
Bias in Machine Learning
This blog post will give a high-level overview on the topic of bias in machine learning, a significant issue that can often be traced back to the data used to train an algorithm. I will discuss the different types of bias in machine learning, and how to identify and analyze it using different tools.
What is Machine Learning Bias?
In popular culture, it is often assumed that computers or technology should be considered the highest source of decision-making: that they are perfectly neutral, supremely rational, and even omniscient. In fact, there tends to be a certain trustworthiness around every decision that is made with “smart”, data-driven technology like machine learning. This assumption could not be further from the truth- as the engineers working on such technologies know well.
It all boils down to one main idea: algorithms are only as knowledgeable or neutral as the humans that develop them, and the data they are trained on. In fact, a “neutral” ML model is an almost outlandish idea, or at the very least, a challenge. Algorithms amplify the biases present in their training data. The unfortunate truth is that most often, these biases can not be identified until after the model is deployed and the bias has already gone from a potential challenge to a real issue.
As we integrate machine learning and data science into more and more facets of our lives–business, healthcare, industry, education and more– the issue of ML bias has become all the more pressing.
The phrase machine learning bias is used to describe what is happening when an over- or underrepresentation of certain data in a dataset produces a biased algorithm, which puts obvious and often problematic limitations on the algorithm.
The machine learning process, like any meticulous and detailed process, is prone to errors. Due to the causal nature of the steps in the process (data collection, data curation, labeling, training, and deployment), an error in one step tends to echo throughout the entire pipeline, with the consequences eventually being realized in the deployed model. Issues like bias can most often be assumed to be sourced from the datasets used for training and deployment of a model’s core algorithms.
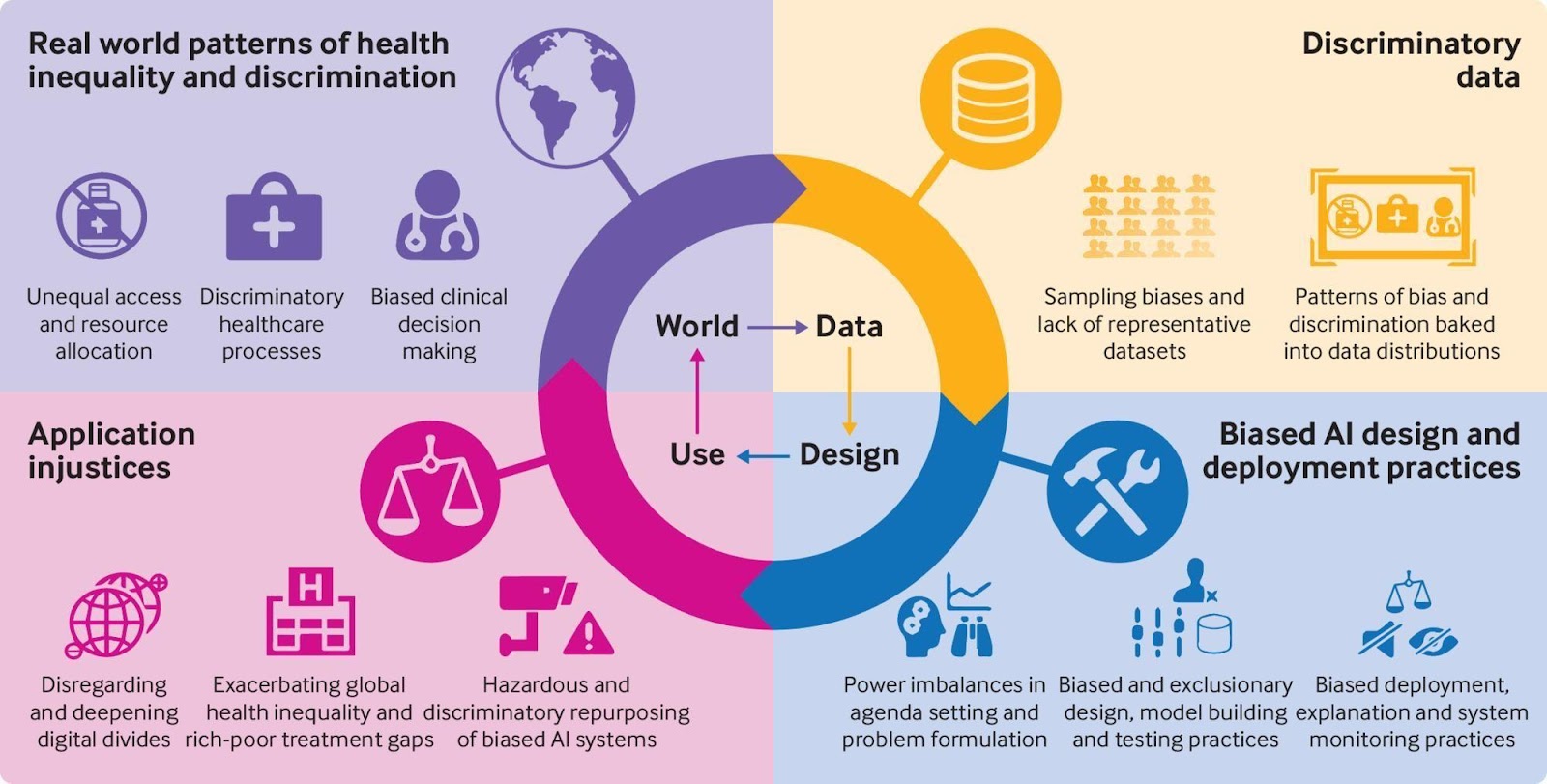
In figure 1, we see how uncareful data selection practices can have a profound domino effect throughout an entire system (for this example, the health sector). Without a properly representative dataset, and selection methods that account for diversity, the design and deployment of ML models have a high potential for showing biases. With ML being applied in some of the most important areas of our life, like in healthcare, this can create or support patterns of injustice within those systems.
The downstream consequences of ML bias can range anywhere from increased ML project overhead to deeper societal implications and systematic discrimination, like some of these well-known instances of biased ML in the news:
-Google Photos “gorilla” scandal: In 2015, Google Photos’ photo tagging algorithm misclassified a user’s selfie of him and his friend (both black) as being “Gorillas” (Figure 2).

-Google Translate sexism: Last year, a researcher from England found that Google Translate would automatically gender sentences translated from Hungarian (a gender neutral language) in a sexist way (see figure 3).

-COMPAS: This was a prediction algorithm developed by the company Equivant that was found to be racially biased, consistently predicting black people to have a higher risk of recidivism than white people.
-The arrest of Robert Williams: In 2020, Detroit police wrongfully arrested black man Robert Williams after their facial recognition algorithm determined that he was the crook in security footage of a man committing a robbery. Numerous studies have shown that many facial recognition algorithms misidentify people of color more often than white people.
What are different types of bias in machine learning?
That being said, there are many different types of bias that can occur in different scenarios and projects, and it’s important to understand where to look for each of them. Here are a few examples of some more prevalent biases that may find their way into your ML model.
Selection bias
This is a purely systematic issue. In this type of bias, the method used for data collection does not sample from the full population because, for example, there is a misconception about it. This occurs at the collection/cleaning stage of the ML pipeline. Models with selection bias can behave unpredictably when confronted with scenarios which are not included in their training data.
Algorithmic bias
This type of bias occurs at the algorithmic level, so it isn’t an issue with data. Instead, designing an algorithm that is incompatible with the application it is being developed for can lead to this issue. It is less common, however, for the core algorithm to be at fault than for the data to be at fault.
Exclusion bias
Exclusion bias results from exclusion of particular samples from your dataset that would otherwise have an important impact on the model. This exclusion can be systematic but it can also happen in cases of deleting value-adding data thought to be unimportant. For example, when randomly sampling videos, it can often happen that important or relevant frames are not included. Thus, those scenes are not represented in the model trained on those samples.
Representation Bias
A relatively unexplored area, representation bias is the problem posed by an algorithm leveraging certain representations without learning to solve the underlying task. It occurs when a model is trained on certain representations of a situation more than others. For example, autonomous driving data that represents more sunny days than rainy/dark days. This type of bias can be removed by oversampling scenarios which are underrepresented.
It’s obvious that bias should be promptly addressed if it comes up. But maybe we need to back up a little bit first. How can we detect and resolve it as early as possible in the pipeline?
How to detect and analyze bias
Detecting bias in your ML model can be done proactively or reactively, and depending on your specific case, either one is viable. Reactive bias detection happens organically, for example, if you notice that a certain group of inputs aren’t performing very well. An obvious conclusion from this is that you are potentially working with biased data.
Alternatively, you could build bias detection/analyzation steps directly into your model development workflow by using a tool, thus proactively searching for signs of bias and analyzing the result to gain a better understanding of them. Here are some common tools you can use for this purpose:
Google What-If
Google launched their What-If Tool in 2018 as a feature of the OS Tensorboard web app. The tool was built to allow engineers to visualize their dataset and manage it through the UI, as well as analyze the performance of their model, and assess algorithmic fairness across different subgroups. Supported data types are tabular, image, and text.
IBM AI Fairness 360
IBM’s open source AI Fairness 360 toolkit was built around the intention of examining and mitigating bias in machine learning models. Its 70 fairness metrics and 10 bias mitigation algorithms are designed and optimized to help ML teams not only detect bias but understand and remove it. It also gives users the ability to compare their model after applying bias mitigation algorithms to the original model, which is helpful for understanding common patterns of bias to be more prepared for them in the future.
FairML
FairML is a Python toolbox developed by Julius Adebayo for auditing black-box machine learning models for bias. It assesses the fairness or discriminatory extent of a model by quantifying the relative significance of a model’s input.
Lightly
Lightly is a data curation solution for machine learning. Its solution makes use of representation learning through self-supervised methods to understand raw data, enabling users to find and remove redundancy and bias introduced by the data collection process to reduce overfitting and improve ML model generalization. The principle behind Lightly is to help engineers understand their data more deeply, leading them to also understand their models more deeply (including the conclusions those models make). Supported data types are image and video.
How to remove dataset bias
For many ML teams, eliminating bias from a dataset often means collecting more data. With more data, the chances that more of the domain you’re attempting to represent will successfully be represented increases. While this is true to an extent, simply collecting more data ultimately creates more overhead, costs more money, and even produces more Co2.
That’s why using a tool like Lightly can be so valuable for engineers wanting to tackle bias in machine learning. It does two very important things regarding this issue:
- Eliminates the need to collect more data to improve your dataset
- Helps to intelligently collect new, unbiased data
Building off of that vision, a valuable feature of the solution is the ability to balance datasets based on predictions of models and metadata which should counteract dataset bias.
Conclusion
Because it is so difficult (sometimes impossible) to deeply analyze how machine learning models reach particular conclusions, avoiding model bias will remain a lingering problem in ML. Until black box models are removed from the picture entirely, there can always be room for doubt regarding how your model came to the conclusion it made about particular data.
That’s why tools that help to identify, analyze, and remove bias are so important to ensure the integrity of your ML models.
As always, if you find yourself wanting to start a conversation about data-centric AI or what Lightly’s solution can do for your ML team, feel free to reach out here.
.png)


.png)