tuning, and smooth deployment to edge and real-time systems.
The two new LTDETR models are based on tiny vision transformer (vit) backbones that were distilled from DINOv3 with LightlyTrain.
The smaller vitt16 and slightly larger vitt16plus models have 10.1M and 18.1M parameters, making them ideal candidates for resource constrained devices. They achieve excellent performance on the COCO dataset with 49.8 and 52.5 mAP50-90, respectively. Their low latency of less than 10ms on a T4 GPU with FP16 at 640x640 input resolution makes them ideal options for real time applications.
Why Use Tiny LTDETR Models in LightlyTrain
Size and Speed: Model size and speed are optimized for real-time inference on resource constrained devices.
Simplicity: The models are extremely simple to train on new datasets and require only minimal fine-tuning thanks to the strong DINOv3 backbones and COCO pretraining.
ONNX Support: Easily export models to ONNX for deployment on edge devices.
Flexibility: With LightlyTrain, you can pretrain and fine-tune your model in a unified framework with minimal code.
Getting started with tiny LTDETR models only requires a few lines of code:
import lightly_train
if __name__ == "__main__":
# Train
lightly_train.train_object_detection(
out="out/my_experiment",
model="dinov3/vitt16-ltdetr-coco",
data={
"path": "base_path_to_your_dataset",
"train": "images/train",
"val": "images/val",
"names": {
0: "person",
1: "bicycle",
# ...
},
}
)
# Load model
model = lightly_train.load_model("out/my_experiment/exported_models/exported_last.pt")
# Or load one of the models provided by LightlyTrain:
# model = lightly_train.load_model("dinov3/vitt16-ltdetr-coco")
# Predict
results = model.predict("image.jpg")
# Export to ONNX
model.export_onnx("model.onnx")

.png)





.png)

.png)
.svg)


