
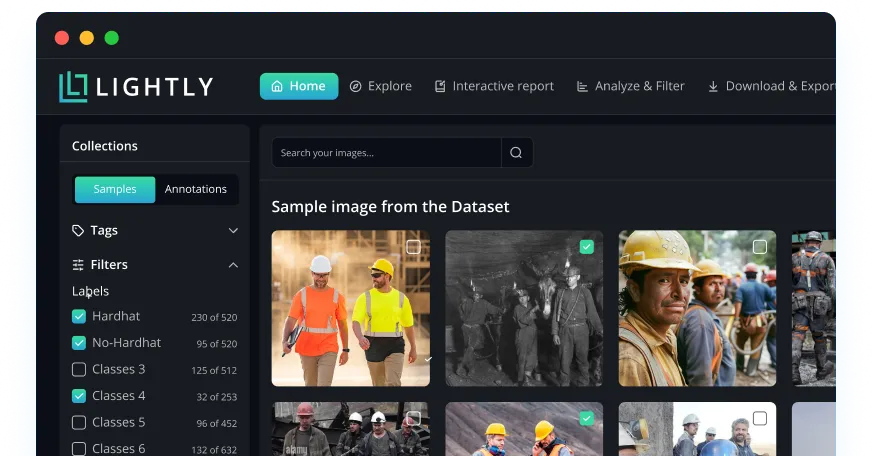
Curate, Annotate, and Manage Your Data in LightlyStudio.
One integrated computer vision platform for labeling, curation, QA, and datasets management. Open-source at its core, LightlyStudio is built for ML engineers and organizations scaling computer vision.
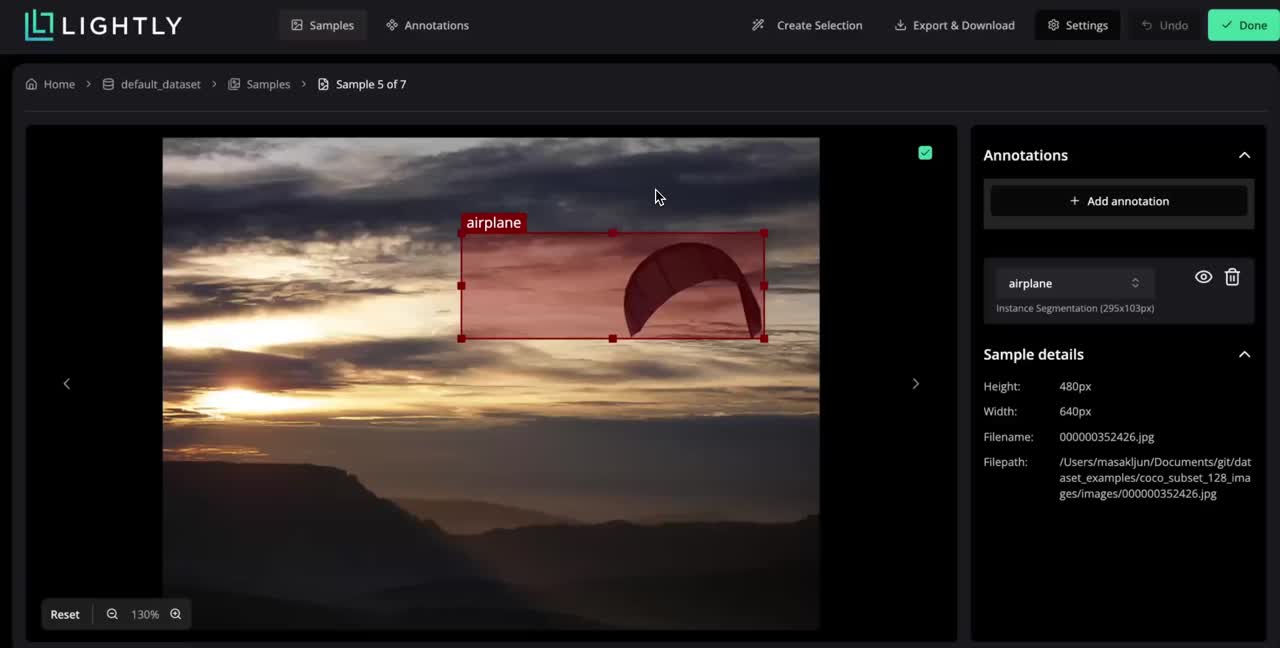
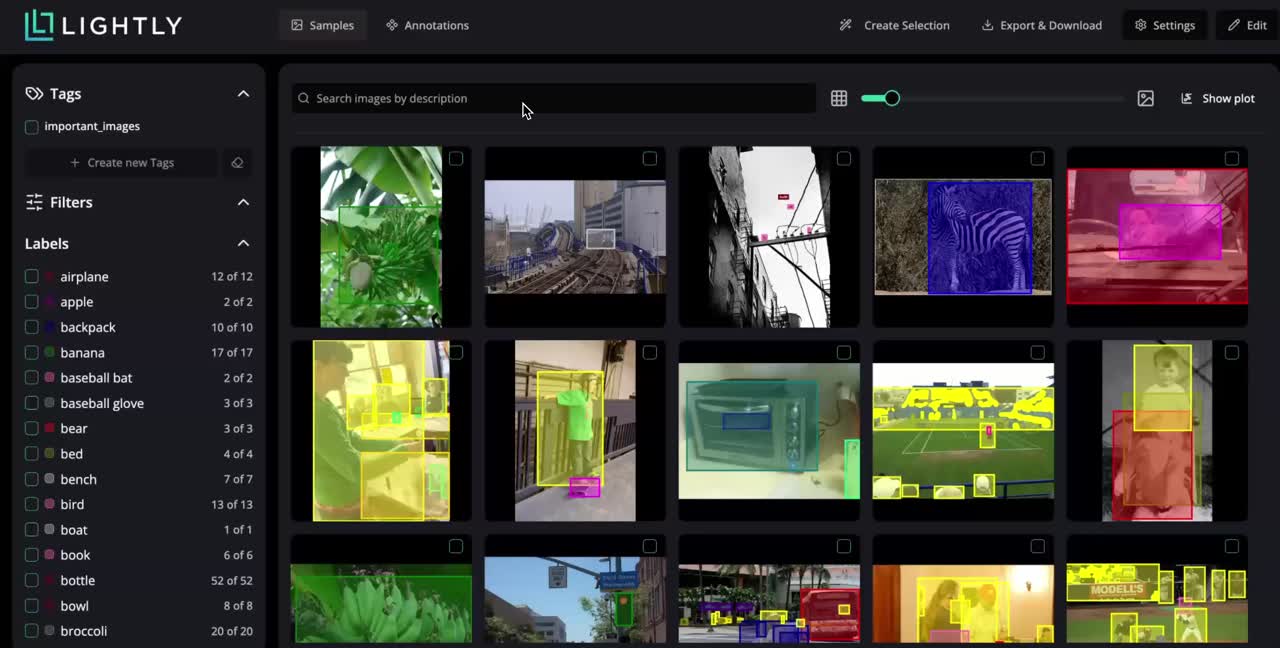
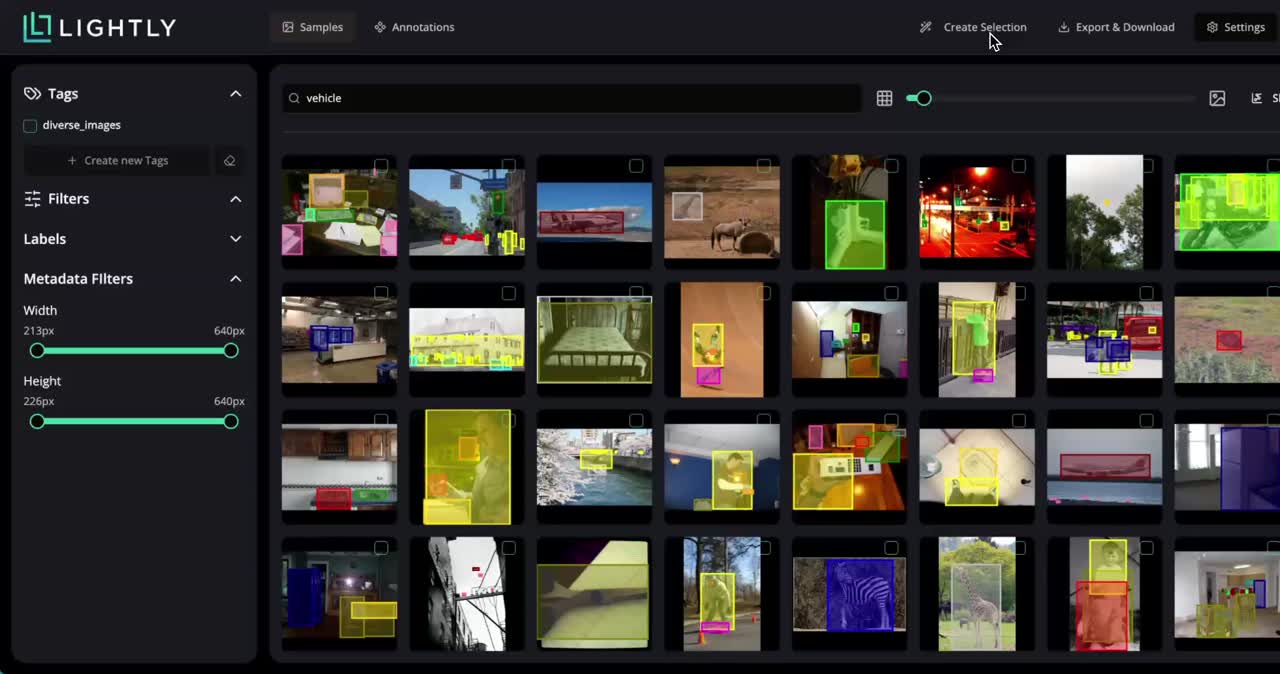
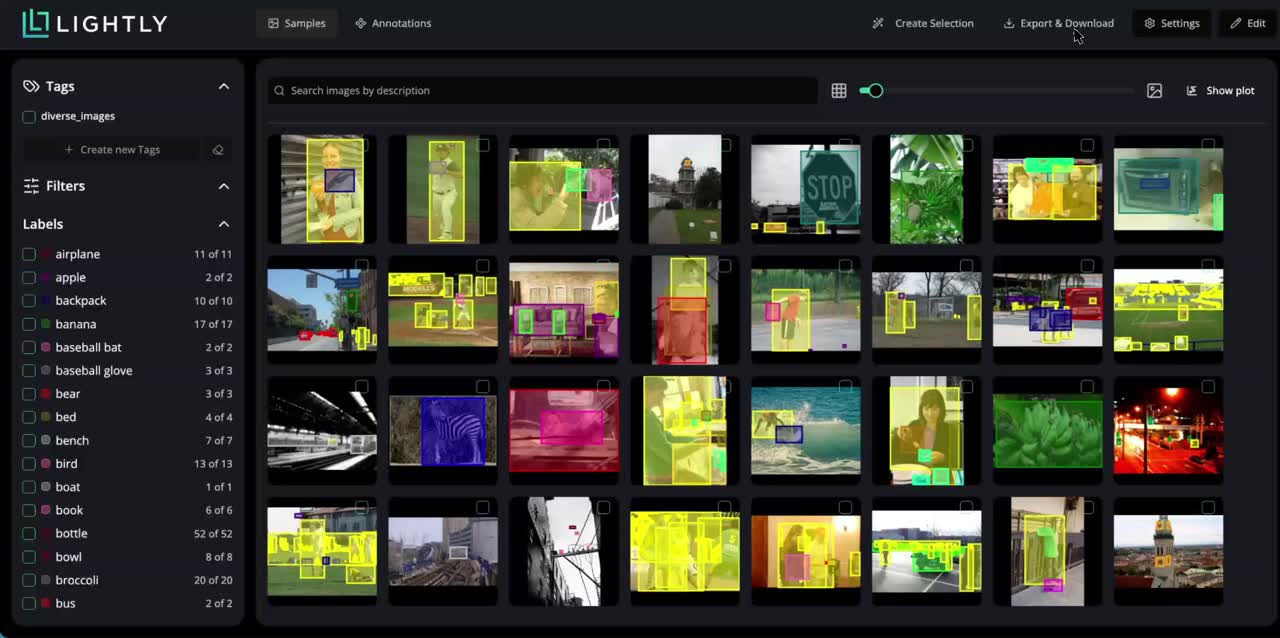
LightlyStudio supports image, video, audio, text and DICOM data.
Trusted by entreprises, researchers and startups.






One Platform. Two audiences.
LightlyStudio connects everyone working on your ML data pipeline - from ML engineers to labelers. Built for technical and non-technical users.
For ML Engineers
Integrate with your existing ML stack, access SDK and API support, and build on open-source standards designed for flexibility and scale.

For Labelers & Project Managers
Use intuitive labeling tools with role-based permissions, dataset versioning, and performance tracking to manage annotation workflows at scale.
We make it easy to migrate your data from Encord, Voxel51, Ultralytics, V7Labs, Roboflow, or other ML tools. Contact us to learn more.
LightlyStudio fits into your ML stack.
LightlyStudio is the central data hub for your computer vision workflows. Built for technical and non-technical users.
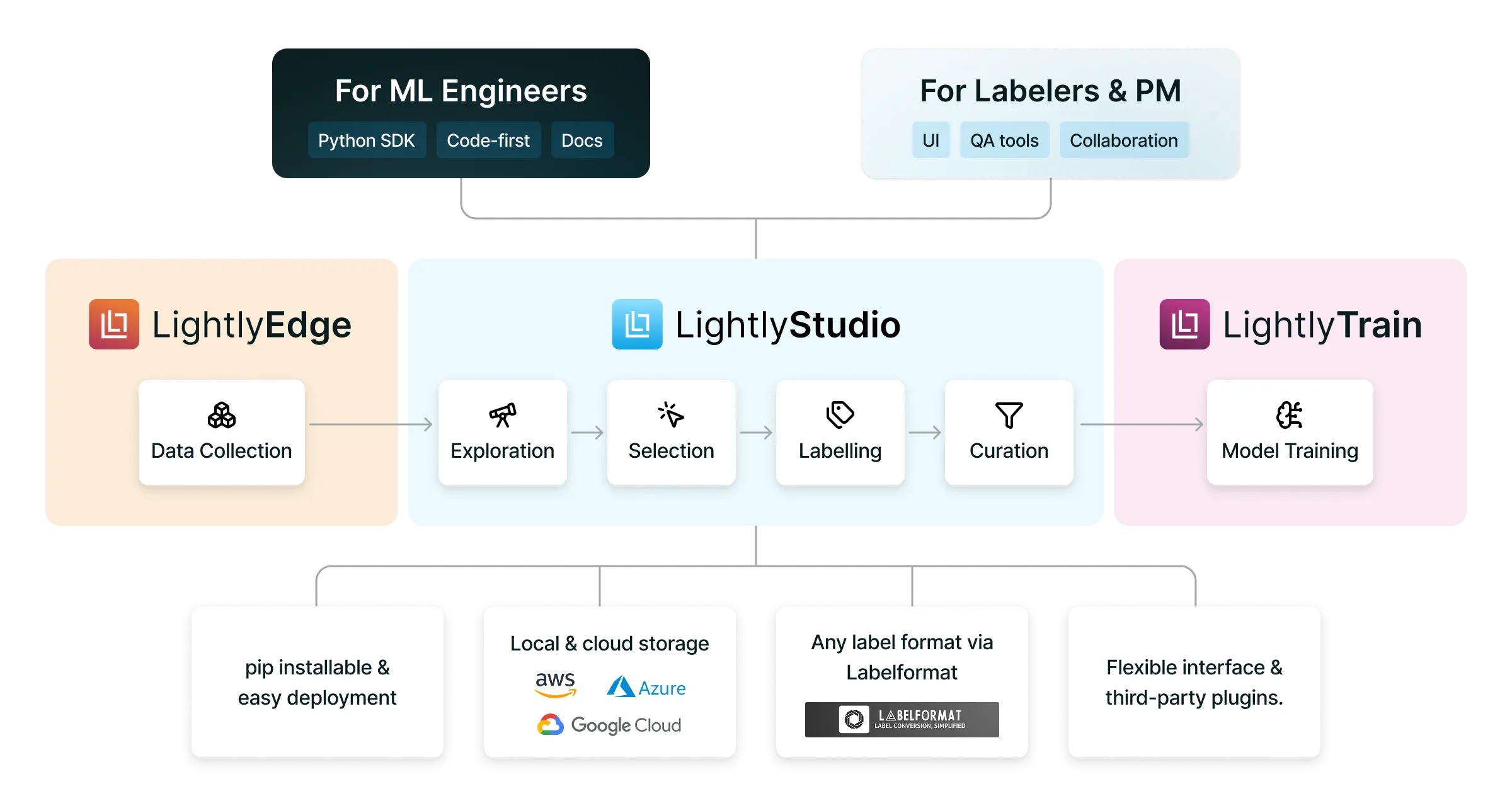
Pretrain & Fine-Tune Vision Models on Your Data with LightlyTrain
Connect LightlyStudio with LightlyTrain to pretrain, fine-tune and evaluate models using the most relevant samples from your datasets.

Open-source principles. Enterprise-grade security & scale.
Measurable impact on hundreds of ML teams around the world.













.svg)








Open-source principles. Enterprise-grade security & scale.
LightlyStudio meets enterprise-grade requirements for compliance, extensibility, and deployment flexibility.

ISO 27001 Certification
International standard for information security management systems
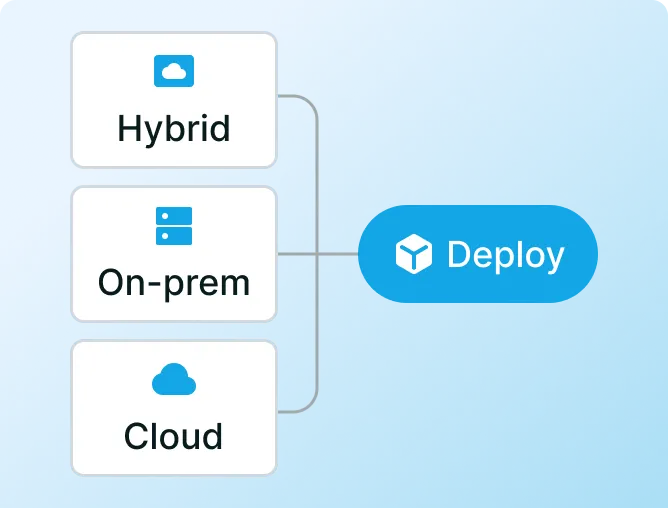
Deploy anywhere
Use your dataset to pretrain a model with just a few lines of code.

Available as Open-Source
A computer vision framework for self-supervised learning developed for research.
Ready to Get Started?
Join 100+ ML teams that have cut their training costs by more than 50% with Lightly products.
Book a Demo





